Stuff The Internet Says On Scalability For March 6th, 2015

Hey, it's HighScalability time:
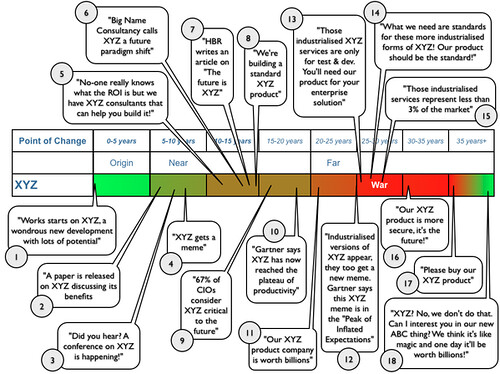
The future of technology in one simple graph (via swardley)
- $50 billion: the worth of AWS (is it low?); 21 petabytes: size of the Internet Archive; 41 million: # of views of posts about a certain dress
- Quotable Quotes:
- @bpoetz: programming is awesome if you like feeling dumb and then eventually feeling less dumb but then feeling dumb about something else pretty soon
- @Steve_Yegge: Saying you don't need debuggers because you have unit tests is like saying you don't need detectives because you have jails.
- Nasser Manesh: “Some of the things we ran into are issues [with Docker] that developers won’t see on laptops. They only show up on real servers with real BIOSes, 12 disk drives, three NICs, etc., and then they start showing up in a real way. It took quite some time to find and work around these issues.”
- Guerrilla Mantras Online: Best practices are an admission of failure.
- Keine Kommentare: Using master-master for MySQL? To be frankly we need to get rid of that architecture. We are skipping the active-active setup and show why master-master even for failover reasons is the wrong decision.
- Ed Felten: the NSA’s actions in the ‘90s to weaken exportable cryptography boomeranged on the agency, undermining the security of its own site twenty years later.
- @trisha_gee: "Java is both viable and profitable for low latency" @giltene at #qconlondon
- @michaelklishin: Saw Eric Brewer trending worldwide. Thought the CAP theorem finally went mainstream. Apparently some Canadian hockey player got traded.
- @ThomasFrey: Mobile game revenues will grow 16.5% in 2015, to more than $3B
- John Allspaw: #NoEstimates is an example of something that engineers seem to do a lot, communicating a concept by saying what it’s not.
- Improved thread handling contention, NDB API receive processing, scans and PK lookups in the data nodes has lead to a monster 200M reads per second in MySQL Cluster 7.4. That's on an impressive hardware configuration to be sure, but it doesn't matter how mighty the hardware if your software can't drive it.
- Have you heard of this before? LinkedIn shows how to use SDCH, an HTTP/1.1-compatible extension, which reduces the required bandwidth through the use of a dictionary shared between the client and the server, to achieve impressive results: When sdch and gzip are combined, we have seen additional compression as high as 81% on certain files when compared to gzip only. Average additional compression across our static content was about 24%.
- Double awesome description of How we [StackExchange] upgrade a live data center. It was an intricate multi-day highly choreographed dance. Toes were stepped on, but there was also great artistry. The result of the new beefier hardware: The decrease on question render times (from approx30-35ms to 10-15ms) is only part of the fun. Great comment thread on reddit.
- A jaunty exploration of Microservices: What are They and Why Should You Care? Indix is following Twitter and Netflix by tossing their monolith for microservices. The main idea: Microservices decouples your systems and gives more options and choices to evolve them independently.
- Wired's new stack: WordPress, PHP, Stylus for CSS, jQuery, starting with React.js, JSON, Vagrant, Gulp for task automation, Git hooks, Lining, GitHub, Jenkins.
- Have you ever wanted to search Hacker News? Algolia has created a great search engine for HN.
- If you've ever used diff or looked at the code, it's hard to believe this would ever be fast enough, but apparently it is. Introduction to the React JavaScript Library: React employs a diff algorithm that only re-renders the DOM nodes that have changed. This algorithm is used for efficient re-rendering because DOM operations are typically slow, at least compared to executing JavaScript statements.
- David Rosenthal: Fundamentally, tiering like most storage architectures suffers from the idea that in order to do anything with data you need to move it from the storage medium to some compute engine. Thus an obsession with I/O bandwidth rather than what the application really wants, which is query processing rate. By moving computation to the data on the storage medium, rather than moving data to the computation, architectures like DAWN and Seagate's and WD's Ethernet-connected hard disks show how to avoid the need to tier and thus the need to be right in your predictions about how users will access the data.
- BehindTheSite maintains a log of various web technology stacks.
- Million user webchat with Full Stack Flux, React, redis and PostgreSQL: Scalability isn’t magic: there are some things that simply can’t scale. Our goal here will be to create the conditions so that using Flux over the Wire isn’t less performant/scalable that using the traditional query/response model (in fact, it will often scale even easier, since it streamlines cache invalidation, more on that later). To achieve this, we need to isolate business logic from client state & I/O so that the underlying process(es) don’t waste precious cycles dealing with the latter.
- Is it? Is it really? Life is More Than a Series of Cache Misses.
- Tired of maintaining your own message bus for server-to-server messaging? Google has a new service for you: Google Cloud Pub/Sub. Performance? Sub-second notification even when tested at over 1 million messages per second. Cost? NA. One comment claimed this service was the productization of an internal serviced used at Google. Look forward to more details.
- Evolution of the Internet: from Decentralized to Centralized. Centralized is easier to monetize and manage, but also consider deep learning requires the aggregation of knowledge. Lots and lots of data. Could Skynet ever evolve in a decentralized world?
- Can this really be true? Review: Microsoft Azure beats Amazon and Google for mobile development: Frankly, I went into the Azure portion of this review expecting to see overpriced junk left over from the Ballmer era. I was blown away by the thoughtful implementation of mobile services and the respect with which the Azure Mobile Services team has addressed the needs of app developers without imposing on the choice of solution. Also, Azure Search is now Generally Available.
- Murat with two more patented paper reviews: Extracting more concurrency from Distributed Transaction, an ornate protocol for "deciding on an order and pipelining the execution of these conflicting transactions in some determined order," and Salt: Combining ACID and BASE in a Distributed Database, which attempts to provide "high performance like BASE with modest programming effort like ACID." Neither lead to distributed nirvana.
- Deep dive on a classic: Merge Sort Algorithm, which is also the answer to a classic interview question: how do you sort a terabyte of data?
- Wow. Unorthodocs: Abandon your DVCS and Return to Sanity. While there's very little I disagree with in this well reasoned post, git has the advantage of being free, "standard," and working. So it would be very hard to ditch git now.
- Michael Kurtz (ADS): "The problem with curation is that the funding is almost entirely local but in the digital world the use is mainly global. Leads to tragedy of the commons where no one will assume long-term obligation to curate and manage data which is mainly not from local sources."
- Erasure Coding is one of those creations that puts magic and algorithms on the same footing. How Erasure Coding is Not Like Replication. Erasure coding uses far less disk space, but they are also more complex: With erasure coding, this atomicity guarantee must be maintained globally - no node may overwrite any old data until all nodes have the new data. You can meet this coordination need with 2PC.
- Best description of promises that I've read: Parallel Processing with Promises...Promises allow programmers to hook asynchronous function calls together, waiting for each to return success or failure before running the next appropriate function in the chain...Promises provide a simple and correct method of writing a collaborative system.
- Interesting Postmortem: Storify downtime on March 2nd: The problem was that we had one dropped index in our application code. This meant that whenever the new primary took the lead, the application asked to build that index. It was happening in the background, so it was kind of ok for the primary. But as soon as the primary finished, all the secondaries started building it in the foreground, which meant that our application couldn't reach MongoDB anymore.
- Is PostgreSQL Your Next JSON Database?: If you update your JSON documents in place, the answer is no. What PostgreSQL is very good at is storing and retrieving JSON documents and their fields. But even though you can individually address the various fields within the JSON document, you can’t update a single field.
- Here's a free book of Real World Lessons: Stories of Hadoop and NoSQL Done Right.
- Epic post on the need to change database architectures based on the value of immutability. Turning the database inside-out with Apache Samza. Great comment thread on Hacker News, particularly eloff: The reality is shared, mutable state is the most efficient way of working with memory-sized data. People can rant and rave all they want about the benefits of immutability vs mutability, but at the end of the day, if performance is important to you, you'd be best to ignore them.
- Images are data. Deep Learning at Flickr: Garrigues’ stewardship of Deep Learning at Flickr means that they have gone from zero to full scale image recognition in 18 months using a pipeline from feature recognition on a GPU through training and calibrating classifiers through to product integration.
- Read it for the analysis, love it for the use of a Hierarchical Timing Wheel. Purgatory Redesign Proposal: In the new design, we use Hierarchical Timing Wheels for the timeout timer, WeakReference based list for watcher lists, and DelayQueue of timer buckets to advance the clock on demand.
- Machines are tools, that is all. Deep Neural Networks are Easily Fooled: It is possible to produce images totally unrecognizable to human eyes that DNNs believe with near certainty are familiar objects.
- And if you haven't had enough, there's always More quick links from Greg Linden.



