The Story of Batching to Streaming Analytics at Optimizely
The original contributor to this article was David Yu, Distributed Systems Engineer at Optimizely.
Our mission at Optimizely is to help decision makers turn data into action. This requires us to move data with speed and reliability. We track billions of user events, such as page views, clicks and custom events, on a daily basis. To provide our customers with immediate access to key business insights about their users has always been our top most priority. Because of this, we are constantly innovating on our data ingestion pipeline.
In this article we will introduce how we transformed our data ingestion pipeline from batching to streaming to provide our customers with real-time session metrics.
Motivations
Unification. Previously, we maintained two data stores for different use cases - HBase is used for computing Experimentation metrics, whereas Druid is used for calculating Personalization results. These two systems were developed with distinctive requirements in mind:
|
Experimentation |
Personalization |
|
Instant event ingestion |
Delayed event ingestion ok |
|
Query latency in seconds |
Query latency in subseconds |
|
Visitor level metrics |
Session level metrics |
As our business requirements evolve, however, things quickly became difficult to scale. Maintaining a Druid + HBase Lambda architecture (see below) to satisfy these business needs became a technical burden for the engineering team. We need a solution that reduces backend complexity and increases development productivity. More importantly, a unified counting infrastructure creates a generic platform for many of our future product needs.
Consistency. As mentioned above, the two counting infrastructures provide different metrics and computational guarantees. For example, Experimentation results show you the number of visitors visited your landing page whereas Personalization shows you the number of sessions instead. We want to bring consistent metrics to our customers and support both type of statistics across our products.
Real-time results. Our session based results are computed using MR jobs, which can be delayed up to hours after the events are received. A real-time solution will provide our customers with more up-to-date view of their data.
Druid + HBase
In our earlier posts, we introduced our backend ingestion pipeline and how we use Druid and MR to store transactional stats based on user sessions. One biggest benefit we get from Druid is the low latency results at query time. However, it does come with its own set of drawbacks. For example, since segment files are immutable, it is impossible to incrementally update the indexes. As a result, we are forced to reprocess user events within a given time window if we need to fix certain data issues such as out of order events. In addition, we had difficulty scaling the number of dimensions and dimension cardinality, and queries expanding long period of time became expensive.
On the other hand, we also use HBase for our visitor based computation. We write each event into an HBase cell, which gave us maximum flexibility in terms of supporting the kind of queries we can run. When a customer needs to find out “how many unique visitors have triggered an add-to-cart conversion”, for example, we do a scan over the range of dataset for that experimentation. Since events are pushed into HBase (through Kafka) near real-time, data generally reflect the current state of the world. However, our current table schema does not aggregate any metadata associated with each event. These metadata include generic set of information such as browser types and geolocation details, as well as customer specific tags used for customized data segmentation. The redundancy of these data prevents us from supporting large number of custom segmentations, as it increases our storage cost and query scan time.
SessionDB
Since it became difficult to optimize our Druid indexes, we decided to obsolete the Druid route and focus on improving our HBase data representation. Pre-aggregating events and compacting away redundant information became the most obvious next step. This was when we turned to Samza for help.
Samza is a perfect fit for our needs thanks to its seamless integration with Kafka - our distributed message queue. We will get to the details of how this real-time aggregation works in part two. But on a very high level, Samza continuously bundles events into sessions and periodically streams out snapshots of the pending sessions into HBase. With this approach, each HBase cell becomes a consolidated view of a group of events.
There are several advantages to this. First being that, our core logic for computing various statistics very much stays the same. Given the fact that majority of the base calculations we do are summations (an oversimplification of course), adding a bunch of ones together is equivalent of summing a list of cumulative values.
The second benefit we get is that, with session level information immediately available, we can start querying session metrics right off of HBase and answer questions, such as “what is the average revenue generated per user session”, in real-time! This newly created HBase schema is unsurprisingly named SessionDB, which became the basis of backend unification.
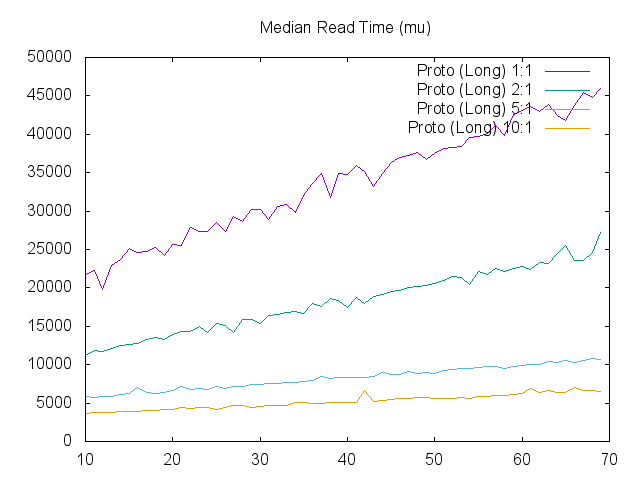
Last but not least, the HBase storage requirement is drastically reduced and queries run much faster. By aggregating session level metadata, we no longer have to replicate information, such as browser types, locations and user dimensions, across each cell. The graph below shows the average query latency (x-axis) given different number of user dimensions (y-axis). With an average of 10 events per session, for example, the median query latency drops to 5 ms as opposed to 40+ ms (the yellow line).
Background
Session aggregation (AKA sessionization) was not the first stream processing use case at Optimizely. We have been applying stream processing for various ETL tasks, such as:
Data enrichment (backfilling missing metadata for events)
Event stream repartition (for various downstream use cases)
Real-time experiment metrics (count number of events received for each experiment)
There are several production ready stream processing frameworks available today, including Samza, Spark, Storm and Flink. We chose Samza because of several reasons. First, Samza allows you to create a processing topology by chaining together kafka topics, which offers high isolation. As we encourage our engineers to explore different processing ideas, this pluggability creates the minimal ripple effect to our overall data pipeline. Secondly, Samza can be easily integrated into Kafka and YARN, which are what we use heavily. In addition, Samza is very low latency. It provides a simple programming model and easy to use state management framework, all of which fit well with many our needs.
What is Apache Samza?
On a very high level, a Samza job consumes a stream of immutable events from one or more Kafka topics. It then does some kind of computation to these events, one at a time, and writes outputs into one or more downstream Kafka topics.
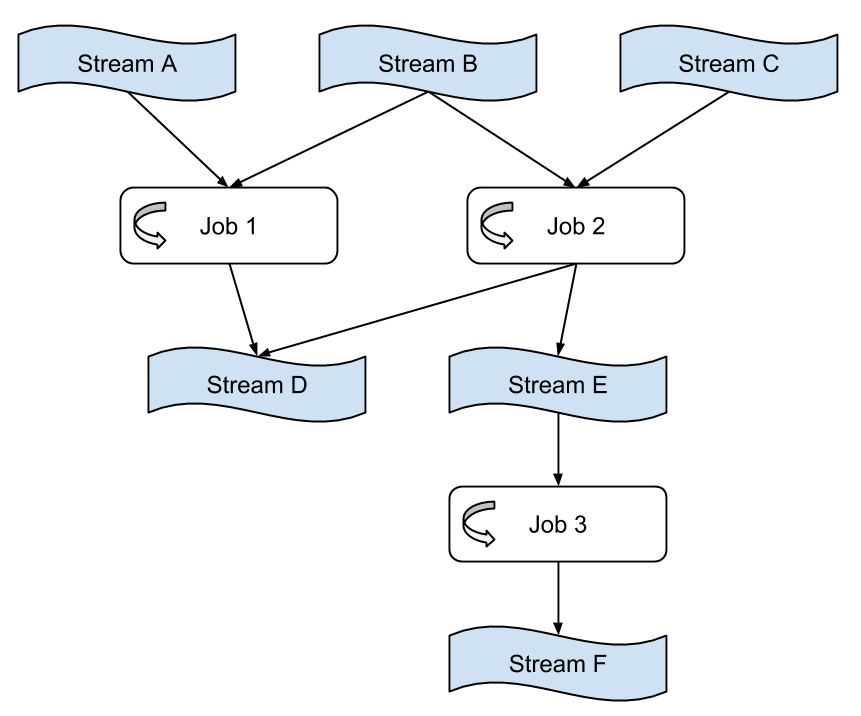
One noticeable characteristic of Samza jobs is that, they are highly composable. To help you visualize what Samza jobs are capable of, you can think of them as a bunch of real-time MR jobs, chained together by Kafka topics. The above diagram shows you how a job can have multiple input streams and how several jobs are connected to form a complex workflow.
Samza is scalable, fault-tolerant and stateful. We are going to briefly touch each of these three aspects, since our sessionization job takes advantage of all these features to some extend.
Scalability. Just like MR jobs, Samza jobs are also highly concurrent and scalable. The difference lies in that, Samza parallelism is partition-oriented as opposed to file-oriented. A job is divided into multiple tasks. As analogous to MR, a Samza task is roughly equivalent to a mapper + reducer. A task “maps” events by funneling them into designated Kafka topic partitions. At the same time, events from an input stream partition all go to a single task, mimicking the behavior of a reducer.
One important aspect to keep in mind is that, an input topic partition is statically assigned to a task instance. The number of task instances, thus, is directly related to the max number of partitions of any given input topic (illustrated in an example below). The first time you submit a job, this mapping is created and persisted into a Kafka topic for fault-tolerance. The coupling helps simplify Samza’s state management model (which we’ll cover later), since each task only needs to manage its own state.
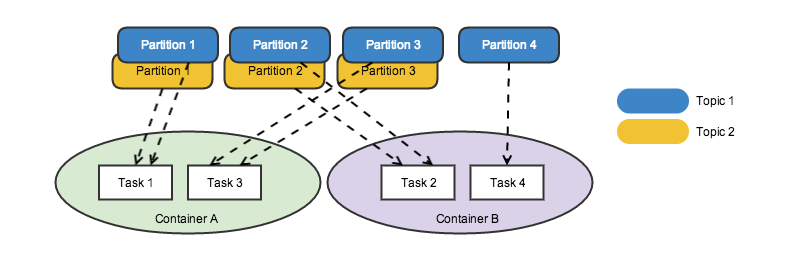
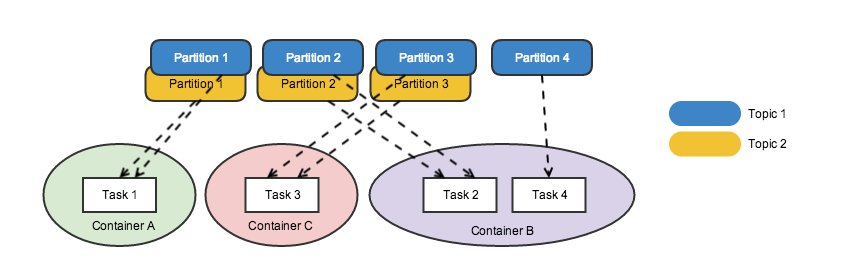
With a fixed number of tasks, how can we scale out? A Samza job can scale out by increasing the number of running containers. When running on a YARN cluster, the only distributed environment supported to run Samza currently, each task instance executes in a container - a single unit of computational resource. Depending on how much computational power a task demands, you can run everything within a single container, or you can create as many containers as tasks, providing the maximum power for each task. The diagram above demonstrates this kind of elasticity.
Fault-tolerance. Samza promises that, if a container dies for whatever reason, tasks within that container will be able to recover from where they left off once a new container launches. To do this correctly, Samza periodically bookmarks/checkpoints the offsets at which the tasks are consuming from. It also does this for changes made to its internal state stores. With all of this information logged to Kafka, a job recovery can be done by consuming and replaying this stream of changes to reconstruct various internal job states.
Statefulness. Most stream processing needs to store some kind of states, whether it be the number of events for a given user if you are generating user metrics, or in our case, all the events triggered within a given session. To make stream processing truely real-time, it is impractical to store these states anywhere other than local to the task. Out of the box, Samza provides RocksDB as an efficient KV store (like an embedded HBase) to track states too large to fit into the local memory. As mentioned above, this store is also recoverable on a task failure, thanks to the changes it persists in a changelog topic.
With all of the basic concepts of Samza in mind, we can now move on to introduce how we leverage this tool to continuously roll up events into sessions.
Implementation
A session is simply a series of user events triggered in a relatively quick succession. To provide different types of session demarcations, we ask our upstream clients to assign a session id for each event. Typically, all events are assigned the same session id if they are created less than 30 minutes apart.
The main Samza event loop for aggregating events then becomes quite straightforward. The job maintains a per task KV store using the session ids as keys. Upon receiving an event, the job does a lookup in the KV store. It either creates a new session if the session id does not exist or updates the session otherwise. The update is where most of the consolidation happens. The common set of metadata (e.g. ip address, location information, browser version, etc) is aggregated at the top level, whereas event specific ones (e.g. event type, add to cart dollar amount, etc) are preserved as a list.
As introduced in the previous post, each HBase cell now stores a session. To keep overwriting the cells with the latest copies of the sessions, we need to continuously flush snapshots of the KV store into a Kafka topic.
One important question we asked earlier in our design was, how frequently should we snapshot the ongoing sessions to keep our HBase updated? We could do this as soon as a session is updated after processing an event. The benefit of doing so is that it minimizes session update latency and produces truly real-time results. The downside, however, is that it also creates a large number of session updates, which significantly increases our Kafka load. Instead, we leveraged the windowing feature of Samza and batch one minute worth of session updates before flushing into HBase. If a user triggers 10 click events within 60 seconds, for example, we write out a single session snapshot with 10 events at the end of the minute, instead of 10 session snapshots. This greatly reduced the amount of data sent through the wire.
Challenges and lessons
As straightforward as the sessionization logic sounds, we did encounter various challenges during our sessionization development.
Iterating through RocksDB affects job throughput. As mentioned above, Samza windowing needs to traverse the list of all pending sessions when writing out the session snapshots. Due to the fact that each Samza process is single threaded (future Samza releases will introduce multi-threaded processing), the actual event processing will be blocked until windowing is finished. This means that, in extreme cases, if windowing takes longer than the configured windowing interval, the event loop will not have a chance to process any actual events. When that happens, you will observe a high window-ns and zero process-envelopes count. To prevent this, you will have to make windowing run as efficiently as possible and probably want to avoid frequent full scans of RocksDB. In our case, we achieved this by keeping a stripped down version of the KV store in memory just for this purpose. Traversing a plain old hash table is a lot faster than over the on disk KV store after all.
Be careful with Kafka log compaction. The log compaction feature allows Kafka to strategically remove log entries instead of a simple truncate at the tail of each partition. A log compacted topic will only retain the last known value of each key. If that value is null, Kafka removes that key after a configured retention time. First of all, if you are using an older version of Kafka (e.g. 0.8.2), make sure that log.cleaner.enable is set to true. Otherwise, some of the Samza topics such as checkpoints and changelogs will not be compacted. We figured this out when during a redeployment, the job took hours to resume processing. It turned out that it needed to consume TBs of uncompacted changelogs to materialize each KV store.
Another lesson we learned regarding log compaction is that, you should not produce to a log compacted topic if no deletion takes place. The gotcha here is that, log.retention.bytes does not apply to log compacted topics at all. We learned this the hard way when our output topic grows unbounded and exhausted our Kafka disk space.
Use SSDs for RocksDB. During our development, we noticed that, once in awhile, a subset of the tasks would have a hard time keeping up with the rate at which events are received. Further investigation revealed somewhat longer process-ns and window-ns time on these tasks. It turned out that these tasks were having slower interactions with the underlying RocksDB stores due to the type of disks configured on the YARN instances. The containers of these tasks were deployed on Node Managers that used EBS drives. Since RocksDB is highly optimized to run fast compactions in fast storage like SSD or RAM, using EBS significantly reduced performance for RocksDB IO.



