Big Iron Returns with BigMemory

This is a guest post by Greg Luck Founder and CTO, Ehcache Terracotta Inc. Note: this article contains a bit too much of a product pitch, but the points are still generally valid and useful.
The legendary Moore’s Law, which states that the number of transistors that can be placed inexpensively on an integrated circuit doubles approximately every two years, has held true since 1965. It follows that integrated circuits will continue to get smaller, with chip fabrication currently at a minuscule 22nm process (1). Users of big iron hardware, or servers that are dense in terms of CPU power and memory capacity, benefit from this trend as their hardware becomes cheaper and more powerful over time. At some point soon, however, density limits imposed by quantum mechanics will preclude further density increases.
At the same time, low-cost commodity hardware influences enterprise architects to scale their applications horizontally, where processing is spread across clusters of low-cost commodity servers. These clusters present a new set of challenges for architects, such as tricky distributed computing problems, added complexity and increased management costs. However, users of big iron and commodity servers are on a collision course that’s just now becoming apparent.
Until recently, Moore’s Law resulted in faster CPUs, but physical constraints—heat dissipation, for example—and computer requirements force manufacturers to place multiple cores to single CPU wafers. Increases in memory, however, are unconstrained by this type of physical requirement. For instance, today you can purchase standard Von Neumann servers from Oracle, Dell and HP with up to 2TB of physical RAM and 64 cores. Servers with 32 cores and 512GB of RAM are certainly more typical, but it’s clear that today’s commodity servers are now “big iron” in their own right.
This trend begs the question: can you now avoid the complexity of scaling out over large clusters of computers, and instead do all your processing on a single, more powerful node? The answer, in theory, is “Yes”—until you take into account the problem with large amounts of memory in Java.
What’s So Great About Memory?
The short answer is speed. This is particularly apparent when you compare the speed of memory access to other forms of storage. This is also a growing problem as more and more organizations struggle with the issues around big data. Wikipedia defines big data as datasets that grow so large they become awkward to work with using traditional database storage and management tools.
For contrast, the following table shows the random access times for different storage technologies:
| Storage Technology | Latency |
| Registers | 1-3ns |
| CPU L1 Cache | 2-8ns |
| CPU L2 Cache | 5-12ns |
| Memory (RAM) | 10-60ns |
| High-speed network gear | 10,000-30,000ns |
| Solid State Disk (SSD) Drives | 70,000-120,000ns |
| Hard Disk Drives | 3,000,000-10,000,000ns |
Closer study of this table reveals a memory hierarchy, with the lowest latency at the top. When used properly, these technologies can solve the problems associated with big data. Since most enterprise applications tend to be I/O bound (i.e. they spend too much time waiting for data stored on disk), it follows that these applications would benefit greatly from the use of the lower-latency forms of storage at the top of this hierarchy. Specifically, today’s enterprise applications would speed up significantly without much modification if they could replace all disk access with memory usage.

To drive this point home further, note that with modern network technology, latencies are at worst around 10,000-30,000ns (2), with even lower latencies and higher speeds possible. This means that with the right equipment, accessing memory on other servers over the network is still much faster than reading from a local hard disk drive. All of this proves that as an enterprise architect or developer, your goal should be to use as much memory as possible in your applications.
So What’s the Problem with Java and Memory?
Although in theory it’s simple to say, “Use memory instead of disk,” it’s difficult to put this advice into practice, because the massive growth in available physical memory is outpacing software technology. Backward-compatibility is the main reason for this discrepancy. For instance, when the DOS and Windows platforms moved from 16 to 32-bits (driven mainly by advances in hardware), software vendors were slow to make use of the additional memory address space. This move allowed them to remain compatible with older hardware.
More recently, we witnessed the transition from 32 to 64-bit platforms, and the same problem persisted. For example, a recent survey (3) of Ehcache users showed that two thirds of developers and architects running Java applications were doing so with outdated 32-bit operating systems and/or Java Virtual Machines (JVMs).
To understand why developers and architects continue to rely on relatively archaic technologies, such as disk-based storage and 32-bit platforms, we need to understand some limitations in Java. The original Java language and platform design took into account the problems developers had when manually managing memory with other languages. For instance, when memory management goes wrong, developers experience memory leaks (lack of memory de-allocation) or memory access violations due to accessing memory that has already been de-allocated or attempting to de-allocate memory more than once. To relieve developers of these potential problems, Java implemented automatic memory management of the Java heap with a garbage collector (GC). When a running program no longer requires specific objects, the Java garbage collector reclaims its memory within the Java heap. Memory management is no longer an issue for Java developers, which results in greater productivity overall.
Garbage collection works reasonably well, but it becomes increasingly stressed as the size of the Java heap and numbers of live objects within it increase. Today, GC works well with an occupied Java heap around 3-4GB in size, which also just happens to be the 32-bit memory limit.
The size limits imposed by Java garbage collection explain why 64-bit Java use remains a minority despite the availability of commodity 64-bit CPUs, operating systems and Java for half a decade. Attempts in Java to consume a heap beyond 3-4GB in size can result in large garbage collection pauses (where application threads are stopped so that the GC can reclaim dead objects), unpredictable application response times and large latencies that can violate your application’s service level agreements. With large occupied Java heaps, it’s not uncommon to experience multi-second pauses, often at the most inopportune moments.
Solving the Java Heap/GC Problem
There’s more than one way to try to resolve the problems associated with garbage collection and very large Java heaps. There are alternative garbage collectors to employ, such as those offered by IBM and Oracle with their real-time products. These JVMs offer garbage collection over large heaps with controlled, predictable latency; however, they often come with a price tag and require changes to source code, making them impractical for most applications.
Additionally, Java SE 1.6 introduced the Garbage First (G1) collector in an experimental (beta) form, but it has yet to prove itself reliable and up to the job of large Java heaps. Another solution is Azul’s Zing Virtual Machine, which is based on Oracle’s HotSpot JVM. It offers on-demand memory up to 1TB with “pauseless” operation at the cost of higher CPU utilization, but it also requires major platform changes for operation.
There are two main reasons why users need to run large heaps: in-process caching and sessions storage. Both of these use cases use a map-like API where a framework allocates and de-allocates resources programmatically with puts and removes, opening up a way to constrain and solve the garbage collection problem.
BigMemory to the Rescue
Terracotta’s BigMemory is an all-Java implementation built on Java’s advanced NIO technology. It creates a cache store in memory but outside the Java heap using Direct Byte Buffers. By storing data off heap, the garbage collector does not know about it and therefore does not collect it. Instead, BigMemory responds to the put and remove requests coming from Ehcache to allocate and free memory in its managed byte buffer.
This lets you keep the Java heap relatively small (1-2GB in size), while using the maximum amount of objects within physical memory. As a result, BigMemory can create caches in memory that match physical RAM limits (i.e. 2TB today and more in the future), without the garbage collection penalties that usually come with a Java heap of that size. By storing your application’s data outside of the Java heap but within RAM inside your Java process, you get all the benefits of in-memory storage without the traditional Java costs.
The Benefits of Vertical Scale
With BigMemory, you can take advantage of all of your server’s available memory without the compromises and cost typically associated with enterprise Java applications. For instance, due to the GC penalties we discussed above, many organizations scale their Java application server and JVM implementations across servers, and even within single servers. They do this by running multiple JVM/application server instances, each with small heap sizes, on a single node configured across either multiple network ports or virtual guest OS instances using technology such as VMWare.
While this is certainly one solution to the Java heap problem, there are associated costs with this approach. Configuring and managing multiple JVM instances, or virtual guest OS instances, on even a single node takes time and resources. When you factor in the cost of VMWare licenses, their management infrastructure and the human resources required to monitor such a deployment, the total cost-of-ownership for such a hardware/software solution goes up quickly.
By allowing you to run one JVM/application server instance with a manageable heap and a very large in-memory Enterprise Ehcache cache, BigMemory eliminates these direct and hidden costs, along with the nightmares that come with such complexity. There are many positive results from this approach:
- One commodity big iron server node
- One JVM instance
- All of your data (>2TB, potentially) directly accessible in memory
- Less complexity
- Fewer servers (real or virtual) to manage
- Fewer nodes to potentially fail, upgrade and deploy to
Ehcache’s Tiered Memory Solution with BigMemory
BigMemory and Enterprise Ehcache offer you the potential to build a tiered model for distributed caches where needed. For instance, the algorithms employed by Ehcache place your application’s hot set (the data used most often) in the right location to provide the best performance and optimize the use of your servers’ resources. Figure 1 illustrates this, with the fastest storage mediums towards the top and the typically larger and slower storage mediums towards the bottom.
Figure 1 – Enterprise Ehcache with BigMemory tiered data storage for performance.
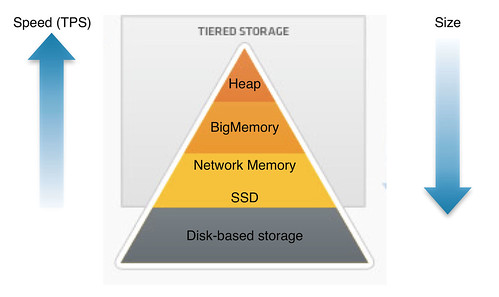
The goal is to place as much of your data within the top tiers of the pyramid as possible. Fortunately, with BigMemory, the top tiers of the pyramid can be sized as large as the physical memory limits of your server, keeping in mind the limits of the Java heap that we just discussed. For even the most demanding applications with big data requirements, a single big iron commodity server combined with BigMemory from Terracotta is all that may be needed.
Though the focus of this article is vertical scalability, there are still valid reasons for creating a caching cluster. Even so, you still leverage vertical scalability, which makes the distributed cache faster with higher density. Ehcache provides a distributed cache, which solves the following problems:
- Horizontal scale out to multi-terabyte sizes
- The n-times problem, where multiple application servers refreshing a cache create added demand on your underlying data store
- The boot-strap problem, where new or restarted nodes need to build a populate their cache when started
- Controlled consistency between the cache instances in each application server node
BigMemory and the Cloud
Cloud vendors such as Amazon, with its EC2 cloud architecture, typically employ virtualization to an extreme. All servers run as virtual guest instances and all disk access is over network-attached storage. This allows the provider to deploy cloud-based customer solutions across physical servers at will and respond to elastic compute demands very quickly. However, this often means that even the network interface card is virtualized and shared across server instances, resulting in bottlenecks to disk-based storage.
With Amazon’s desire to quadruple the amount of memory made available to cloud services within its data centers, combined with the high latency of its shared NIC architecture, intelligent caching is becoming more important. BigMemory is at the center of this architectural trend, providing performance increases and latency improvements without sacrificing the elastic benefits of cloud architecture and without requiring major changes to deployed network architecture or the software that runs on it.
Conclusion
In the late 1990s, Digital ran ads for its 64-bit Alpha processor, claiming there hadn’t been a generation gap that big since the 1960s. They were right, then. Now, more than a decade later, most enterprises are still trying to figure out how to efficiently access all the memory available in a 64-bit address space. With commodity servers expected to grow beyond their current 2TB RAM offerings and SSD technology continuing to improve and become cheaper, the generation gap is only going to widen into a chasm.
References
- 22 nanometer process: http://en.wikipedia.org/wiki/22_nanometer
- Network latency: http://en.wikipedia.org/wiki/10_Gigabit_Ethernet, http://10-gigabit-ethernet.tmcnet.com/topics/10-gigabit-ethernet/articles/154386-netlogic-microsystems-unveils-lowest-latency-10-gigabit-ethernet.htm, http://www.beowulf.org/archive/2009-June/026009.html
- Terracotta user survey: http://terracotta.org/resources/whitepapers/ehcache-user-survey-whitepaper



