Stuff The Internet Says On Scalability For December 16th, 2016

Hey, it's HighScalability time:
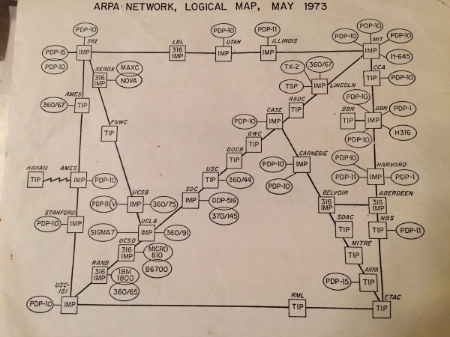
This is the entire internet. In 1973! David Newbury found the map going through his dad's old papers.
If you like this sort of Stuff then please support me on Patreon.
- 2.5 billion+: smartphones on earth; $36,000: loss making a VR game; $1 million: spent playing Game of War; 2000 terabytes: saved downloading Font Awesome's fonts per day; 14TB: new hard drives; 19: Systems We Love talks; 4,600Mbps: new 802.11ad Wi-Fi standard;
- Quotable Quotes:
- Thomas Friedman: [John] Doerr immediately volunteered to start a fund that would support creation of applications for this device by third-party developers, but Jobs wasn’t interested at the time. He didn’t want outsiders messing with his elegant phone.
- Fastly: For every problem in computer networking there is a closed-box solution that offers the correct abstraction at the wrong cost.
-
ben stopford: The Data Dichotomy. Data systems are about exposing data. Services are about hiding it.
-
Ernie: just as Amazon invaded the CDN ecosystem with CloudFront and S3, CDNs are going to invade the cloud compute space of AWS.
- The Attention Merchants: When not chronicling death in its many forms, Bennett loved to gain attention for his paper by hurling insults and starting fights. Once he managed in a single issue to insult seven rival papers and their editors. He was perhaps the media’s first bona fide “troll.” As with contemporary trolls, Bennett’s insults were not clever.
- @swardley: "Serving 2.1 million API requests for $11" not bad at all. My company site used to cost £19 pcm
- hibikir: I don't know about Uber, but I've worked at a lot of places that had sensitive data. A common patterns is to fail to treat employees like attackers, and protect data in ways that are very beatable by a motivated employee.
- @davecheney: OH: lambdas are stored procedures for millenials.
- @jamesurquhart: This. Containers will play a huge role in low-level service deployments, but not user facing (e.g. “consumer”) app deployments (5-7 years).
- theptip: Geo-redundancy seems like a luxury, until your entire site comes down due to a datacenter-level outage. (E.g. the power goes down, or someone cuts the internet lines when doing construction work on the street outside).
- Resilience Thinking: The ruling paradigm-that we can optimize components of a system in isolation of the rest of the system-is proving inadequate to deal with the dynamic complexity of the real world.
- Eliezer Steinbock: Disconnect users when they’ve just left their tab open. It’s so simple to do and saves precious resources
- @ieatkillerbees: In 20 years of engineering I've never said, "thank goodness we hired someone who can reverse a b tree on a whiteboard while strangers watch"
- Rushkoff: I think as people realize they can’t get jobs in this highly centralized digital economy, as companies realize that it might be better to beat them than join them, I think we will see the retrieval of some of these earlier networking values.
- Darren Cibis: I think BigQuery is the better product at this stage, however, it’s had a big head start over Athena which has a lot of catching up to do.
- Fastly: Over the span of a day, IoT devices were probed for vulnerabilities 800 times per hour by attackers from across the globe.
- Quantum Gravity Research Could Unearth the True Nature of Time: somehow, you can emerge time from timeless degrees of freedom using entanglement.
- @SystemsWeLove: "You can think of the OS as the bouncer at Club CPU: if a VIP comes in and buys up the place, you're out." -- @arunthomas #systemswelove
- Erik Darling: When starting to index temp tables, I usually start with a clustered index, and potentially add nonclustered indexes later if performance isn’t where I want it to be.
- Customers Don’t Give a Shit About Your Data Centers: My youngest daughter co-developed an Alexa skill called PotterHead. By taking advantage of the templates and how-to instructions, the skill was designed, developed, tested, and deployed within 24 hours — without a data center or any knowledge of ansible, git, jenkins, chef, or kubernetes.
- In summary: mobile is [still] eating the world, everything is changing, nobody knows where it will all end up. And people are scared. Interesting observation on the new scale: Facebook, Amazon, Apple, and Google are 10x bigger than Microsoft & Intel when they were changing the world.
- Bigger is not always better when it comes to datacenters. AWS re:Invent 2016: Tuesday Night Live with James Hamilton. Amazon could easily build 200 megawatt (MW) facilities, yet they choose to build mostly 32MW facilities. Why? The data tells them to. What does the data say? The law of diminishing returns. The cost savings don't justify having a larger failure domain. When you start small and scale up a datacenter you get really big gains in cost advantage. As you get bigger and bigger it's a logarithm. The gains of going bigger are relatively small. The negative gain of a big datacenter is linear. If you have a 32MW datacenter tha's about 80k servers it's bad if it goes down, but it can be handled so that it's unnoticeable. If a datacenter with 500K server goes down the amount of network traffic needed to heal all the problems is difficult to handle.
- My Accidental 3–5x Speed Increase of AWS Lambda Functions. Here's the secret: The more memory I choose the more CPU I get.
- Amazing detail. Proposed server purchase for GitLab.com. A great resource if you are thinking of going bare metal. They go into their choices for networking, servers, CPU, disks, rack, hosting, etc, all that is needed to support 96TB of data that is growing rapidly. It's obviously a lot of work. Is it a win? Currently cloud hosting is costing about $200k per month. They calculate it will be 10x cheaper to host their own. Good discussion on HackerNews. A common concern is this is probably not a core competency of GitLab. The GitLab CEO chimed in: Hardware and hosting are certainly not our core competencies. Hence all the questions in the blog post. And I'm sure we made some wrong assumptions on top of that. But it needs to become a core competency, so we're hiring
- Introducing Consus: Fast Geo-Replicated Transactions (paper, source code): Consus is a strictly serializable geo-replicated transactional key-value store. The key contribution of Consus is a new commit protocol that reduces the cost of executing a transaction to three wide area message delays in the common case...Consus enables efficient wide area transactions that are within 50% of the minimum required for any form of safe replication...If your data centers were equidistant from each other with a uniform round trip time of 100ms between any pair of data centers, Consus could commit each transaction with 150ms of wide area latency...Internally, the system uses four different variants of Paxos and three more variants of replication that are weaker than Paxos.
- Choice of language does inform your hardware choices. sytse: We're considering the fat twins so we get both a lot of CPU and some disk. GitLab.com is pretty CPU heavy because of ruby and the CI runners that we might transfer in the future. So we wanted the maximum CPU per U.
- Excellent deep dive. Building and scaling the Fastly network, part 2: balancing requests: Faild is a synthesis of both approaches: leveraging hardware processing on commodity switches where possible, and pushing out flow handling towards hosts when necessary. The result of this division of labor is a virtually stateless, distributed load balancer. Faild is highly efficient and inherently reliable, ensuring that established flows are never spuriously reset. It achieves this by lying compulsively to the hardware it talks to while incurring no additional state than would otherwise be required by TCP. In devising a solution which would cost us less, we ended up with a system that costs us nothing.
- Calling a service is easy. Calling a whole bunch of services in sequence and in parallel while handling errors is hard. That's why Netflix built Conductor (source): A microservices orchestrator. It looks full featured and it makes the job of the programmer so much easier. To data Netflix has run 2.6 Million workflows, the largest of which is 48 tasks and the average number of tasks per workflow is 6. Managing the interaction of 6 tasks is a pain to code. See also, AWS Step Functions.
- Eric Hammond gives an accounting. How Much Does It Cost To Run A Serverless API on AWS? Serving 2.1 million API requests for $11. API Gateway was by far the biggest cost.
- The Allen Telescope Array is the idea of array of independent disks applied to telescopes. They use an array of a large number of small dishes, eventually 350, with the collecting area equivalent to a single dish 114 meters in diameter. They use commercial technology wherever possible and employs programmable chips and software for signal processing. This feels like a general pattern.
- Javascript, Java, Ruby, PHP, Pythion, CSS, C++, C#, C. Top languages on GitHub.
- Crazy for microservices or crazy to use microservices? Microservices? Please, Don't. The idea is that you should use microserves When you’re ready as an engineering organization. They aren't a good default architecture as represented by the five fallacies: Fallacy #1: Cleaner Code; Fallacy #2: It’s Easier; Fallacy #3: It’s Faster; Fallacy #4: Simple for Engineers; Fallacy #5: Better for Scalability.
- The 69GB Stanford Drone Dataset: the very first large scale dataset (to the best of our knowledge) that collects images and videos of various types of agents (not just pedestrians, but also bicyclists, skateboarders, cars, buses, and golf carts) that navigate in a real world outdoor environment such as a university campus. In the above images, pedestrians are labeled in pink, bicyclists in red, skateboarders in orange, and cars in green.
- Here's how search serving and ranking works at Pinterest. You really get to see how a service can be composed of a complex service pipeline yet still perform well. The query goes through a sequence that performs spell correction, query segmentation, query expansion, and other transforms to produce a structure query. The query processing consists of a number of blending and reranking processes.
- Some interesting results. PacketZoom’s New Mobile Benchmarking Study Analyzes Mobile Network and App Performance: AT&T has the lowest number of TCP drops in the US (2.94% vs. Verizon with 3.66%); Sprint is far behind with over 5% of disconnects; Verizon response time is almost 30% faster than AT&T
- Joe Beda has a multi-part series on on Cloud Native you might find helpful. Cloud Native: allows for big problems to be broken down into smaller pieces for more focused and nimble teams; automates much of the manual work that causes operations pain and downtime; more reliable infrastructure and applications; tools provide much more insight into what is happening within an application; enables application developers to play an active role in creating securable applications; opens up opportunities to apply algorithmic automation.
- Is this the Next Billion Dollar Market for CDN Industry? Not until it gets a hell of a lot easier to program. EC-CDN = Application Logic + Database + Data at the Edge: the idea of having application business logic + database + data residing at the edge, not in Availability Zones. Thus, the CDN will place caching servers and application logic + database + data, at the PoP. The processing of request/response will take place at the last mile, not over the first-mile + middle-mile + last mile like it does in the AWS ecosystem. The delivery of dynamic content from the edge, without ever having to go back to origin, is the future.
- This is scary. GitHub lost $66M in nine months of 2016. GitHub is not too big to fail and its failure would be the death of the coral reef amongst which many beings dwell. Do you have a plan if GitHub bleaches out?
- A nice quick Introduction to Parallel Computing by Blaise Barney from the Lawrence Livermore National Laboratory.
- Essential knowledge if you are building on somebody else's storage system. Consistency Models of Cloud Storage Services. Read-after-write: Dropbox, Google Drive, Box, Egnyte, Azure. Eventual: OneDrive, S3, Rackspace. Mixed: Google cloud.
- Another conversation in the never ending debate. At least the conversations are at a high technical level. REST in Peace: Monolith vs Microservices in examples. It's use the right tool for the job with examples of which tool to use for which jobs. The strongest point is how distributed transactions exist in monoliths as well. You are already using distributed transactions if you are using an external Payment system, multiple sign-on mechanisms, calling third-party SaaS products, leveraging Cloud APIs, or workflows spanning multiple user stages/screens/requests.
- We have an early review...Amazon Lightsail 1GB is no match for $10 VPS from Linode, DO, Vultr. TLDR: Amazon Lightsail 1GB will melt down with less than 15% sustained cpu usage. nodesocket: Not surprised, Lightsail servers are just t2 burst instances rebranded. Honestly, even using EC2 c4 (compute) or r3 (memory) instances it is hard to match the benchmarks of larger DigitalOcean droplets in terms of I/O. EBS is just really hard to get performance out of unless you use local disks and storage optimized instances. Walkman: As far as I understand, the advantage of Lightsail is that you get access to the rest of the AWS services, NOT it's price or pure simplicity.
- Multi-tenancy after 10 years of Cloud Computing: An multi-tenant App in the Cloud needs to manage three types of resources: executions, data storage, and OLAP batch executions ( analytics). We explored each and saw that the executions are converging towards containers and data bases towards multi-tenant databases.
- Programming Line-Rate Routers: This talk will focus on two abstractions for programming such chips. The first abstraction, packet transactions, lets programmers express packet processing in an imperative language under the illusion that the switch processes exactly one packet at a time. A compiler then translates this sequential programmer view into a pipelined implementation on a switching chip that processes multiple packets concurrently. The second abstraction, a push-in first-out queue, allows programmers to program new scheduling algorithms using a priority queue coupled with a program to compute each packet's priority in the priority queue. For the first time, these two abstractions allow us to program several packet-processing functions at line rate. These packet-processing functions include in-network congestion control, active queue management, data-plane load balancing, network measurement, and packet scheduling.
- Sargun Dhillon with a great exploration of time in On Time. It's more complex than you think: Recently, AugmentedTime, and Hybrid Logical Clocks have been proposed as a compromise between wall clock time, and logical time. Hybrid Logical Clocks take physical time, as the background reference for all events in a system, and combine it with logical time, capturing the causal information required to build a relationship of events. AugmentedTime, on the other hand, combines vector clocks and physical time to build a bounded clock based on ε. The aforementioned techniques allow us to avoid the data loss bugs which have become ever so common.
- Jolie: a service-oriented language.
- anaibol/awesome-serverless: A curated list of awesome services, solutions and resources for serverless / nobackend applications.



