Google: Multiplex Multiple Works Loads on Computers to Increase Machine Utilization and Save Money

Jeff Dean gave a talk at SFBay ACM and at about 3 minutes in he goes over how Google runs jobs on computers, which is different than how most shops distribute workloads.
It’s common for machines to be dedicated to one service, say run a database, run a cache, run this, or run that. The logic is:
Better control over responsiveness as you generally know the traffic loads a machine will experience and you can over provision a box to be safe.
Easier to manage, load balance, configure, upgrade, create and make highly available. Since you know what a machine does another machine can be provisioned to do the same work.
The problem is monocropping hardware though conceptually clean for humans and safe for applications, is hugely wasteful. Machines are woefully underutilized, even in a virtualized world.
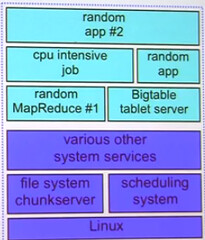
What Google does is use a shared environment in a datacenter where all kinds of stuff run on each computer. Batch computation and interactive computations all run together on the same machine. Each machine has (or may have): Linux, file system chunkserver, scheduling system, other system services, random application and higher level system services like Bigtable tablet server, a CPU intensive job, one ore more MapReduce jobs, and more random applications.
The benefit giving a machine lots to do is greatly increased utilization. Machines these days are like race horses pulling a plow. They need to be set free to run with abandon. Machine monocropping like big agriculture monocropping is a relic from a past era. So we see here a parallel in the computer world with the permaculture revolution taking over our food production system. Doing one thing and one thing only leads to inefficiencies.
The downside to the increased variability of running multiple workloads on a machine is it’s constant change which to humans appears as chaos and we humans do not like chaos. You have jobs running in the foreground and background, constantly changing, bursting in CPU, memory, disk, and network usage, so nobody has guarantees which means you have unpredictable performance. For interactive jobs, those where a user wants a response fast, it's especially troublesome.
With large fanout systems, which means architectures that encourage hundreds or thousands of different services to be contacted to service a request, the result can be a high variability of latency.
Google wants high machine utilization for its higher power efficiency and less money spent on expensive servers. So Google needed to go about solving all the problems generated by higher machine utilization, which as you might imagine involves lots of cool solutions. More on that in Google On Latency Tolerant Systems: Making A Predictable Whole Out Of Unpredictable Parts.
Related Articles
- On Hacker News
- Introduction to Linux Control Groups (Cgroups) - provide a mechanism for easily managing and monitoring system resources, by partitioning things like cpu time, system memory, disk and network bandwidth, into groups, then assigning tasks to those groups.



