Stuff The Internet Says On Scalability For August 7th, 2015

Hey, it's HighScalability time:
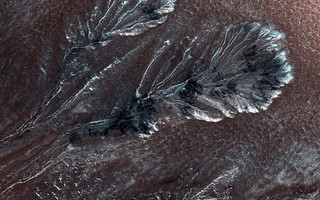
A feather? Brass relief? River valley? Nope. It's frost on mars!
- $10 billion: Microsoft data center spend per year; 1: hours from London to New York at mach 4.5; 1+: million Facebook requests per second; 25TB: raw data collected per day at Criteo; 1440: minutes in a day; 2.76: farthest distance a human eye can detect a candle flame in kilometers.
- Quotable Quotes:
- @drunkcod: IT is a cost center you say? Ok, let's shut all the servers down until you figure out what part of revenue we contribute to.
- Beacon 23: I’m here because they ain’t made a computer yet that won’t do something stupid one time out of a hundred trillion. Seems like good odds, but when computers are doing trillions of things a day, that means a whole lot of stupid.
- @johnrobb: China factory: Went from 650 employees to 60 w/ robots. 3x production increase. 1/5th defect rate.
- @twotribes: "Metrics are the internet’s heroin and we’re a bunch of junkies mainlining that black tar straight into the jugular of our organizations."
- @javame: @adrianco I've seen a 2Tb erlang monolith and I don't want to see that again cc/@martinfowler
- @micahjay1: Thinking about @a16z podcast about bio v IT ventures. Having done both, big diff is cost to get started and burn rate. No AWS in bio...yet
- @0xced: XML: 1996 XLink: 1997 XML-RPC: 1998 XML Schema: 1998 JSON: 2001 JSON-LD: 2010 SON-RPC: 2005 JSON Schema: 2009
- Inside the failure of Google+: What people failed to understand was Facebook had network effects. It’s like you have this grungy night club and people are having a good time and you build something next door that’s shiny and new, and technically better in some ways, but who wants to leave? People didn't need another version of Facebook.
- @bdu_p: Old age and treachery will beat youth and skill every time. A failed attempt to replace unix grep
- The New World looks a lot like the old Moscow. The Master of Disguise: My Secret Life in the CIA: we assume constant surveillance. This saturation level of surveillance, which far surpassed anything Western intelligence services attempted in their own democratic societies, had greatly constrained CIA operations in Moscow for decades.
- How Netflix made their website startup time 70% faster. They removed a lot of server side complexity by moving to mostly client side rendering. Java, Tomcat, Struts, and Tiles were replaced with Node.js and React.js. They call this Universal JavaScript, JavaScript on the server side and the client side. "Using Universal JavaScript means the rendering logic is simply passed down to the client." Only a bootstrap view is rendered on the server with everything else rendered incrementally on the client.
- How Facebook fights spam with Haskell. Haskell is used as an expressive, latency sensitive rules engine. Sitting at the front of the ingestion point pipeline, it synchronously handles every single write request to Facebook and Instagram. That's more than one million requests per second. So not so slow. Haskell works well because it's a purely functional strongly typed language, supports hot swapping, supports implicit concurrency, performs well, and supports interactive development. Haskell is not used for the entire stack however. It's sandwiched. On the top there's C++ to process messages and on the bottom there's C++ client code interacts with other services. Key design decision: rules can't make writes, which means an abstract syntax tree of fetches can be overlapped and batched.
- You know how kids these days don't know the basics, like how eggs come from horses or that milk comes from chickens? The disassociation disorder continues. Now Millions of Facebook users have no idea they’re using the internet: A while back, a highly-educated friend and I were driving through an area that had a lot of data centers. She asked me what all of those gigantic blocks of buildings contained. I told her that they were mostly filled with many servers that were used to host all sorts of internet services. It completely blew her mind. She had no idea that the services that she and billions of others used on their phones actually required millions and millions of computers to transmit and process the data.
- History rererepeats itself. Serialization is still evil. Improving Facebook's performance on Android with FlatBuffers: It took 35 ms to parse a JSON stream of 20 KB...A JSON parser needs to build a field mappings before it can start parsing, which can take 100 ms to 200 ms...FlatBuffers is a data format that removes the need for data transformation between storage and the UI...Story load time from disk cache is reduced from 35 ms to 4 ms per story...Transient memory allocations are reduced by 75 percent...Cold start time is improved by 10-15 percent.
- Really nice overview. The world beyond batch: Streaming 101. Literally too much to gloss. And wait, there's more: High-throughput, low-latency, and exactly-once stream processing with Apache Flink.
- Ivan Pepelnjak asks Can virtual routers compete with physical hardware? No: While the software-only forwarding process can reach 200 Gbps or more on a multi-core Xeon server, you cannot get anywhere close to the pps-per-$ price point of equivalent hardware solution.
- Perhaps not the best approach for products in the meat world. What went wrong at Quirky?: Rule #4: F*ck it, ship it. Then iterate As the venture capital flowed, Quirky moved fast and sold broken things. The company cut deals with the big box retailers which essentially allowed them to take Quirky inventory on consignment with full return. Of one $10 million order shipped last fall, sources say, $9 million’s worth came back.
- A deliciously daring deep dive on deep links. Will Deep Links Ever Truly Be Deep? My answer: no. Web pages had the properties of transitivity and discoverability enabled by an open data format. Someone could discover a page, get a URL, and link to that URL. Someone could then follow those links and read the content from anywhere. None of that applies to mobile apps.
- A very well written series. Let’s Build A Web Server. Part 3. It covers the why as well as the how. A must read.
- Are your messaging protocols getting complicated? That's just natural. Take a trip through the brain: The complexity of the brain is much more than what we had ever imagined. We had this clean idea of how there's a really nice order to how neurons connect with each other, but if you actually look at the material it's not like that. The connections are so messy that it's hard to imagine a plan to it, but we checked and there's clearly a pattern that cannot be explained by randomness.
- Scale Invariance: A Cautionary Tale Against Reductionism: One possible explanation is that the brain lacks a privileged scale because its functioning cannot be reduced to component parts (i.e., neurons). Rather, it is the complex interactions between parts which give rise to phenomena at all spatial and temporal scales.
- Distributed Frontera: Web Crawling at Scale. Going from a single threaded system to a distributed system using HBase, Python, and Kafka. Code is available here.
- Brendan Gregg with impressive tour of a bevy Linux performance tools used at Netflix. It includes 90 minutes on methodologies, tools, and live demonstrations. Brendan is first rate and is not to be missed.
- A little golang way: By porting some of our microservices from Java to Go, we reduced their resident memory footprint by orders of magnitude.
- Killing the Storage Unicorn: Purpose-Built ScaleIO Spanks Multi-Purpose Ceph on Performance: Dialing down your storage needs to a small handful of silos would probably have a dramatic effect on operational costs! What if you only had something like this in each datacenter: Scalable distributed block storage, Scalable distributed object storage, Scalable distributed file system storage, Scalable control plane that manages all of the above. There isn’t any significant advantage in driving these four systems down to one. The real optimization is from tens or hundreds of managed systems to a handful.
- We are all made of lasers. Living lasers made by injecting oil droplets into human cells.
-
ZooKeeper Part 1: the Swiss army knife of the distributed system engineer. Nice coverage of some practical concerns.
- Amazon Aurora Performance, as a NoSQL store: A db.r3.8xlarge was able to do 1639 puts per second and 6900 gets per second. If we ran a db.r3.8xlarge is would cost us $4.64/hour in US East, or about $3390 per month. The same performance on DynamoDB, given 64 kB blobs would almost be a whopping $60k per month! It’s not 28x, but still a massive difference.
- GitXiv: a space to share collaborative open computer science projects. Countless Github and arXiv links are floating around the web. Its hard to keep track of these gems. GitXiv attempts to solve this problem by offering a collaboratively curated feed of projects.
- Eli-Index: Ranked Prefix Search for Large Data on External Memory optimized for Mobile with ZERO lag initialization time.
- On the Criteria To Be Used in Decomposing Systems into Modules: The unconventional decomposition, if implemented with the conventional assumption that a module consists of one or more subroutines, will be less efficient in most cases. An alternative approach to implementation which does not have this effect is sketched.
- Buzz: An Extensible Programming Language for Self-Organizing Heterogeneous Robot Swarms: We present Buzz, a novel programming language for heterogeneous robot swarms. Buzz advocates a compositional approach, offering primitives to define swarm behaviors both from the perspective of the single robot and of the overall swarm. Single-robot primitives include robot-specific instructions and manipulation of neighborhood data. Swarm-based primitives allow for the dynamic management of robot teams, and for sharing information globally across the swarm.



