Neo4j - a Graph Database that Kicks Buttox
Update: Social networks in the database: using a graph database. A nice post on representing, traversing, and performing other common social network operations using a graph database.
If you are Digg or LinkedIn you can build your own speedy graph database to represent your complex social network relationships. For those of more modest means Neo4j, a graph database, is a good alternative.
A graph is a collection nodes (things) and edges (relationships) that connect pairs of nodes. Slap properties (key-value pairs) on nodes and relationships and you have a surprisingly powerful way to represent most anything you can think of. In a graph database "relationships are first-class citizens. They connect two nodes and both nodes and relationships can hold an arbitrary amount of key-value pairs. So you can look at a graph database as a key-value store, with full support for relationships."
A graph looks something like: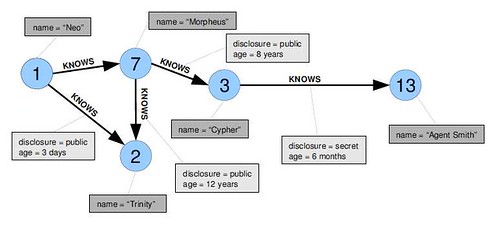
For more lovely examples take a look at the Graph Image Gallery.
Here's a good summary by Emil Eifrem, founder of the Neo4j, making the case for why graph databases rule:
Most applications today handle data that is deeply associative, i.e. structured as graphs (networks). The most obvious example of this is social networking sites, but even tagging systems, content management systems and wikis deal with inherently hierarchical or graph-shaped data.
This turns out to be a problem because it’s difficult to deal with recursive data structures in traditional relational databases. In essence, each traversal along a link in a graph is a join, and joins are known to be very expensive. Furthermore, with user-driven content, it is difficult to pre-conceive the exact schema of the data that will be handled. Unfortunately, the relational model requires upfront schemas and makes it difficult to fit this more dynamic and ad-hoc data.
A graph database uses nodes, relationships between nodes and key-value properties instead of tables to represent information. This model is typically substantially faster for associative data sets and uses a schema-less, bottoms-up model that is ideal for capturing ad-hoc and rapidly changing data.
So relational database can't handle complex relationships. Graph systems are opaque, unmaintainable, and inflexible. OO databases loose flexibility by combining logic and data. Key-value stores require the programmer to maintain all relationships. There, everybody sucks :-)
Neo4j's Key Characteristics
Neo4j vs Hadoop
This post makes an illuminating comparison between Neo4j vs Hadoop:
In principle, Hadoop and other Key-Value stores are mostly concerned with relatively flat data structures. That is, they are extremely fast and scalable regarding retrieval of simple objects, like values, documents or even objects.
However, if you want to do deeper traversal of e.g. a graph, you will have to retrieve the nodes for every traversal step (very fast) and then match them yourself in some manner (e.g. in Java or so) - slow.
Neo4j in contrast is build around the concept of "deep" data structures. This gives you almost unlimited flexibility regarding the layout of your data and domain object graph and very fast deep
traversals (hops over several nodes) since they are handled natively by the Neo4j engine down to the storage layer and not your client code. The drawback is that for huge data amounts (>1Billion nodes) the clustering and partitioning of the graph becomes non-trivial, which is one of the areas we are working on.
Then of course there are differences in the transaction models, consistency and others, but I hope this gives you a very short philosophical answer :)
It would have never occurred to me to compare the two, but the comparison shows why we need multiple complementary views of data. Hadoop scales the data grid and the compute grid and is more flexible in how data are queried and combined. Neo4j has far lower latencies for complex navigation problems. It's not a zero-sum game.



