Applications Become Black Boxes Using Markets to Scale and Control Costs


This is an excerpt from my article Building Super Scalable Systems: Blade Runner Meets Autonomic Computing in the Ambient Cloud.
We tend to think compute of resources as residing primarily in datacenters. Given the fast pace of innovation we will likely see compute resources become pervasive. Some will reside in datacenters, but compute resources can be anywhere, not just in the datacenter, we'll actually see the bulk of compute resources live outside of datacenters in the future.
Given the diversity of compute resources it's reasonable to assume they won't be homogeneous or conform to a standard API. They will specialize by service. Programmers will have to use those specialized service interfaces to build applications that are adaptive enough to take advantage of whatever leverage they can find, whenever and wherever they can find it. Once found the application will have to reorganize on the fly to use whatever new resources it has found and let go of whatever resources it doesn't have access to anymore.
If, for example, high security is required for a certain operation then that computation will need to flow to a specialized security cloud. If memory has gone on auction and a good deal was negotiated then the software will have to adapt to take advantage. If the application has a large computation it needs to carry out then it will need to find and make use of the cheapest CPU units it can find at that time. If the latency on certain network routes has reached a threshold the the application must reconfigure itself to use a more reliable, lower latency setup. If a new cheap storage cloud has come on line then the calculation will need to be made if it's worth redirecting new storage to that site. If a new calendar service offers an advantage then move over to that. If a new Smart Meter service promises to be a little smarter then go with the higher IQ. If a new Personal Car Navigation Service offers better, safer routes for less money then redirect. And so on.
In short, it's a market driven approach, mediated by service APIs, controlled by applications. Currently this is not how the world works at all. Currently applications resemble a top down hierarchically driven economy. Applications are built for a specific environment: platform, infrastructure, network, APIs, management, upgrade, job scheduling, queuing, backup, high availability, monitoring, billing, etc. Moving an application outside that relatively fixed relationship is very difficult and rarely done. For that reason talking about more fluid applications may seem a bit like crazy talk.
There are two driving forces that may make this idea approach sanity: scale and cost. Unifying these forces is the carefully chosen word "economy" used in the previous paragraph.
A line of thought I first began to consider seriously in the article Cloud Programming Directly Feeds Cost Allocation Back into Software Design, is that applications are now in the very beginning stages of becoming rational actors in an economy and a polity. The motivation for this evolution are related to scale and cost.
In the past applications were designed to make use of fixed cost resources (racks, servers, SANs, switches, energy etc) that were incrementally increased in largish allotments acquired through an onerous management processes. You capacity planned, bought resources, installed them, and that was that until you needed more. During the design phase the cost per operation wasn't a consideration because the resource pool was fixed. All that was needed was an architecture that scaled enough to meet requirements.
Opportunities for Loss in Algorithm Choices
This quaint and anachronistic static view of the world changes completely under cloud computing because of one innovation: variable cost usage-based pricing. In the cloud you pay for resources in proportion to how much you use them. Fixed cost assumptions and approaches no longer apply. The implications of this change are subtle and far reaching
Three types of cost overruns are common in the cloud: spikes, free riders, and algorithm choice.
- Spikes. If your site experiences an extinction level event, like getting a link on the front page of Yahoo, then you will have to pay for that instantaneous traffic surge. You pay even if you didn't want it, even if it doesn't bring in any revenue. A DDoS attack no longer has to bring your site down by making it too busy to handle legitimate traffic, all an attack has to do in the cloud is deplete your budget and you are undone. In the fixed cost scenario your site would crash, but your budget would be spared.
- Free riders. The spike problem is easy enough to understand, but the free rider, death by a thousand cuts problem is less obvious. Web sites often give free accounts in order to attract users, hoping to convert them to paid users later. These free users cost because they use resources in the cloud. Your seed money could sprinkled all over a lot of free user accounts and if not enough account germinate, then you'll go hungry.
- Algorithm choice. Everything costs, but not everything costs equally. Let's say your brilliant implementation idea for faster access trades disk space for CPU by using multiple indexes on a record. As the user data grows you notice an enormous increase in disk space usage because your platform vendor uses a lot more disk per index than expected and for ease of implementation reasons you ended up using more indexes than expected. In this scenario your budget may evaporate under a laser hot heat based on this one innocent design decision. Similar games can played for any other resource in question. Every algorithm and architecture decision opens your project up for failure by an unexpected black swan event.
Opportunities for Profit in Algorithm Choices
Programmers have barely begun to grok the incredible financial impact their architecture and algorithm choices will have both on managing black swans and maximizing profit.
The flip side of the unexpectedly high cost problem is the opportunity to increase profit by creating algorithms that minimize cost, time, etc. If energy costs become a large part of algorithms in the future, for example, then you may be able to make a lot of money by creating a clever algorithm that uses less energy and exploits lower energy resources. It's a totally different game now.
One way to play the game is to pick a platform, stick with it, and figure out how to make it work. On Amazon, for example, one design rule is to favor CPU heavy algorithms as CPU in EC2 is relatively cheap. This approach won't work at all on Google App Engine because you are limited to 30 seconds of CPU processing at a time. Every platform will have idiosyncrasies like these, once you get used to them you can generally build what you need to build, although often with considerable pain.
The Rise of Ambient Cloud Enabled Markets
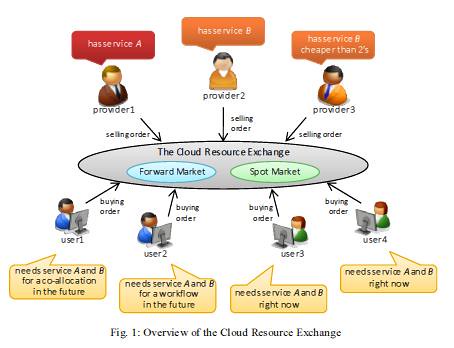
This image shows what a compute resource market might look like. It is taken from Market-based Resource Allocation for Distributed Computing.
The "pick a platform" play is really the only super scaling strategy there is at the moment. We are, however, starting to see multiple cloud options, we are starting to see multiple SaaS offerings for services like cloud storage, and we are still in just the very earliest stages of the Ambient Cloud. A rich and varied supply of compute resources on which to base a market is still in the future, but it is under construction.
The demand is there. The reason is the relationship between scale and cost. To see why consider the plight of the poor programmer. For our hypothetical planet-scaling application, where are they going to get the resources from? Amazon, Facebook, Microsoft and Google will most likely have the resources, but at what cost? I assume like at present web applications will be low margin affairs, as most of us will be trying to hack together an acceptable living as homesteaders on the edges of the digital frontier. Developers will simply will not be able to afford resources from a tier1 supplier.
This is where the Ambient Cloud steps in as a shadowy bazaar-like resource market. A place where spare memory, CPU, and other goodies can be given away, sold, rented, or exchanged, like on eBay or at a garage sale. We already see this spirit in the Open Source world, charity efforts like Good Will, the explosion of different lending libraries, cooperative projects like SETI, the microlending movement, and the expansion of local currency efforts.
Each of us will have a surprisingly large pool of resources to put into the market: smart phones, smart houses, smart appliances, smart cars, smart prosthetics, PCs, laptops, energy, and so on. Step up a level and companies will have smart buildings, smart fleets, smart networks, smart sensors, datacenters, and so on to contribute into the pool. Step up another level and organizations and governments will be able to contribute smart grids, smart buildings, datacenters, and so on.
Given the size of our individual resource pools, basing a market system on both barter and money makes a lot of sense. Contributing X units of resources (CPU, memory, etc) to the Ambient Cloud would entitle you to Y units of resources on the Ambient Cloud. There's still plenty of room for specialty clouds, like say for low latency data grids. The advantage of such a wide spread resource pooling is that it will build a very resilient community. There will be no centralized point of attack or way to bring the whole system down.
We'll go into more detail on the amount of resources that could be available later, but consider in 5 years some estimate smart phones will have one petabyte of storage, which can store something like 3 billion photos. By 2020 it's estimated there 50 billion devices on the internet. It's also projected that the smart grid could be 1,000 times larger than the internet. And the rate of change in resource availability will be exponential. The amount of memory and CPU available will be staggering and increasing exponentially. Bandwidth on the other hand will not follow this same growth curve, but it's not clear if that will be sufficient to ruin the party.
We've established both supply and a demand. Pervasive compute resource pools make up the supply. Programmers implementing applications make up the demand. In a typical market economy resources flow to the better deal. Clearly mechanisms will need to put in place to make and manage markets, something far beyond the current here's our API please code to it approach.
We see markets at work today with algorithmic trading in electronic financial markets. It appears no human even understands how these things work, yet they command huge portions of the economy. Go figure. The Financial Information eXchange (FIX) protocol is the messaging standard used to facilitate real-time electronic exchange. Something similar needs to work in the Ambient Cloud.
A major development helping legitimize this approach has been Amazon's introduction of a bidding system for EC2 Spot Instances. The logical implication is to extend this same mechanism everywhere to every type of resource.
This idea actually revolutionizes how applications function in a way similar to how electronic trading revolutionized the trading floor. Humans don't process trades anymore and they are even being squeezed out of even deciding what to trade. That responsibility has been shifted to a black box stuffed with trading models.
Similarly, applications will need to be black-boxed, parameterized, made to process trading information, make decisions, and automatically make trades in the application's architecture. Currently applications hardwire everything in advance. We know exactly how we'll cache records, store largish things, send email, store structured things, etc and the application directly reflects those choices.
Let's say a new specialized memory based cloud just came on-line, it is offering a promotional deal, 25% off for 10TB of replicated memcached storage. Our black box detects the deal, determines it saves us money, that it meets reliability parameters, and offers us even better geographic diversity in a region in which we are under served. The application executes a binding contract and then starts using this service for new data and moves old data over on a scheduled basis.
It's not difficult to think how such a maneuver could save hundreds of thousands of dollars and it all happened without human intervention. It will have to happen without human meddling for the same reason financial markets have done away with humans, we are too slow and too dumb to handle markets that move in fast and mysterious ways. Arbitrage is a game for the quick.
With a little imagination it's possible to see how this same process can work at every level of an application. A intermediary infrastructure service, for example, may aggregate memory from 100 million smart phones and make it available for object storage that will allow a 7 billion person friend list to be stored. A smart grid rents their backend sensor cluster for a map-reduce job that works very well on underpowered CPUs. A queue service offers a good price for reliable low latency queuing so some of your queue load is offloaded to that service. A new key-value service looks promising so you throw some traffic that way as a sort of service A/B test. A new MRI evaluation service opens in India and wins 10% of the business for your Offline Patient Data Mining service. Amazon Turk won a bid to tag a million pictures. The possibilities are endless.
Make no mistake, Google is following a similar strategy with their own infrastructure and with their own applications, they will just own all the parts end-to-end. The system Google is building is called Spanner. Spanner's goal is to support 10 million servers, 1013 directories, 1018 bytes of storage, spread across 100s to 1000s of locations around the world surviving 109 client machines. Those are staggering, staggering numbers.
It's not just the number that are staggering. What is also impressive is how Spanner plans to go about its business. Spanner will automatically and dynamically place data and computation across the world. It will try to minimize latency and/or cost given bandwidth, packet loss, power, resource usage, failure modes, and user defined goals.
If you are not Google, especially if you are not Google, where will all the money come from? Where will the technology come from? Where will the expertise come from? Technologically speaking this is a moon shot and Google seems to be one of the only ones in the space race.
Automated systems like Spanner are really the only way to handle the scale and complexity of planet-scaling applications. Humans gotta go. The difference is Google will rely on an internal planned economy instead of a public market based mechanism.
This isn't SkyNet or any other kind of AI gibberish. It's just code. Clever code certainly, but not take-over-the-planet-and-kill-all-the-humans type code. Models will need to be built that encode different architectural trade offs. Applications will need to built to respond to the output of the models. The models will need to consider factors like: APIs, cost, power, latency, size, access patterns, packet loss, security, bandwidth, geography, regulations, reliability, algorithms, available alternatives, and so on. Different, but nothing approaching sentience.
Some of this is old, old stuff. The idea of software based broker services has been around for quite a while. At one time the OSI stack was going to lead to automated broker services. Then it was the CORBA Interface Definition Language (IDL). Then it was the Web Interface Definition Language (WIDL).
All were based on the idea that if you completely defined software services then programs will dynamically look each other up and simply plug and play. It didn't quite work out the way. What was missing was a reason. There wasn't a viable market, only a mechanism. What is different now is that we'll have both supply and demand. Creating black box applications will actually make sense.
If you would like to read the rest of the article please take a look at Building Super Scalable Systems: Blade Runner Meets Autonomic Computing in the Ambient Cloud.



