1 Aerospike server X 1 Amazon EC2 instance = 1 Million TPS for just $1.68/hour


This a guest post by Anshu Prateek, Tech Lead, DevOps at Aerospike and Rajkumar Iyer, Member of the Technical Staff at Aerospike.
Cloud infrastructure services like Amazon EC2 have proven their worth with wild success. The ease of scaling up resources, spinning them up as and when needed and paying by unit of time has unleashed developer creativity, but virtualized environments are not widely considered as the place to run high performance applications and databases.
Cloud providers however have come a long way in their offerings and need a second review of their performance capabilities. After showing 1 Million TPS on Aerospike on bare metal servers, we decided to investigate cloud performance and in the process, bust the myth that cloud != high performance.
We examined a variety of Amazon instances and just discovered the recipe for processing 1 Million TPS in RAM on 1 Aerospike server on a single C3.8xlarge instance - for just $1.68/hr !!!
According to internetlivestats.com, there are 7.5k new tweets per second, 45k google searches per second and 2.3 Million emails sent per second. What would you build if you could process 1 Million database transactions per second for just $1.68/hr?
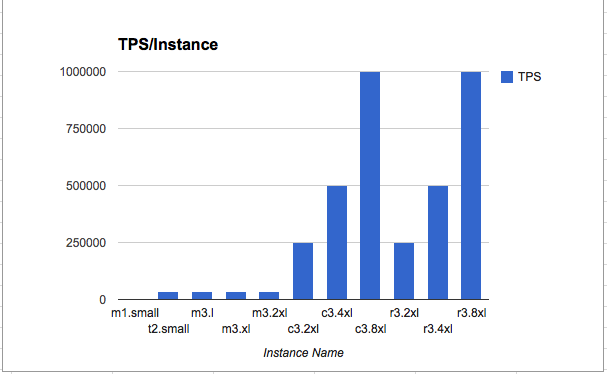
(Higher is better)
This post documents our experiments with a number of Amazon EC2 instances, our findings, recommended tuning parameters and instructions that you can follow to get this unprecedented level of price/performance for yourself.
Unless stated otherwise we performed this experiment with following setup:
A single Aerospike in-memory NoSQL database server running on a single Amazon instance
10 million objects, each of size 100 bytes (10 bins or columns, each of size 10 bytes). We kept the object size small to accommodate data in memory (RAM) for all the instances we investigated.
The Java benchmark tool that comes with the Aerospike Java client. The Client process is run on non-server instances. The number of client instances is set to maximize load pushed in parallel to the Aerospike server and the exact number used depends on each server instance type.
In order to maximize load on the Amazon infrastructure, we used an in-memory (RAM) workload of 100% read requests distributed over the entire key space.
We used spot-Instances for cost optimization. Both Spot and On-demand instances behaved more or less the same in terms of performance.
Step 1: Select Instance Types
We looked for instances based on the following requirements:
· Ability to hold the entire dataset in memory.
· Ability for the network and CPU to support the required transaction rates.
We did not consider i2 and hs1 instances as they are instances with high storage capability and this project was limited to pure RAM.
We examined a number of EC2 instance types:
· R - memory intensive
· C - compute intensive
· M - balance between R and C
· T - a very low-end beginner machine
Different instance types have different network capabilities, so we picked a machine of each type and measured the upper limit of bandwidth using iperf tools and pushing large size packets from as many clients as we could. For each of these machines, we found the following bandwidth limits:
· Moderate (upper bound of 100MBps)
· High (ranges from 300Mbps to 1.8Gbps)
· 10 Gigabit (peaks at around 8.8 Gbps)
We did not consider t1 and m1.small which have “Low” network as specified by Amazon, because for instances with “Low” or “Moderate” network performance, the bottleneck is the network. In addition, M series instances do not support enhanced networking at this time.
Step 2: Pick Virtual Machines
Amazon uses Xen, an open source virtualization platform that supports para-virtualization (PV) and full or hardware assisted virtualization (HVM). We tried both types:
Para Virtualized Machine: For starters, we picked c3.8xlarge. These are expensive instances but we picked them up to get a feel of what to expect. This instance was started using a PV AMI in an EC2-Classic network. We found that although these machines are rated 10Gbps we could get from 1.8 to 2.2 Gbps (iperf result) and the machine is rate limited to around 85k packets per second. We then tried C3.2xlarge to see if there was a pattern and it turns out that even this machine is rate limited. Looking at top for CPU utilization, we observed in PV machines, the virtualization layer consumes up to 40% of the allotted CPU when running heavy loads. We were able to achieve 85 ktps on Aerospike on these instances as well, clearly rate limited again.
Hardware Virtualized Machine: HVM based instances with enhanced networking, as per AWS documentation, provide better networking with higher packets per second. Our experiments confirmed this with a direct 3x increase in TPS without any additional enhancements. Running the c3.4xlarge instance with enhanced networking setup in the same placement group as a client, Aerospike performed at 215K TPS.
We picked HVM instances for further experiments as they are much better than PV instances at the same price point.
Step 3: Use Placement Groups
A placement group is a logical grouping of instances within a single Availability Zone. Using placement groups within a Amazon Virtual Private Cloud (VPC) enables applications to participate in a low-latency, full bisection 10 Gbps network.
We used placement groups to maximize performance. Also, VPC is a pre-requisite for using HVM instances.
Step 4: Test Tenancy
We tried both dedicated tenancy and shared tenancy and did not find any significant difference between them and picked shared tenancy.
Step 5: Minimize CPU Stealing
One of the issues in running processes on Amazon is the lack of predictable access to compute power. When the CPU is overused, for example when a thread consumes too much CPU in a burst, EC2 lets it finish its time slice. However, it will give a lower amount of CPU in the next time slice. This causes peaks and troughs in application throughput that can be avoided by throttling the threads to not have cpu bursts. This technique makes the application behave more consistently over time.
In our experiments, we were able to tune Aerospike to avoid the overuse of the CPU. This resulted in predictable performance, with little to no amount of stealing observed (0.2 to 0.7) even under heavy loads.
Step 6: Network
After picking instance types, VMs, placement groups, tenancy and tuning, we were still not sure what was blocking us from processing more TPS. Looking at the instance, we found that the system was bottlenecking because of interrupt processing on a single core. Each NIC seemed to offer only a single interrupt queue, by default bound to a single core.
This led us to search for a work around. We tried 4 things:
IRQ Distribution: We tried forcing the system to distribute irq to multiple cores (disable irqbalance + echo ffff > *smp_affinity) and found it bound to single real core. A single irq cannot be distributed over multiple real cores for processing.
Interrupt Coalescing: Given that soft interrupts were issued, we also tried interrupt coalescing. On EC2, it improved CPU utilization a little but did not translate into better processing.
More NICs: Elastic Network Interfaces (ENI) came to the rescue!, ENIs provide a way of adding multiple (virtual) NICs to an instance. A single NIC peaks at around 250ktps, bottlenecking on cores processing interrupts. Adding more interfaces helped immediately and with a total of 4 interfaces and 4 client processes on 2 instances, we were able to get upto 960k tps on a single c3.8xlarge server instance. We ensured that each client would push to a specific interface, hence utilizing all the NICs and CPUs. Using ENIs with private IPs is free of cost.
Receive Packet Steering: Another simpler approach is to distribute irq over multiple cores using RPS (“echo f > /sys/class/net/eth0/queues/rx-0/rps_cpus”). This eliminated the need of using multiple NICs/ENIs making management easier and gave us similar TPS to multiple ENIs. Single NIC with RPS enabled can push up to 800ktps with interrupts spread over 4 cores.
After experimenting with different combinations of NICs and RPS and with some Aerospike tuning (setting service thread config appropriately), we were able to achieve extremely high performance - five clients (C3.2xlarge) pushing load on a single node Aerospike cluster running on C3.8xlarge, processing 1M TPS for just $1.68/hr !!!
|
Instance type |
Network type |
Peak Observed bandwidth |
TPS (max) |
DI** |
DI** |
RI*** cost/mo |
RI** cost/yr |
RI** cost/mo |
RI** cost/yr |
|
m3.xlarge |
high |
~700Mbps |
~87k |
0.28 |
201.6 |
127.28 |
1534.24 |
81.2 |
526.6 |
|
m3.2xlarge |
high |
1Gbps |
~87k |
0.56 |
403.2 |
253.12 |
3050.96 |
161.4 |
1052.2 |
|
c3.2xlarge* |
high |
1Gbps |
~250k |
0.42 |
302.4 |
183.88 |
2215.04 |
121.8 |
789.4 |
|
c3.4xlarge* |
high |
1Gbps |
~500k |
0.84 |
604.8 |
368.48 |
4438.84 |
242.6 |
1577.8 |
|
c3.8xlarge* |
10G |
8.86Gbps |
1000k |
1.68 |
1209.6 |
735.24 |
8868.92 |
484.48 |
3145.84 |
|
r3.large |
moderate |
~600Mbps |
80ktps |
0.175 |
126 |
69.76 |
830.08 |
47.72 |
228.76 |
|
r3.xlarge |
moderate |
1Gbps |
120ktps |
0.35 |
252 |
138.52 |
1660.16 |
95.44 |
456.52 |
|
r3.2xlarge* |
high |
1Gbps |
250k |
0.7 |
504 |
276.04 |
3320.32 |
189.88 |
912.04 |
|
r3.4xlarge* |
high |
1Gbps |
500k |
1.4 |
1008 |
551.08 |
6640.64 |
379.76 |
1823.08 |
|
r3.8xlarge* |
10G |
8.86Gbps |
1000k |
2.8 |
2016 |
1102.16 |
13281.28 |
759.52 |
3645.16 |
** DI = On Demand Instances
** RI = Reserved Instances
** All cost analysis is for a single instance of the given type. For Reserved Instances, the 1 year and 3 year terms have been calculated with heavy utilization (100% utilization).
NB: These instances sometimes show better or worse performance. These numbers are based on typical results seen over many runs over a month.
* Core Bottleneck : We tried many different combination of using multiple NIC and RPS setup but in all cases there was a high amount of %hi and a core was bottlenecking. CPU utilization was only around 50% of peak.
Steps to Follow
The numbers above show that cloud infrastructures like Amazon EC2 are now a viable option for running very high performance databases and you too can follow these steps to 1 M TPS for just $1.68/hr with Aerospike on Amazon.
Use AWS Marketplace to setup an Aerospike HVM based c3.8xlarge instance in a VPC to be used as server. Use a placement group.
Attach 4 additional ENIs to the server instance. No need to use Elastic IPs though with these additional ENIs.
Run afterburner.sh (cd /opt/aerospike/bin; sudo ./afterburner.sh) to set the optimal number of threads on each Aerospike server.
Use AWS Marketplace to setup 5 Aerospike c3.2xlarge instances to be used as clients using the same HVM and VPC in the same placement group as the server.
Ensure security group has tcp port 3000-3003 open for communication within nodes. TCP Port 8081 should be open to internet for using AMC.
Configure the in-memory namespace to use 54GB of RAM (c3.8xlarge has 60GB)
Start the Aerospike server.
Load the server with data using Java benchmark client.
cd <java client>/benchmarks
./run_benchmarks -z 40 -n test -w I -o S:10 -b 10 -l 23 -k 10000000 -latency 5,1 -h YOUR_AWS_INTERNAL_IP
Run the clients with 100% read load. Point each client to a separate private IP on different ENIs.
cd <java client>/benchmarks
./run_benchmarks -z 40 -n test -w RU,100 -o S:10 -b 10 -l 23 -k 10000000 -latency 5,1 -h YOUR_AWS_INTERNAL_IP
With 5 clients, you should be getting 1M TPS!
But we did not stop there. We then evaluated price/performance of 4 Amazon instances when running a 4-node Aerospike cluster in RAM with 5 different read/write workloads. More on what we found in a Part 2.



