Stuff The Internet Says On Scalability For August 21st, 2015

Hey, it's HighScalability time:
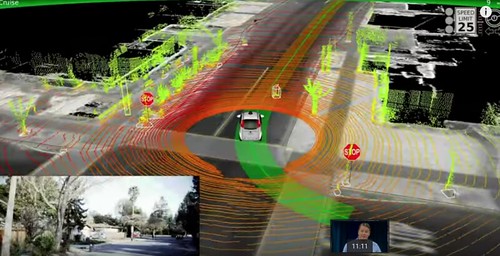
Hunter-Seeker? Nope. This is the beauty of what a Google driverless car sees. Great TED talk.
- $2.8 billion: projected Instagram ad revenue in 2017; 1 trillion: Azure event hub events per month; 10 million: Stack Overflow questions asked; 1 billion: max volts generated by a lightening strike; 850: apps downloaded every second from the AppStore; 2000: years data can be stored in DNA; 60: # of robots needed to replace 600 humans; 1 million: queries per second with Nginx, Ubuntu, EC2
- Quotable Quotes:
- Tales from the Lunar Module Guidance Computer: we landed on the moon with 152 Kbytes of onboard computer memory.
- @ijuma: Included in JDK 8 update 60 "changes GHASH internals from using byte[] to long, improving performance about 10x
- @ErrataRob: I love the whining over the Bitcoin XT fork. It's as if anarchists/libertarians don't understand what anarchy/libertarianism means.
- Network World: the LHC Computing Grid has 132,992 physical CPUs, 553,611 logical CPUs, 300PB of online disk storage and 230PB of nearline (magnetic tape) storage. It's a staggering amount of processing capacity and data storage that relies on having no single point of failure.
- @petereisentraut: Chef is kind of a distributed monkey-patching festival running as root.
- @SciencePorn: If you were to remove all of the empty space from the atoms that make up every human on earth, all humans would fit into an apple.
- SDN for the cloud: Most of the concepts presented in the papers have been put into practice in Microsoft cloud infrastructures. As a result of these improvements, modern Azure services can carry up to 1,400,000 SQL databases. Moreover, a typical Azure event hub sees as high as 1 trillion events per month.
- On the Alphabet Google reorg...what Horace Dediu has to say on functional vs divisional organizations may provide insight. A functional organization, which is used by the Army and Apple, prevents cross divisional fights for resources and power. Those are the kind of internal politics that kill a company. Why not just sidestep all that?
- Here's how Pinterest shards MySQL to scale: All data needed to be replicated to a slave machine for backup, with high availability and dumping to S3 for MapReduce...You never want to read/write to a slave in production...Slaves lag, which causes strange bugs; I still recommend startups avoid the fancy new stuff — try really hard to just use MySQL. Trust me. I have the scars to prove it...We created a 64 bit ID that contains the shard ID...To create a new Pin, we gather all the data and create a JSON blob...A mapping table links one object to another...there are three primary ways to add more capacity...more RAM...open up new ranges...move some shards to new machines...This system is best effort. It does not give you Atomicity, Isolation or Consistency in all cases...We stored the shard configuration table in ZooKeeper...This system has been in production at Pinterest for 3.5 years now and will likely be in there forever.
- Nobody expects the quadruple fault! Google loses data as lightning strikes: four successive lightning strikes on the local utilities grid that powers our European datacenter caused a brief loss of power to storage systems...only a very small number of disks remained affected, totalling less than 0.000001% of the space of allocated persistent disks...full recovery is not possible.
- Flxone upgraded to Go version 1.5 and reduced their 95-percentile garbage collector from 279 milliseconds down to just 10 ms, a 96% decrease in garbage collection pause time. Average request latency dropped by 53%. I wonder now if they can reduce the number of nodes required to meet their SLA? And would the results hold if they wrote their app more natively, that is to generate garbage?
- Some good Lessons Learned From Reading Post Mortems: 25% of bugs are from simply ignoring an error; 8% are from catching the wrong exception; 2% are from incomplete TODOs; 98% of critical failures can be reproduced in a 3 node cluster; Configuration bugs are the most common cause of really bad outages; every part of a machine can fail; humans are even more error prone than machines; not having the right sort of alerting; “obvious” things still cause a lot of failures.
- You may like this slidedeck on What does it take to make Google work at scale?
- Inside Facebook's Datacenter Network. Some points: Although Hadoop deployments traffic is consistent with literature, other traffic is neither rack-local nor all-to-all; Despite this inter-rack traffic, most of the links are loaded with less than 10% traffic; Traffic is bipartite due to colocation of servers of same type; traffic is stable over time and per destination.
- Aren't Actors always stateful? The Inevitable Rise of the Stateful Web Application.
- Interesting interview with Vint Cerf on Quoracast. Large numbers of devices on the Internet bring up issues of safety, security, and privacy. Getting everything connected may not be a wonderful thing. A future headline we are likely to read is "100,000 Refrigerators Take Down Bank of America." We have a fragile and bumpy future ahead. We make regular use of things we would have called AI 20 years ago. Giving software autonomy is what can lead to bad consequences, he's not so worried about out of control AI powered golems. The blockchain technology is a powerful one, it's a way of building a distributed ledger. The idea is if enough replication and distribution are done then it would be very hard to lose or fabricate information. The jury is still out on the mechanisms that are use to compensate people for building the blockchain. He would rather see a regulated environment for transactions rather than a completely unrestrained one. We don't have solutions for the problem of losing digital data over time. It's a digital dark age. Physical media may last a long time, but the readers of the media won't last that long, and we don't have a way to preserve the meaning of those bits. The Olive Executable Archive is a potential solution. If you are concerned about saving static digital objects then print them on high quality paper. We don't have assurance digital objects will be accessible in even as little as ten years from now.
- Has the IO gap been breached? Flash slaying the latency dragon?: They hooked up two servers sporting Infiniband and NVMe SSDs running an I/O test and show latencies of ≈2.5µsec for remote drive access.
- Jepsen strikes again. Call me Maybe: Chronos: In Camille Fournier’s excellent talk on consensus systems, she advises that “Zookeeper Owns Your Availability.” Consensus systems are a necessary and powerful tool, but they add complexity and new failure modes. Specifically, if the consensus system goes down, you can’t do work any more. In Chronos’s case, you’re not just running one consensus system, but three. If any one of them fails, you’re in for a bad time. An acquaintance notes that at their large production service, their DB has lost 2/3 quorum nodes twice this year.
- If you think our world is a simulation, is it credible to think there is enough compute power available to have an infinite regress of simulated worlds creating other simulated worlds? It is not, therefore this world is real. The Physics of Free Will.
- The browser continues its evolution into becoming a great environment for writing servers. lya Grigorik shows how to eliminate HTTP roundtrips with a new capability called Preconnect, which lets you tell a browser about connections you would like to set up ahead of time to eliminate "the costly DNS, TCP, and TLS roundtrips from the critical path of the actual request."
- Seems about right. Are “Better” Ideas More Likely to Succeed? An Empirical Analysis of Startup Evaluation: We find no evidence, by contrast, that experts can effectively assess the commercial potential of venture ideas in non-R&D-intensive sectors such as consumer web and enterprise software. Finally, we find that industry-specific and scientific expertise is not critical to experts’ collective ability to predict ventures’ commercial viability.
- Nice article on How does a relational database work from Coding Geek. Brings together lots of information into one place.
- How many classes should an application have? Someone discovered that the Facebook iOS application is composed of over 18,000 classes. It's the same answer as: how long is a piece of string?
- I wish we could do this to code. Who hasn't wanted to torture the truth out of code? But will torturing code for answers yield the answers you so desire? No, Torture Doesn’t Make Terrorists Tell The Truth: Central to this approach is the “cognitive interview,” developed by Ronald Fisher, a psychologist at Florida International University in Miami. Rather than being asked a series of questions, suspects may be told to close their eyes and recall what happened at a key meeting, or draw a sketch of the room in which it took place. They are encouraged to go over events repeatedly and offer details whether or not they seem important.
- Lots of good information on How to monitor NGINX with Datadog.
- Is the step after scheduling at the datacenter level letting tasks organize themselves across a gradient of datacenter resources? Robots Discover How Cooperative Behavior Evolved in Insects: For both large and small groups of robots, the most efficient strategy is task specialization...what’s so fascinating about this research is that it shows how complex, organized division of labor between individuals can be evolved from extremely simple, basic behaviors, even when every robot starts with the exact same set of basic behavioral genes.
- Why is Bitcoin forking? Reasonable traffic projections indicate that as Bitcoin spreads via word of mouth, we will reach the limit of the current system some time next year, or by 2017 at the absolute latest. And another bubble or press cycle could push us over the limit before even that. The result might not be pretty.
- Queues Don’t Matter When You Can JUMP Them!: We show that QJUMP achieves bounded latency and reduces in-network interference by up to 300×, outperforming Ethernet Flow Control (802.3x), ECN (WRED) and DCTCP.
- GraM: Scaling Graph Computation to the Trillions: GRAM is also capable of processing graphs that are significantly larger than previously reported. In particular, using 64 servers (1,024 physical cores), it performs a PageRank iteration in 140 seconds on a synthetic graph with over one trillion edges, setting a new milestone for graph engines. GRAM’s efficiency and scalability comes from a judicious architectural design that exploits the benefits of multicore and RDMA. GRAM uses a simple message-passing based scaling architecture for both scaling up and scaling out to expose inherent parallelism.
-
Laissez-Faire : Fully Asymmetric Backscatter Communication: In this paper, we present a new fully asymmetric backscatter communication protocol where nodes blindly transmit data as and when they sense. This model enables fully flexible node designs, from extraordinarily powerefficient backscatter radios that consume barely a few micro-watts to high-throughput radios that can stream at hundreds of Kbps while consuming a paltry tens of micro-watts.
-
Controllability of complex networks: We show that sparse inhomogeneous networks, which emerge in many real complex systems, are the most difficult to control, but that dense and homogeneous networks can be controlled using a few driver nodes. Counterintuitively, we find that in both model and real systems the driver nodes tend to avoid the high-degree nodes.
- SerenityDB: implements basic Redis commands and extends them with support of Consistent Cursors, ACID transactions, Stored procedures, etc.
- CurioDB: distributed and persistent Redis clone, built with Scala and Akka.
- JSONWire: may be a very good choice for performance, especially where consistent low latency through ultra low garbage production is required.



