Building Redundant Datacenter Networks is Not For Sissies - Use an Outside WAN Backbone

Ivan Pepelnjak, in his short and information packed REDUNDANT DATA CENTER INTERNET CONNECTIVITY video, shows why networking as played at the highest levels is something you want to leave to professionals, like a large animal country vetenarian delivering a stuck foal at 2AM on a dark and stormy night.
There are always a lot questions about the black art of building redundant datacenter networks and there's a shortage of accessible explanations. What I liked about Ivan's video is how effortlessly he explains the issues and tradeoffs you can expect in designing your own solution, as well as giving creative solutions to those problems. A lot of years of experience are boiled down to a 17 minute video.
Ivan begins by showing what a canonical fully redundant datacenter would look like:
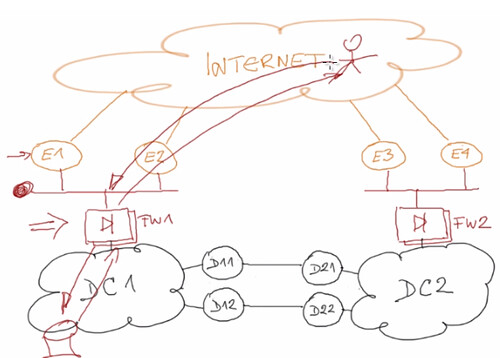
It's like an ark where everything goes two by two. You have two datacenters, each datacenter has redundant core switches, redundant servers, redundant disk arrays, redundant links between datacenters (for synchronization and restart), fully redundant Internet connections between both datacenters, L3 connectivity between the two datacenters to handle hot standby scenarios, redundant firewalls (active-active or active-passive), redundant edge routers, redundant links to redundant ISPs, EBGP running with the ISPs and IBGP between the routers so they can exchange routes from the service providers.
Ivan does a great job in quickly explaining all this and the traffic flow between the datacenters, users, and stateful devices like load balancers, NAT, and firewalls. Traffic from a user on the Internet and server goes like: 1) the edge routers advertise the public IP prefix for the datacenter on the Internet, 2) traffic from the user arrives through one of the uplinks, 3) traffic goes through a stateful device (load balancer, firewall, NAT), 4) packet arrives at the server.
Everything is redundant so what could possibly go wrong? You are still surprisingly vulnerable to dual faults. Faults in two sensitive areas and your expensive and complicated redundant datacenter setup is reduced to one lone datacenter operating on it's own.
During fault analysis one of the usual assumptions is that you don't consider double faults. The reason is you quickly learn that creating a system that can handle double faults is impossibly complex and expensive. When you do handle double faults the logic becomes so complex it tranforms into a bigger fault domain than the original problem.
Ivan proposes a plausible double fault scenario where you lose a router and a link so that one datacenter is completely isolated from the Internet. You don't control the links so they could easily go down. In this scenario the datacenter interconnects (DCIs) are still running.
Another failure scenario has the DCIs being lost, which leaves the Internet connections up. With the DCIs down you wouldn't be able to replicate between datacenters. Ivan says what you do in this scenario is up to your policies. Maybe the datacenter can operate independently and resync at some later time? Maybe one datacenter needs to die until the connections are back up? Maybe some servers need to migrate from one datacenter to the other? Maybe you can survive with reduced functionality?
On a link failure, if your Internet links are 10G and your datacenter links are 10G, then they might be able to substitute for one another temporarily. But what if your Internet links are only 1G or vice versa? Maybe you want to migrate servers or take one datacenter out of operation. If the DCI links are congested and you want to migrate servers, live migration will just make the congestion problem worse. If you don't think the connections will come back up then it may make sense to shutdown a datacenter and have a temporary loss of service rather than migrate servers over an already congested link.
If the Internet links are down for one datacenter it makes sense to think of routing user traffic to that datacenter through the other datacenter and through the DCI links. This isn't as easy at is sounds. One problem is the firewalls in the different datacenters are stateful, so they won't have the session state for the other datacenter. Ivan says creating stretched VLANs to link the firewalls into a cluster is a bad idea. Another problem is the remaining firewall will now have to perform NAT translations for both firewalls, which means you need redundant configurations. You also have routing problems for return traffic, which Ivan explains in more detail.
It's a total mess says Ivan. Hard to achieve, complex routing, and synchronized firewall configurations which will never happen in real life.
When dealing with multiple fault scenarios what you try to do is simplify the system, remove away layers of complexity, so what remains and simpler and more robust. This can be difficult as it takes real experience and insight. But that's exactly what Ivan does in his proposal to fix this mess.
Ivan proposes creating an external WAN backbone that can be used to exchange data between the four edge routers. The network becomes simplified. Edge routers connect the datacenters and the ISPs. It looks something like:
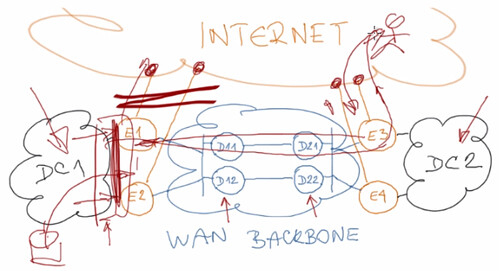
Ivan goes into detail about how his solution of using an outside WAN backbone fixes the design complexities of the earlier design. Following it gave me a headache, but made sense as he was explaining it :-) Well worth watching in detail if you are wrestling with the problem building datacenter networks.



