Google Finds NUMA Up to 20% Slower for Gmail and Websearch

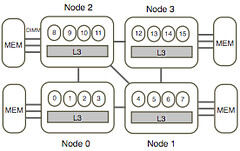
When you have a large population of servers you have both the opportunity and the incentive to perform interesting studies. Authors from Google and the University of California in Optimizing Google’s Warehouse Scale Computers: The NUMA Experience conducted such a study, taking a look at how jobs run on clusters of machines using a NUMA architecture. Since NUMA is common on server class machines it's a topic of general interest for those looking to maximize machine utilization across clusters.
Some of the results are surprising:
- The methodology of how to attribute such fine performance variations to NUMA effects within such a complex system is perhaps more interesting than the results themselves. Well worth reading just for that story.
- The performance swing due to NUMA is up to 15% on AMD Barcelona for Gmail backend and 20% on Intel Westmere for Web-search frontend.
- Memory locality is not always King. Because of the interaction between NUMA and cache sharing/contention it turns out different applications prefer different profiles for cache sharing, remote access, cache contention, etc. More remote memory accesses can outperform more local accesses significantly (by up to 12%). Bigtable, for example, performs better with 100% remote accesses than 50% remote accesses. Which means a simple NUMA-aware scheduling can yield sizable benefits in production. The optimal mapping is highly dependent on the applications and their co-runners.
- Gmail’s backend server experienced around a 4x range in average request latency during a week’s time.
What did Google find?
Both our production WSC analysis and load-test experiments show that the performance impact of NUMA is significant for large scale web-service applications on modern multicore servers. In our study, the performance swing due to NUMA is up to 15% on AMD Barcelona for Gmail backend and 20% on Intel Westmere for Web-search frontend. Using the load-test, we also observed that on multicore multisocket machines, there is often a tradeoff between optimizing NUMA performance by clustering threads close to the memory nodes to increase the amount of local accesses and optimizing for cache performance by spreading threads to reduce the cache contention. For example, bigtable benefits from cache sharing and would prefer 100 % remote accesses to 50% remote. Search-frontend prefers spreading the threads to multiple caches to reduce cache contention and thus also prefers 100 % remote accesses to 50% remote.
In conclusion, surprisingly, some running scenarios with more remote memory accesses may outperform scenarios with more local accesses due to an increased amount of cache contention for the latter, especially when 100% local accesses cannot be guaranteed. This tradeoff between NUMA and cache sharing/contention varies for different applications and when the application’s corunner changes. The tradeoff also depends on the remote access penalty and the impact of cache contention on a given machine platform. On our Intel Westmere, more often, NUMA has a more significant impact than cache contention. This may be due to the fact that this platform has a fairly large shared cache while the remote access latency is as large as 1.73x of local latency. In this work, we show that remote memory accesses have a significant performance impact on NUMA machines for these applications. And different from UMA machines, remote access latency is often a more dominating impact than cache contention on NUMA machines. This indicates that a simple NUMA-aware scheduling can already yield sizable benefits in production for those platforms.Based on our findings, NUMA-aware thread mapping is implemented and in the deployment process in our production WSCs. Considering both contention and NUMA may provide further performance benefit. However the optimal mapping is highly dependent on the applications and their co-runners. This indicates additional benefit for adaptive thread mapping at the cost of added implementation complexity



