Performance data for LevelDB, Berkley DB and BangDB for Random Operations


This is a guest post by Sachin Sinha, Founder of Iqlect and developer of BangDB.
The goal for the paper is to provide the performances data for following embedded databases under various scenarios for random operations such as write and read. The data is presented in graphical manner to make the data self explanatory to some extent.
LevelDB is a fast key-value storage library written at Google that provides an ordered mapping from string keys to string values. Leveldb is based on LSM (Log-Structured Merge-Tree) and uses SSTable and MemTable for the database implementation. It's written in C++ and availabe under BSD license. LevelDB treats key and value as arbitrary byte arrays and stores keys in ordered fashion. It uses snappy compression for the data compression. Write and Read are concurrent for the db, but write performs best with single thread whereas Read scales with number of cores
BerkleyDB (BDB) is a library that provides high performance embedded database for key/value data. Its the most widely used database library with millions of deployed copies. BDB can be configured to run from concurrent data store to transactional data store to fully ACID compliant db. It's written in C and availabe under Sleepycat Public License. BDB treats key and value as arbitrary byte arrays and stores keys in both ordered fashion using BTREE and un-ordered way using HASH. Write and Read are concurrent for the db, and scales well with number of cores especially the Read operation
BangDB is a high performance embedded database for key value data. It's a new entrant into the embedded db space. It's written in C++ and available under BSD license. BangDB treats key and value as arbitrary byte arrays and stores keys in both ordered fashion using BTREE and un-ordered way using HASH. Write, Read are concurrent and scales well with the number of cores
The comparison has been done on the similar grounds (as much as possible) for all the dbs to measure the data as crisply and accurately as possible.
The results of the test show BangDB faster in both reads and writes:
Since BangDB may not be familiar to most people, here's a quick summary of its features:
- Highly concurrent operations on B link -Tree
- Manipulation of the tree by any thread uses only a small constant number of page locks any time
- Search through the tree does not prevent reading any node. Search procedure in-fact does no locking most of the time
- Based on Lehman and Yao paper but extended further for performance improvement
- Concurrent Buffer Pools
- Separate pools for different types of data. This gives flexibility and better performance when it comes to managing data in the buffer pool in different scenarios
- Semi adaptive data flush to ensure performance degrades gracefully in case of data overflowing out of buffer
- Access to individual buffer header in the pool is extensively optimized which allows multiple threads to get right headers in highly efficient manner resulting in better performance
- 2 LRU lists algorithm for better temporal locality
- Other
- Write of data/log is always sequential
- Vectored read and write as far as possible
- Aries algorithm for WAL has been extended for performance. For ex; only index pages have metadata related to logging, data pages are totally free of any such metadata
- Key pages for index are further cached to shortcut various steps which results in less locking on highly accessed pages giving way towards better performance
- Slab allocator for most of the memory requirements
Since leveldb writes data in sorted manner always(based on user defined comparator) hence I have used BTREE (and not HASH) for BDB and BangDB across all tests (though you should note that the BTREE way of organizing data is different than the way LSM-Tree does it). Since the best write performance by LevelDB is achieved using single thread and best read performance by using 4 threads(on 4 core machine), hence I have used the best possible numbers for all these dbs unless mentioned for a particular test.
For BangDB and BDB we have used 4 threads for both read and write. Of course these are the active number of threads performing the write and read but there could be more number of threads doing the background operations for each db. For ex; LevelDB uses background thread for compaction, similarly BangDB uses background threads for log flush, managing the buffer pool, read/write from disk, checkpointing etc. I have used the same machine and the similar db configuration (as much as possible) for all the dbs for the performance analysis.
Following machine ($750 commodity hardware) used for the test;
- Model: 4 CPU cores, Intel(R) Core(TM) i5-2400 CPU @ 3.10GHz, 64bit
- CPU cache : 6MB
- OS : Linux, 3.2.0-32-generic, Ubuntu, x86_64
- RAM : 8GB
- Disk : 500GB, 7200 RPM, 16MB cache
- File System: ext4
Following are the configuration that are kept constant throughout the analysis (unless restated before the test)
- Assertion: OFF
- Compression for LevelDB: ON
- Write and Read: Random
- Write Ahead Log for BangDB and BDB: ON
- Single Process and multiple threads
- Transaction for BDB and BangDB: ON, with only in-memory update, Writes are not synchronous
- Checkpointing, overflow to disk, log flush, write ahead logging: ON
- Access method: Tree/Btree
- Key Size: 24 bytes, random
- Value Size: 100 - 400 bytes, random
- Page Size: 8KB
There are overall six test cases as described below. Before each test case, the different configuration parameters set for the test case are mentioned. For most of test cases large cache sizes(around 1 - 2GB) are used simply because mostly I have used relatively large number of operations (in the range of couple of millions and 100K operations here consumes around 50MB including key and value) and for many tests I needed to ensure that data doesn't overflow out of the buffer. But for few test cases I have repeated the tests using small memory as well (for test A and B) to show the numbers when cache size is smaller (in the range of 64MB). Other test cases can be repeated for small (or even smaller) cache sizes and similar trends (compared to the bigger cache size tests) could be seen.
The reason for showing the graph for individual test rather than putting a number against the test case is to assess the variability of the performance with different number of operations and other variable parameters. The typical number of operations are in millions starting with thousands.
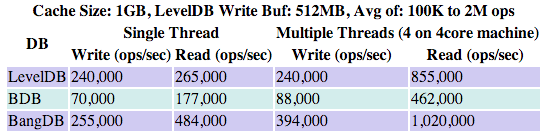
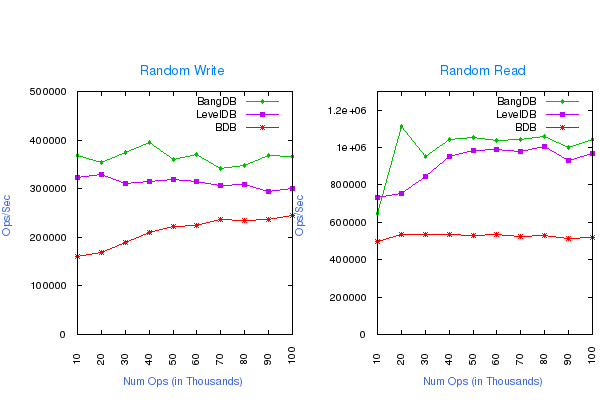
Random Write and Read using single thread
No Overflow of data (out of the memory), 100K - 2M operations, following are the DB configurations for the test;
- Write Buffer size for LevelDB: 512MB
- Cache size for all the dbs: 1GB
- Log Buffer size for BDB and BangDB: 256MB
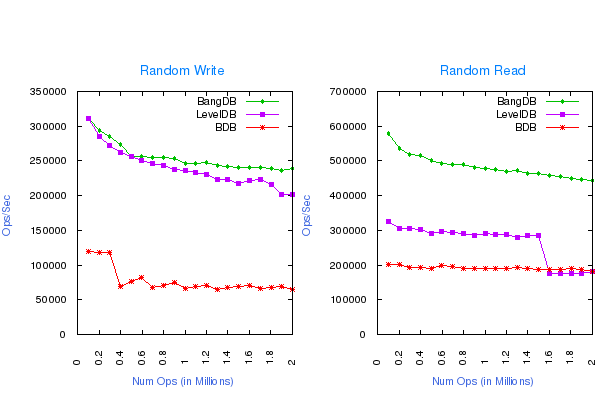
Same test case result for smaller cache size is shown below;
- Write Buffer size for LevelDB: 64MB
- Cache size for all the dbs: 64MB
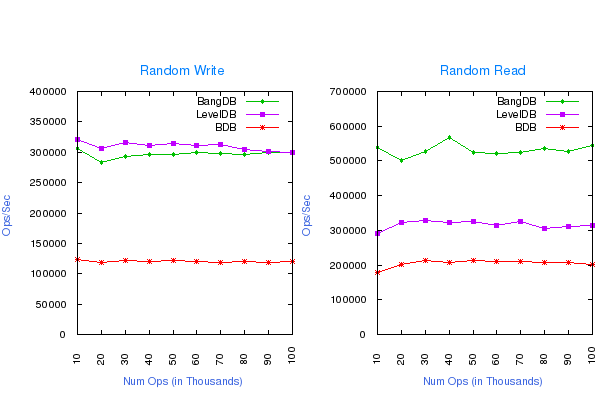
Random Write and Read using Multiple Threads
No Overflow of data (out of the memory), 100K - 2M operations, following are the DB configurations for the test;
- Write Buffer size for LevelDB: 512MB
- Cache size for all the dbs: 1GB
- Log Buffer size for BDB and BangDB: 256MB
- LevelDB - 1 Thread for Write and 4 Threads for Read
- 4 Threads for Read and Write for BDB and BangDB
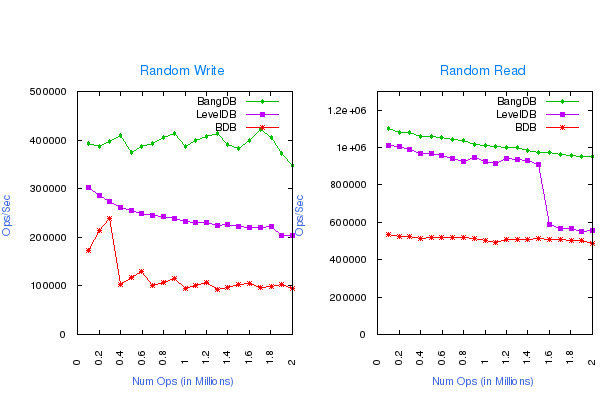
Same test case result for smaller cache size is shown below;
- Write Buffer size for LevelDB: 64MB
- Cache size for all the dbs: 64MB
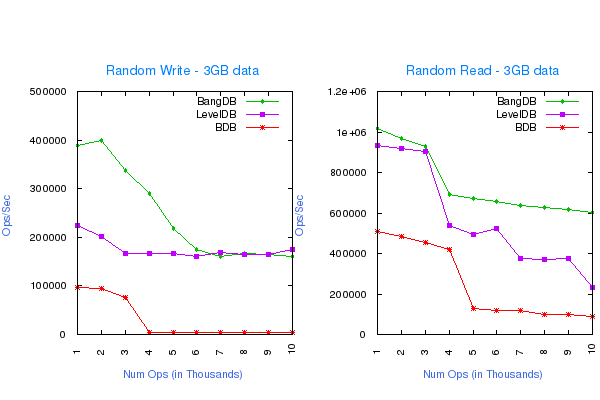
Random Write and Read of 3GB of data using 1.5GB Buffer Cache
50% Overflow of data (50% to/from disk), 1M - 10M operations, following are the DB configurations for the test;
- Write Buffer size for LevelDB: 1GB
- Cache size for all the dbs: 1.5GB
- Log Buffer size for BDB and BangDB: 256MB
- LevelDB - 1 Thread for Write and 4 Threads for Read
- 4 Threads for Read and Write for BDB and BangDB
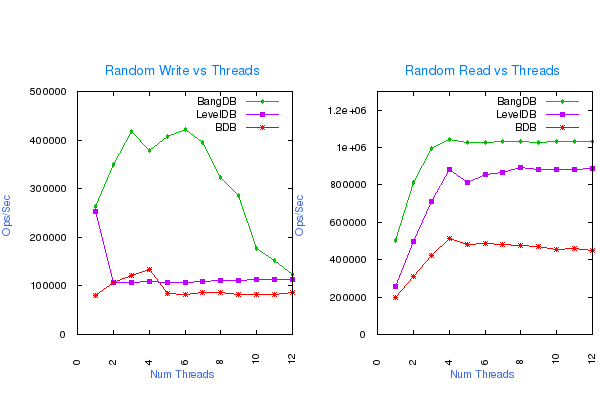
Random Write and Read vs the number of concurrent threads
No Overflow of data (out of the memory), 1M operations, following are the DB configurations for the test;
- Write Buffer size for LevelDB: 512MB
- Cache size for all the dbs: 1GB
- Log Buffer size for BDB and BangDB: 256MB
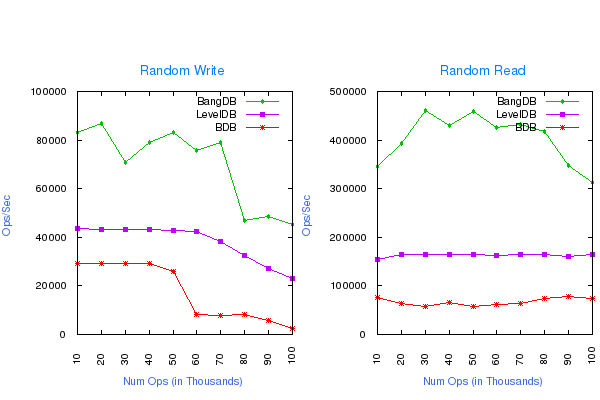
Random Write and Read for Large Values
No Overflow of data (out of the memory), 10K - 100K operations, following are the DB configurations for the test;
- Value size: 10,000 bytes
- Write Buffer size for LevelDB: 1.5GB
- Cache size for all the dbs: 2GB
- Log Buffer size for BDB and BangDB: 512MB
- Page Size: 32KB
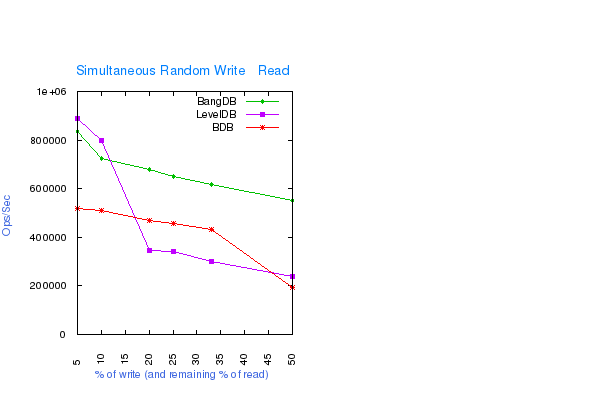
Random Write and Read simultaneously in overlapped manner
No Overflow of data (out of the memory), 1M operations. The test basically first inserts around (100-x)% of data for x% write and (100-x)% read and then tries to write remaining x% of data with (100-x)% of simultaneous read by 4 concurrent threads and time elapsed is computed only for the later x% write with (100-x)% read. If data is already present then it updates the existing data. following are DB configuration for the test;
- Write Buffer size for LevelDB: 1GB
- Cache size for all the dbs: 1GB
- Log Buffer size for BDB and BangDB: 256MB
Summary
I have just covered very few use cases for the performance analysis, for example the sequential read and writes, batch operations are not covered. Also the changes in various configurable parameters may change the graphs completely. BDB and BangDB support Hash based access of the data as well but not covered here because LevelDB stores data in sorted order only.
If we see the amount of data written by individual dbs, we will find that BangDB is writing more data than the other two dbs. BangDB doesn't use compression at the moment hence this can be improved in future if compression is supported.
BDB write performance goes down drastically when writing more than the allocated buffer. For multiple thread tests the dbs perform best (as expected) when number of threads is close to the number of cores in the machine, with the exception of LevelDB write, which works best when single thread performs the operation.
All dbs are available for download freely hence one can/may cover more scenarios comparing these three or other/more such dbs. The test files for the performance analysis is available for download.



