Stuff The Internet Says On Scalability For January 9th, 2015

Hey, it's HighScalability time:

UFOs or Floating Solar Balloon power stations? You decide.
- 700 Million: WhatsApp active monthly users; 17 million: comments on Stack Exchange in 2014
- Quotable Quotes
- John von Neumann: It is easier to write a new code than to understand an old one.
- @BenedictEvans: Gross revenue on Apple & Google's app stores was a little over $20bn in 2014. Bigger than recorded music, FWIW.
- Julian Bigelow: Absence of a signal should never be used as a signal.
- Bigelow ~ separate signal from noise at every stage of the process—in this case, at the transfer of every single bit—rather than allowing noise to accumulate along the way
- cgb_: One of the things I've found interesting about rapidly popular opensource solutions in the last 1-2 years is how quickly venture cap funding comes in and drives the direction of future development.
- @miostaffin: "If Amazon wants to test 5,000 users to use a feature, they just need to turn it on for 45 seconds." -@jmspool #uxdc
- Roberta Ness: Amazing possibility on the one hand and frustrating inaction on the other—that is the yin and yang of modern science. Invention generates ever more gizmos and gadgets, but imagination is not providing clues to solving the scientific puzzles that threaten our very existence.
- Can HTTPS really be faster than HTTP? Yes, it can. Take the test for yourself. The secret: SPDY. More at Why we don’t use a CDN: A story about SPDY and SSL.
- A fascinating and well told tale of the unexpected at Facebook. Solving the Mystery of Link Imbalance: A Metastable Failure State at Scale: The most literal conclusion to draw from this story is that MRU connection pools shouldn’t be used for connections that traverse aggregated links. At a meta-level, the next time you are debugging emergent behavior, you might try thinking of the components as agents colluding via covert channels. At an organizational level, this investigation is a great example of why we say that nothing at Facebook is somebody else’s problem.
- Everything old is new again. Facebook on disaggregation vs. hyperconvergence: Just when everyone agreed that scale-out infrastructure with commodity nodes of tightly-coupled CPU, memory and storage is the way to go, Facebook’s Jeff Qin, a capacity management engineer – in a talk at Storage Visions 2015 – offers an opposing vision: disaggregated racks. One rack for computes, another for memory and a third – and fourth – for storage.
- Why Instagram Worked. Instagram was the result of a pivot away from a not popular enough social networking site to a stripped down app that allowed people to document their world in pictures. Though the source article is short on the why, there's a good discussion on Hacker News. Some interesting reasons: Instagram worked because it algorithmically hides flaws in photographs so everyone's pictures look "good"; Snapping a photo is easy and revolves around a moment -- something easier to recognize when it's worthy of sharing; Startups need lucky breaks, but connections with the right people increase the odds considerably; Instagram worked because it was at the right place at the right time; It worked because it's a simple, quick, ultra-low friction way of sharing photos.
- Atheists, it's not what you think. The God Login. The incomparable Jeff Atwood does a deep dive on the design of a common everyday object: the Login page. The title was inspired by one of Jeff's teacher's who asked what was the "God Algorithm" for a problem, that is, if God solved a problem what would the solution look like? While you may not agree with the proposed solution to the Login page problem, you may at least come away believing that one may or may not exist.
- How Spotify Scales Apache Storm: When we build applications we think about scalability in the following way: Software has sound architecture and high quality; Software is easy to release, monitor and tweak; Software performance can keep up with additional load by adding resources linearly.
- Jon Watte talks about how to ameliorate two of the big drawbacks of REST: Cache Invalidation and Request Chattiness. THE REAL-TIME WEB IN REST SERVICES AT IMVU: we at IMVU already have a highly scalable, multi-cast architecture...Instead of responding with just a single JSON document, we respond with a look-up table of URLs to JSON documents, including all the information we believe the client will want, based on the original request...servers and clients that are in cahoots and pay attention will end up delivering a user experience with more than 30x fewer server round-trips...It would be great if SPDY (and, future, HTTP2) could support pre-stuffing responses in the real world.
- Here's how Storify implemented Load-balancing Websockets on EC2 using Node.js and socket.io for their realtime collaborative editor. It uses Sticky Sessions, ELB, and HAProxy, with just a pinch of the right configuration.
- How [Pinterest] built new bulk editing tools: We were met with two key challenges: synchronization and completing tasks sequentially...The first challenge dealt with keeping different components of the web synchronized...The second key challenge we encountered was with race conditions. Bulk edit requires doing many tasks at once.
- Hailo has a nice slideck on Scaling micro-services Architecture on AWS and You're Good to Go. Wins: complete new features in days, not months; seamless service deployment; servers scale up and down based on demand; automated reaping of misbehaving services and AZ failover; fault-tolerant distributed services architecture.
- Once you got stuff working, you have to keep it working. Which leads us to how does Twitter find anomalies in a time series? Using BreakoutDetection: a complementary R package for automatic detection of one or more breakouts in time series. While anomalies are point-in-time anomalous data points, breakouts are characterized by a ramp up from one steady state to another.
- Some good year in review stories from Data Center Knowledge: The 10 Most Popular Data Center Stories of 2014. I must have missed this one: Mining Experiment: Running 600 Servers for a Year Yields 0.4 Bitcoin worth a total return of about $275.08 at current prices on major Bitcoin exchanges. Wow. So much power for so little gain.
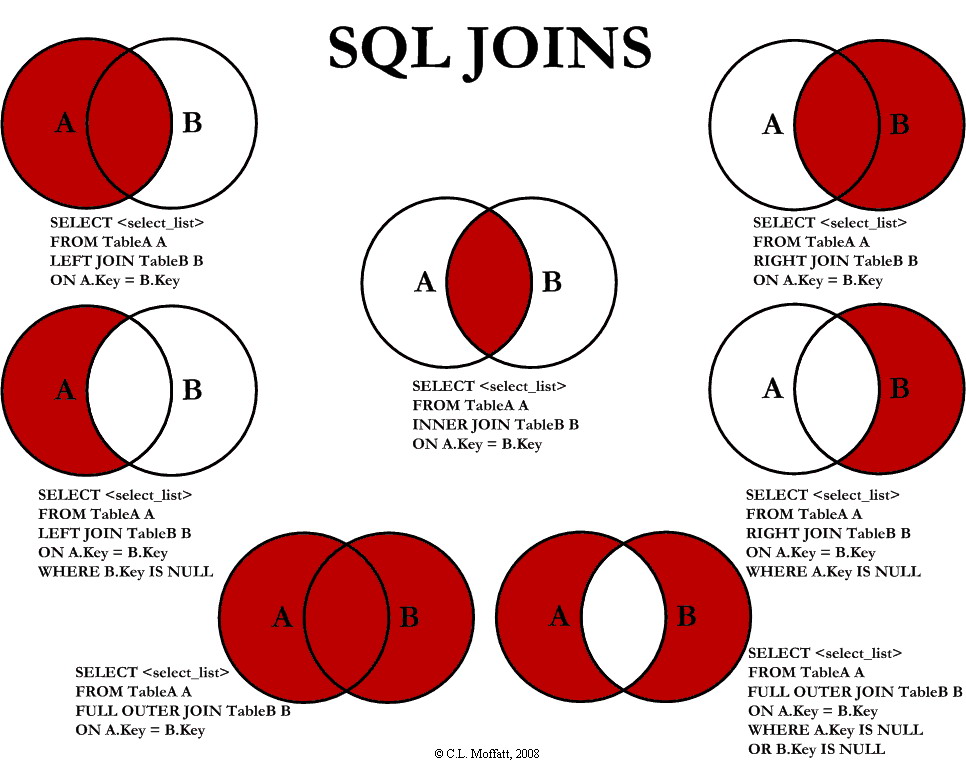
- Venn Diagrams are a great way to reveal what different SQL Joins really mean.
- Great how-to. Understanding Nginx HTTP Proxying, Load Balancing, Buffering, and Caching: In this guide, we will discuss Nginx's http proxying capabilities, which allow Nginx to pass requests off to backend http servers for further processing...We will discuss how to scale out using Nginx's built-in load balancing capabilities. We will also explore buffering and caching to improve the performance of proxying operations for clients.
- Micro, Meso, and Macro shifts: The idea is very simple. Keep computing, networking, and storage very tightly tied together, and enable applications to leverage the local (and distributed) resources at the best possible speed. Provide scale out storage and compute capability, and the fastest possible communication infrastructure
- Martin Thompson: Some things work better as mutable, other things work better as immutable. My general rule of thumb is all facts and storage should be considered immutable, and the working set of a model can be mutable but ONLY from a single writer. Cases for multiple writers mutating any data structure should be considered very very carefully. Private unshared state you can do whatever you like with provided it stays behind closed doors.
- Definitely present in my set of posts to read is the next in an already excellent series: Bloom Filters - Building a Column Family store - Part 7. Edward Capriolo is really hashing it hard with these articles.
- Is the Tech Boom the New Gold Rush?: "65 percent of the people with bachelor's degrees in Silicon Valley were born in another country. I mean this is amazing -- two thirds of the people who have completed college are born outside the country. Half of the companies started between 1995 and 2005, half of them have at least one founder who was born outside of the United States... I think this constant sort of refresh, this sort of intellectual refresh, that comes with new waves of immigrants just can't be underestimated."
- Be sure to take a look at Greg Linden's Quick Links.




{kind=link}