Stuff The Internet Says On Scalability For May 16th, 2014

Hey, it's HighScalability time:

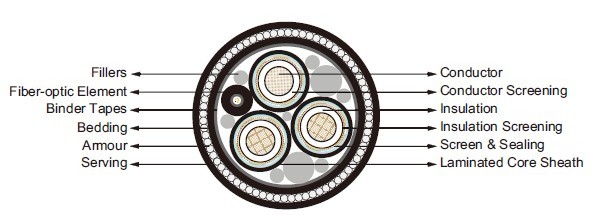
Cross Section of an Undersea Cable. It's industrial art. The parts. The story.
- 400,000,000,000: Wayback Machine pages indexed; 100 billion: Google searches per month; 10 million: Snapchat monthly user growth.
- Quotable Quotes:
- @duncanjw: The Great Rewrite - many apps will be rewritten not just replatformed over next 10 years says @cote #openstacksummit
- @RFFlores: The Openstack conundrum. If you don't adopt it, you will regret it in the future. If you do adopt it, you will regret it now
- elementai: I love Redis so much, it became like a superglue where "just enough" performance is needed to resolve a bottleneck problem, but you don't have resources to rewrite a whole thing in something fast.
- @antirez: "when software engineering is reduced to plumbing together generic systems, software engineers lose their sense of ownership"
- Tom Akehurst: Microservices vs. monolith is a false dichotomy.
- @joestump: “Keep in mind that any piece of butt-based infrastructure can fail at any time. Plan your infrastructure accordingly.” Ain’t that the truth?
- @SalesforceEng: Check out the scale of Kafka @LinkedInEng. @bonkoif says these numbers are about a month old. 3.25 million msgs/sec.
- Don Neufeld: The first is to look deeply into the stack of implicit assumptions I’m working with. It’s often the unspoken assumptions that are the most important ones. The second flows from the first and it’s to focus less on building the right thing and more how we’re going to meet our immediate needs.
- Dan Gillmor: We’re in danger of losing what’s made the Internet the most important medium in history – a decentralized platform where the people at the edges of the networks – that would be you and me – don’t need permission to communicate, create and innovate.
- If you think of a Hotel as an app, hotels have been doing in-app purchases for a long time. They lead with a teaser rate and then charge for anything that might cross a desire-money threshold. Wifi, that's extra. Gym, that's extra. The bar, a cover charge. Drinks, so so expensive. The pool, extra. A lounge by the pool is double extra extra. To go all the way hotels just need to let you stay for free and then fully monetize all the gamification points.
- Apple: We handle hundreds of millions of active users using some of the most desirable devices on the planet and several Billion iMesssages/day, 40 billion push notifications/day, 16+ trillion push notifications sent to date.
- It's a data prison for everyone! Comcast plans data caps for all customers in 5 years, could be 500GB. Or just a few 4K movies.
- From the future of everything to the verge of extinction. The Slow Decline of Peer-to-Peer File Sharing: People have shifted their activities to streaming over file sharing. Subscribers get quality content at a reasonable price and it's dead simple to use, whereas torrenting or file sharing is a little more complicated.
- I don't think people understand how hard this is to do in practice. European Court Lets Users Erase Records on Web. Once data is stored on tape deleting takes rewriting all the non-deleted data to another tape. So it's far more efficient to forget indexes to data than delete the data. Which goes against the point I'd imagine.
- How is a strategy tax hands off? @parislemon: Instagram's decision to use Facebook's much worse place database over Foursquare's has made the product worse. Stupid.
- Excellent detailed example of the SEDA architecture in action. Guide to Cassandra Thread Pools. Follow the regal message as it flows from thread pool to thread pool, transforming as it makes its way to its final resting place.
- Solr Cloud scales with a Hadoop cluster: providing distributed indexing and search capabilities, supporting the following features: Central configuration for the entire cluster; Automatic load balancing and fail-over for queries; ZooKeeper integration for cluster coordination and configuration.
- Good idea. Scaling Feature Flags With Zookeeper. Using Zookeeper to dynamically control features without redeploying. Throughput and latency are dramatically improved over redis.
- Introducing Firebase Hosting. Once you have their data the next logical step is the assets. This is hosting as in a CDN, not as in code. Good discussion on HN about the various back-end service options, like Parse vs Firebase.
- Peter Bourgon on Roshi: Given a well-defined problem, a specific solution may be far less costly than a generic version: there's a smaller domain translation, a much smaller surface area, and less operational friction. We hope that Roshi stands in evidence for the case that the practice of software engineering can be a more thoughtful and crafted process. Software that is "invented here" can, in the right circumstances, deliver outstanding business value.
- Epic article on Fast and Reliable Ranking in Datastore. One of the difficulties when buying into an ecosystem is doing things not directly supported by the ecosystem. Like breathing under water. Global real-time ranking at scale is one of those kind of things for Google App Engine. The goal is to find a O(log n) algorithm that works on GAE. The article goes through a series of possible solutions and where they are weak.
- Scaling SQL with Redis. More evidence of Redis as the Swiss Army Knife of the Infrastructure world. Here it's used to alleviate row contention; rate limiting; basic locks; time series data.
- So why If redis is already a part of the stack, why is Memcached still used alongside Redis? A question I've also had. Antirez writes an excellent reply. The crux of it is that memcached is more memory efficient, so you can store more for the buck, which is what a cache is all about.
- Randy Bias: Infrastructure can’t ever be truly elastic, but its properties can enable elastic applications running on top of it. An elastic cloud is one that has been designed such that individual cost of resources such as VMs, block storage, and objects is as inexpensive as possible. This is directly related to Jevon’s Paradox, which states that as a technology progresses, the increase in efficiency leads towards an increase in the rate of consumption of that technology
- Pretty good list. 10 Articles Every Programmer Must Read.
- VoltDB has come a long ways. Debunking Myths About the VoltDB In-memory Database: “VoltDB requires stored procedures.”; “VoltDB doesn’t support ad-hoc SQL.”; “VoltDB is slow unless I use stored procedures.”; “I have to know Java to use VoltDB.”; “VoltDB has garbage collection problems because it is written in Java.”; “VoltDB’s SQL is very limited.”; “Yes, VoltDB supports cross-partition transactions, but they are too slow to use.”
- Ivan Pepelnjak: When you’re building a new data center network or refreshing an old one, start with its customers – the servers: buy new high-end servers with plenty of RAM and CPU cores, virtualize as much as you can, and don’t mix the old and the new world.
- Great explanation. I/O Multiplexing Using epoll and kqueue System Calls: In essence, this means taking a multitude of inputs and allowing one through at a given time (or combining them into a single input). I/O multiplexing more specifically deals with input and output streams, blocking, reading, and writing. In this example, I will demonstrate how multiplexing works using the linux kernel system call epoll.
- The New AWS TCO (Total Cost of Ownership) Calculator. Nice diagram of the overall landscape, but the tool takes a lot of up front work to use properly.
- You don't need to use a hosted search service. You can roll your own. Here's some good advice on doing just that: Guerilla Search with Solr - How to run a 3 millions documents search on a $15/Month machine.
- James Hamilton on Air Traffic Control System Failure & Complex System Testing: The lessons here are at least twofold. First, as complex systems age, the environmental conditions under which they operate change dramatically. The second lesson is that rare events will happen. I doubt a U2 pass of the western US is all that rare but something about this one was unusual. We need to expect that complex systems will face unexpected environmental conditions and look hard for some form degraded operations mode.
- libtorrent on asynchronous disk I/O: The first attempt at doing disk I/O asynchronous used various system specific operations for truly async. operations. The idea was that the more operations the kernel knows about, the better scheduling it can perform. 2 years later, I decided to switch over to using a thread pool where disk operations instead would use regular blocking calls.
- Symas Lightning Memory-Mapped Database (LMDB): LMDB is an ultra-fast, ultra-compact key-value embedded data store developed by Symas for the OpenLDAP Project. It uses memory-mapped files, so it has the read performance of a pure in-memory database while still offering the persistence of standard disk-based databases, and is only limited to the size of the virtual address space.




{kind=link}