Google Strategy: Tree Distribution of Requests and Responses

If a large number of leaf node machines send requests to a central root node then that root node can become overwhelmed:
- The CPU becomes a bottleneck, for either processing requests or sending replies, because it can't possibly deal with the flood of requests.
- The network interface becomes a bottleneck because a wide fan-in causes TCP drops and retransmissions, which causes latency. Then clients start retrying requests which quickly causes a spiral of death in an undisciplined system.
One solution to this problem is a strategy given by Dr. Jeff Dean, Head of Google's School of Infrastructure Wizardry, in this Stanford video presentation: Tree Distribution of Requests and Responses.
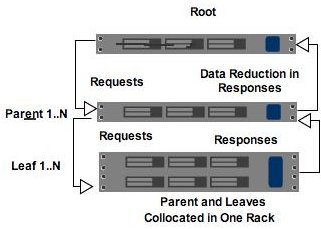
Instead of having a root node connected to leaves in a flat topology, the idea is to create a tree of nodes. So a root node talks to a number of parent nodes and the parent nodes talk to a number of leaf nodes. Requests are pushed down the tree through the parents and only hit a subset of the leaf nodes.
With this solution:
- Fan-in at each level of the tree is manageable. The CPU cost of processing requests and responses is spread out across all the parents, which reduces the CPU and network bottlenecks.
- Response filtering and data reduction. Ideally the parent can provide a level of response filtering so the root only sees a subset of the response data. This further reduces the network and CPU needed by the root.
- Collocation. The parent can be collocated with leaves on one rack, which keeps all that traffic off your datacenter networks.
In Google's search system, for example:
- Leaves generate their best 10 or 15 responses.
- Parents return the best 20-30 responses out of the 30 leaves the parent is responsible for.
- This is a large degree of data reduction compared to the case the root had to process all that data directly.



