Adcash - 1 Trillion HTTP Requests Per Month
This is a guest post by Arnaud Granal, CTO at Adcash.
Adcash is a worldwide advertising platform. It belongs to a category called DSP (demand-side platform). A DSP is a platform where anyone can buy traffic from many different adnetworks.
The advertising ecosystem is very fragmented behind the two leaders (Google and Facebook) and DSPs help to solve this fragmentation problem.
If you want to run a campaign across 50 adnetworks, then you can imagine the hassle to do it on each adnetwork (different targetings, minimum to spend, quality issues, etc). What we do, is consolidate the ad inventory of the internet in one place and expose it through a self-service unified interface.
We are a technology provider; if you want to buy native advertisement, if you want to buy popups, if you want to buy banners, then it is your choice. The platform is free to use, we take a % on the success.
A platform like Adcash has to run on a very lean budget, you do not earn big money, you get micro-cents per transaction. It is not unusual to earn less than 0.0001 USD per impression.
Oh, by the way, we have 100 ms to take a decision.
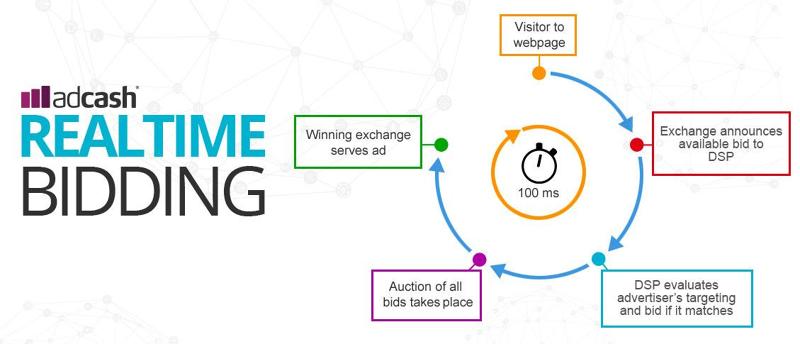
In Numbers
- Over 1 trillion (1 000 000 000 000+) HTTP requests per month
- 1 PB Hadoop cluster
- 500,000 rq/second
- 1500 servers
Our tech stack evolved a lot during the time, we try to keep our architecture modern. One internal joke is that our stack is not just cutting-edge but bleeding-edge. Eventually, with time, what was bleeding-edge yesterday is now simply modern or disappeared from our stack (like Gearman).
When we started using Redis or even nginx, there was clear lack of consensus. The same for databases like Druid or TokuDB (an alternative storage engine for MySQL) where we had been early adopter.
If you haven’t heard of Druid before, it is an equivalent to OpenTSDB, just very much optimized for OLAP queries. It is reasonably popular in the Adtech ecosystem (like kdb+ for HFT-folks).
We Follow Two Main Precepts
- Keep it simple, stupid
- Unix philosophy.
This translates into different choices but in majority:
- Release early, release often
- If ain't broke don't fix it
- Each service has to do one thing, and do it well
What Adcash is Using Today
- Languages: PHP7, Hack, Lua (core adserving), Scala, Java (core prediction), Go
- Database (operations): MariaDB, Druid, Redis
- Database (machine learning): Hadoop, Hbase, Spark MLLIB
- Data pipe: Apache Kafka
- Log collection: Elasticsearch, Kibana, Logstash
- Charting: Grafana
- Server: Openresty (nginx)
- Hosting: Google Cloud, Bare metal provider
- Javascript UI Library: Angular, React (new projects)
- Productivity suite: Google Apps
- Project management: Jira and Confluence
- Transactional email: Amazon SES
- Promotional email: Mailchimp
- CRM: Zoho
- Code collaboration and version control: Gitlab
- Continuous integration and task scheduling: Jenkins
- Communication: Slack, Skype
- Server management: Ansible
- Operating system: Ubuntu and Debian, CoreOS for Kubernetes deployments
We are very heavy users of Jenkins, we can fix pretty much anything from the UI.
As costs are an important part of our model, anyone in the company (including non-developers) can follow on TV screens the real-time traffic and spendings of the platform.
It took almost 5 years to arrive to our current stack and we are very happy with it.
This is How We Came to our Solution (including dark sides)
In 2007, at the very beginning Adcash was running on a single Pentium IV and using the following services:
Apache 1.3, mod_php, MySQL 5
The concept was simple, give a link and a banner to the webmaster, record the number of clicks, and the number of people who registered on the offer.
Pay the webmaster a fixed commission for each registration.
The Architecture was the Following
Backoffice/MySQL/Web01
|
Visitor
Pretty simple right? Everything was centralized on one machine, and backoffice was just a directory (/admin) where you could run a few commands to validate or reject websites.
We didn’t plan for any scale, the important was to move fast and implement features to meet what our customers want. Building a MVP in its pure aspect.
Adcash was owner of the machine (we got the machine for free!, just paying for electricity) and was renting space in a datacenter in Clichy (France).
This datacenter had a very unreliable power source and we often had to go to Clichy to fix broken PSUs but the onsite engineer was awesome.
This machine became limited so we found a couple of Pentium IV machines that were abandoned by their owners and we took the first machine and promoted it to become MySQL + NFS server.
Single Point of Failure
What will prevent you to sleep, to have vacation, to have a girlfriend, to have a family or to live more than 5 meters away from a reliable internet connection
Using NFS was a big mistake (we later replaced it with lsyncd/unison). Using a central MySQL server was a big mistake, that being said, it allowed us to move fast.
Technical debt is a loan, you need to pay it back someday. Some debt are useful for growing as it is a powerful leverage, but you need to handle it carefully.
Making wrong choices is expensive (pick the default latin1 in MySQL, and years later, you will hate yourself), and sometimes, you actually benefit from it (do not over-engineer).
Note that Galera didn’t exist at this time, MySQL replication was tough to get right. The state of the art used to be an active/passive setup using DRBD (hard-drive replication) with Heartbeat. Every single DDL statement was triggering (!) an intense sweat (no matter how "online" the ALTER TABLE is supposed to be).
At this Stage We had the Following Setup
MySQL/NFS
|
Web01, Web02, Web03, Web04, Web05, Web06, Web07, Web08, Web09
\______\______\______\______|_____/______/______/______/
|
Visitor
In this architecture, it was very difficult to add new servers, since we had to order them at Dell long time in advance, send an engineer in the Datacenter. He would take his car, and go to fix the server. If there was no hardware piece, well, too bad.
This was also an expensive operation since we had to pay for all hardware upfront.
We had no money for servers, money was used to pay for traffic. Whatever remains goes into the servers, no salaries.
Pingdom was too expensive, so we ended up with living with a web page that pretty much looked like this:
<?php$clients = @file_get_contents('http://srv231.adcash.com:8080/check-load'); if ($clients >= 90) {?> // http://www-mmsp.ece.mcgill.ca/Documents/AudioFormats/WAVE/WAVE.html s = 'RIFF' + mk_le_bs(4 + 90 + (8 + 1 * 1 * data.length + pad.length), 4) + 'WAVE' + 'fmt ' + mk_le_bs(16, 4) + mk_le_bs(WAVE_FORMAT_PCM, 2) + mk_le_bs(1, 2) + mk_le_bs(sample_rate, 4) + mk_le_bs(sample_rate * 1 * 1, 4) + mk_le_bs(1 * 1, 2) + mk_le_bs(8 * 1, 2) + 'data' + mk_le_bs(1 * 1 * data.length, 4) ; bs = []; for (var idx=0; idx<s.length; idx++) { bs.push(s.charCodeAt(idx)); } bs = bs.concat(data); if (pad.length > 0) bs.push(0x00); s = 'data:audio/wav;base64,' + base64_encoder(bs); var audio = new Audio(s); audio.play(); You had to keep this page open all the time. Anywhere, on your phone, on the computer, on the tablet.Everytime one server crashed, the javascript on the page was triggering a very annoying and loud sound.
Nothing better than a perfect A at 440Hz to give you nightmares.
We needed more scale, AWS was prohibitive so we decided to go and try a very popular bare metal hosting provider because we needed to scale-up our infrastructure due to big waves of traffic coming in.
Despite the good reputation of this hosting company (probably one of the biggest provider in Europe), we have discovered that the company provided servers with extremely poor networking quality.
The Infrastructure Was the Following
Datacenter A Datacenter B
mysql replication
MySQL/NFS <---------------------------------------------------> MySQL/NFS
| |
Web01, Web02, Web03, Web04, Web05, Web06, Web07, Web08, Web09 Web01 Web02 Web03
\______\______\______\______|_____/______/______/______/________/_____/_______/
|
Visitor (routed to datacenter A or datacenter B based on round-robin DNS)
As you can guess, at this stage we had everything running on “Web” servers (generic application servers). This meant, Apache, PHP, MySQL slave, Memcache, some basic machine learning and anything that was needed.
So We Expanded Again
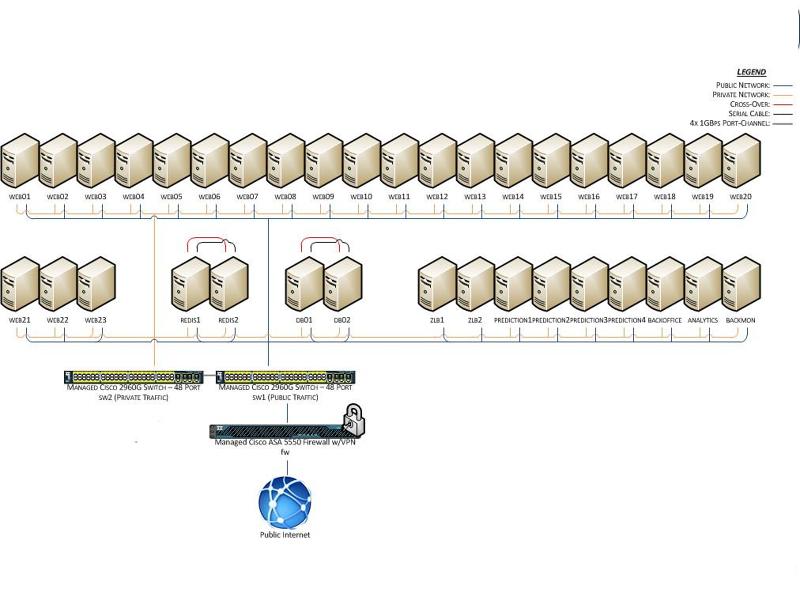
Nice, until 23 October 2012. Do you remember I mentioned we were using DRBD (Distributed Replicated Block Device) for databases ? All data disappeared. Several dozens of terabytes.
The hosting provider made a mistake (damn serial cable!). Triggered double-failover and accidentally corrupted databases disks.
We got compensated a lot of money which was not that bad, considering that we managed to restore everything from backups and that there was barely no impact for customers.
We had only a few physical machines (for costs reasons) but we needed to start splitting the different services. We went with OpenVZ, and later LXC. This was terrible, it worked, but terrible. Docker didn’t exist.
At least, we did not have this issue of dealing with failing hardware anymore and we could finally run Hadoop and PHP on the same machine with a decent resource isolation.
Still, we did not have enough ports on the physical switches and had a pending order of 40 nodes, so we had to decommission and reuse one of the switch. After that, it became clear that we didn’t have space to grow and it was time to move on.
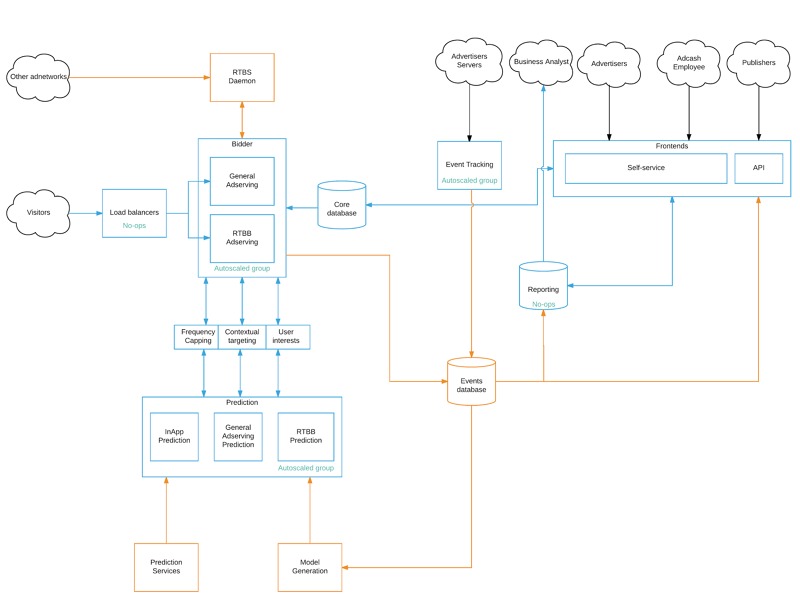
We Rewrote the Full Architecture Following a New Logical Schema
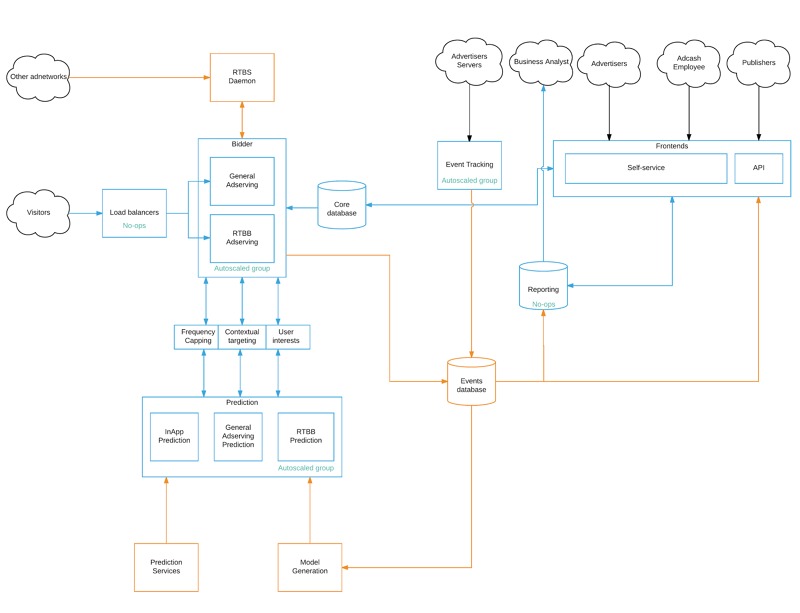
We finally moved to Google Cloud, totally abstracting any hardware concern and we have a perfect service isolation.
It works and for us, a very important point is that all systems are auto-scaled. If there is 100,000 requests per second or 500,000 requests per second, we barely see the difference (except on the bill).
All RPC/IPC is happening via our unified messaging system, based on Redis.
RPC communication is clear-text, we stay away from binary serialization protocols whenever possible as we favor debuggability.
Fortunately, the code base in Adcash is very little interdependent. One service is doing one thing.
Similar to what happened with Gitlab, one developer accidentally dropped the main production application. Was it avoidable ? Probably. Was it an issue ? Not really.
The important is to set the correct environment so you can recover when a bad event happen. Having good deployment tooling is key in this situation. We are using Combo (the name is from Street Fighter), an in-house equivalent to Terraform.
Lessons Learned
If it can fail, it will fail; if it’s not a datacenter flooding, an electrical failure, an hurricane, a farmer that cuts your fiber optic line, something bad will happen.
The result really matters. If you have spent 20 hours engineering a solution, and at the end of the 20 hours process you discovered that a simple 5 minute trick works better, take it.
Use active-active replication, active-passive requires more attention and will likely not work when needed.
Keep your services independant.
Do not test if backup is working, test if restore is working.
Because we are so used to our own solutions, if you are keen on sharing your experience and (open-source) solutions, feel free to have a chat with our team.Overall, we are very happy of the current platform; and have many ideas to improve it. If you want to join us in the adventure, you can check our open positions. We usually have a few machine learning challenges as well.



{kind=link}
{kind=link}