Part 2: The Cloud Does Equal High performance


This a guest post by Anshu Prateek, Tech Lead, DevOps at Aerospike and Rajkumar Iyer, Member of the Technical Staff at Aerospike.
In our first post we busted the myth that cloud != high performance and outlined the steps to 1 Million TPS (100% reads in RAM) on 1 Amazon EC2 instance for just $1.68/hr. In this post we evaluate the performance of 4 Amazon instances when running a 4 node Aerospike cluster in RAM with 5 different read/write workloads and show that the r3.2xlarge instance delivers the best price/performance.
Several reports have already documented the performance of distributed NoSQL databases on virtual and bare metal cloud infrastructures:
Altoros Systems examined the performance of different NoSQL databases on Amazon Extra Large Instances in a report titled “A Vendor-independent Comparison of NoSQL Databases: Cassandra, HBase, MongoDB, Riak”.
Thumbtack Technology examined the performance of different NoSQL databases (Aerospike, MongoDB, Cassandra and Couchbase) on bare metal in pure RAM and on SSDs in a report titled “Ultra-High Performance NoSQL Benchmarking”.
More recently, the CloudSpectator report titled “Performance Analysis: Benchmarking a NoSQL Database on Bare-Metal and Virtualized Public Cloud”, examined performance of Aerospike on Internap’s bare-metal servers and SSDs as well as on Amazon EC2 and Rackspace clouds.
For this series of experiments we tested Amazon instances using a 4 node Aerospike cluster with data in memory (RAM), and 5 real world workloads - from 100% writes, 50/50 balanced reads/writes, 80/20 and 95/5 to 100% reads. In addition, instead of 1 node, 100% reads and 10 Million objects used in the first post, in this experiment, we used 40 Million objects and the 4 node Aerospike cluster with mixed reads and writes was doing more work than the single node, to ensure synchronous replication and immediate consistency.
We used the following 4 Amazon instances:
m1.large: Previous generation
m3.xlarge: Current generation without enhanced network
r3.2xlarge: Current generation
r3.large: Current generation to validate linear scaling,
running a 80/20 workload on a 2,4,6,8 node cluster)
Result 1: Amazon r3.* scales Aerospike cluster TPS linearly with percentage of reads
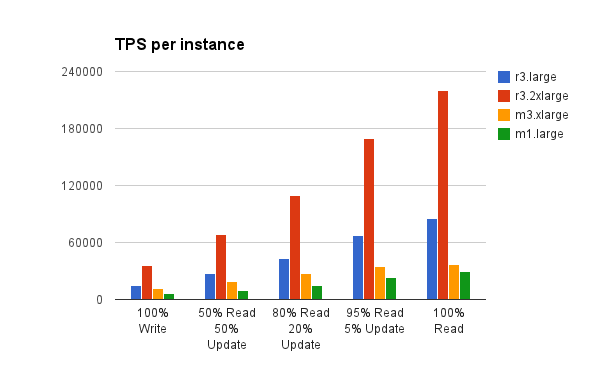
(Higher is better)
On a 4 node Aerospike cluster, the Amazon r3.* instance delivers the highest throughput across workloads and scales linearly with the percentage of reads. Other instance types bottleneck on the network and cannot push higher amounts of reads
Result 2: Amazon latencies vs TPS per instance
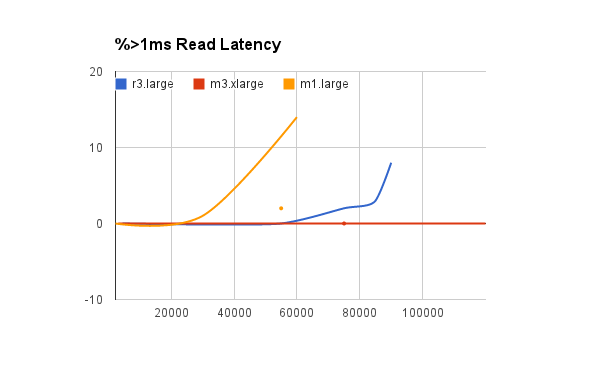
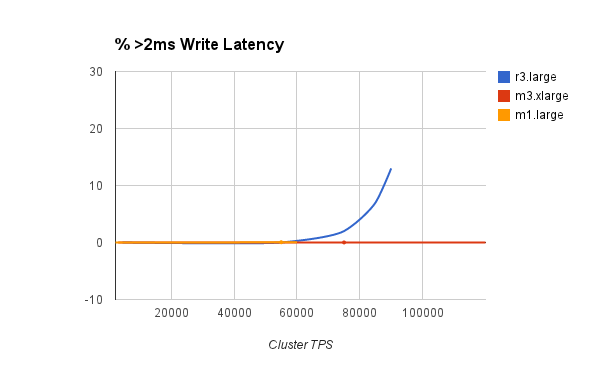
(Lower is better)
Each Amazon instance has a limited number of requests that can be processed with low latency. Once the limit is reached even though higher throughput can be achieved, latency characteristics deteriorate rapidly.
Result 3: Amazon r3.large scales Aerospike TPS linearly on just a handful of nodes
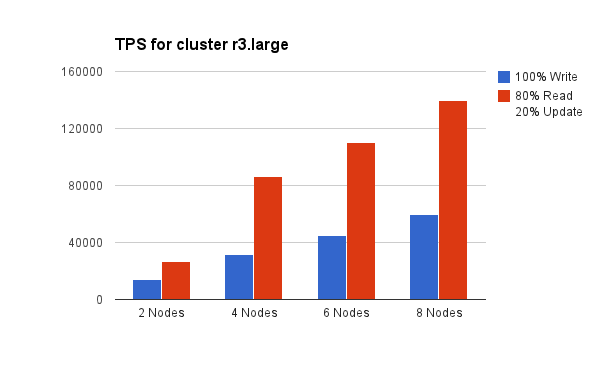
(Higher is better)
On Amazon r3.large and a 80/20 read/write workload, Aerospike TPS scales linearly from 27k TPS on two nodes to 140k TPS on just 8 nodes.
Result 4: Comparing Number of Nodes vs TPS across Amazon Instances
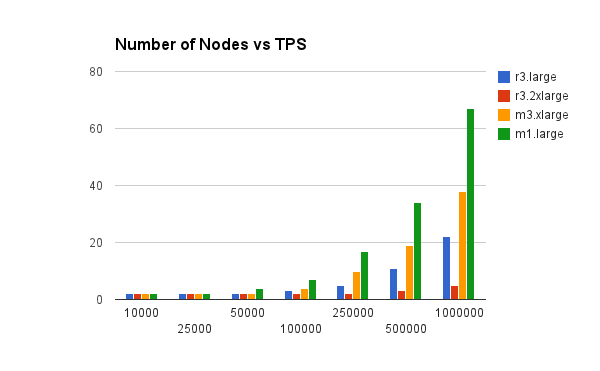
(Lower is better)
Result 5: Amazon r3.2xlarge shows optimal price/performance with Aerospike
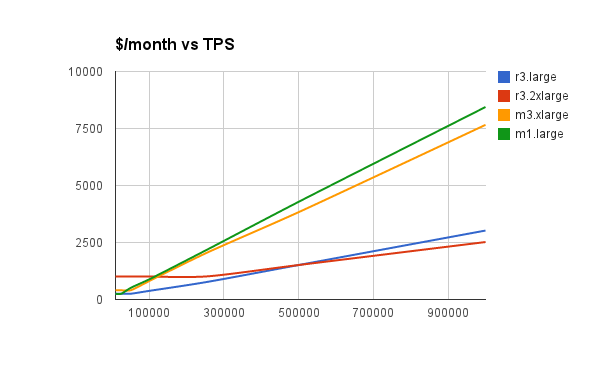
(Lower is better)
Depending on the instance, 2-67 nodes are required to deliver performance ranging from 15k TPS to 1 Million TPS, for prices starting at just $252 per month to $8552 per month. Costs can go down further with yearly reservation and this graph shows that the best Amazon instance for Aerospike is the r3.large or r3.2xlarge, with r3.2xlarge requiring slightly fewer nodes and lower costs for the same performance.
We have documented the steps so that you too can validate the performance of Amazon instances and reproduce results that show linear scalability, extremely high throughput and predictable low latency with Aerospike on Amazon.
Step by Step Setup
-
Setup Instances for Servers: Bring up Aerospike on 4 Amazon instances of the same type in the same availability zone for each Aerospike server. You can use AWS Marketplace to create these instances. You should use an instance which supports enhanced networking and VPC is a prerequisite for using HVM with enhanced networking. The security group should allow ports 3000-3003 for Aerospike within the instances and 8081 for AMC from the internet.
-
Setup Aerospike:
-
Setup mesh configuration to make a 4 node Aerospike cluster.
-
Run afterburner.sh (cd /opt/aerospike/bin; sudo ./afterburner.sh) to set the optimal number of threads on each Aerospike server.
-
-
Setup System:
-
Make sure RPS is enabled for the ethernet card. This can be configured for eth0 by running command echo f | sudo tee /sys/network/eth0/rx-0/rps_cpus
-
-
Setup Instances for Clients: Bring up 4-8 Amazon instances for client machines. i.e For a 4 node Aerospike cluster, use 4 client instances of the same class or 8 instances of the next best class e.g for a C3.8xlarge server instance, 8 C3.4xl instances may be needed to push enough load.
-
Install java benchmark client on the client instances. Use one of the boxes to run AMC service.
-
Start the cluster on the server instances and let the migration finish. You can check migration progress in AMC.
-
Load 40 million records, each 100 bytes in size (10 bins each of 10 bytes). Run the sample Java Benchmark command:
cd <java client>/benchmarks./run_benchmarks -z 40 -n test -w I -o S:10 -b 10 -l 23 -k 40000000 -latency 5,1 -h YOUR_AWS_INTERNAL_IP - Fire up, from multiple java benchmark clients, the uniform distribution workload. (We used a single client on r3.8xlarge as it was enough for our loading requirement).
Run the Tests Yourself
We have published a cloud formation script - which should take care of spinning up server and client instances and setup up the Aerospike cluster. Follow instruction in the README to try it yourself. This should be quick and cost you 1 hour worth of instance time that is $5.60 ($2.8 each for servers and clients).
Related Articles
- 1 Aerospike Server X 1 Amazon EC2 Instance = 1 Million TPS For Just $1.68/Hour
- The Quest For Database Scale: The 1 M TPS Challenge - Three Design Points And Five Common Bottlenecks To Avoid
- Russ’ 10 Ingredient Recipe For Making 1 Million TPS On $5K Hardware
- Switch Your Databases To Flash Storage. Now. Or You're Doing It Wrong



