Strategy: Exploit Processor Affinity for High and Predictable Performance

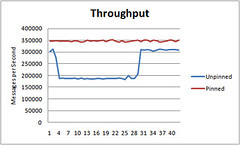
Martin Thompson wrote a really interesting article on the beneficial performance impact of taking advantage of Processor Affinity:
The interesting thing I've observed is that the unpinned test will follow a step function of unpredictable performance. Across many runs I've seen different patterns but all similar in this step function nature. For the pinned tests I get consistent throughput with no step pattern and always the greatest throughput.
The idea is by assigning a thread to a particular CPU that when a thread is rescheduled to run on the same CPU, it can take advantage of the "accumulated state in the processor, including instructions and data in the cache." With multi-core chips the norm now, you may want to decide for yourself how to assign work to cores and not let the OS do it for you. The results are surprisingly strong.



