Building nginx and Tarantool based services
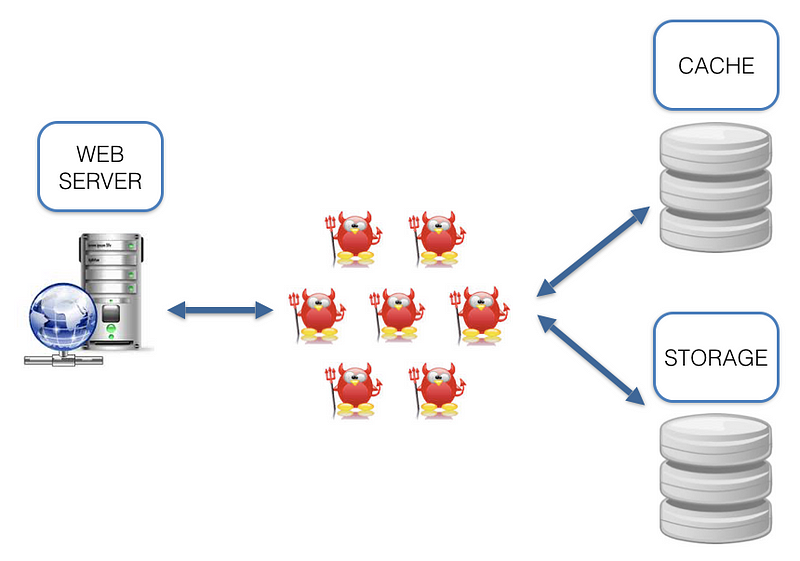
Are you familiar with this architecture? A bunch of daemons are dancing between a web-server, cache and storage.
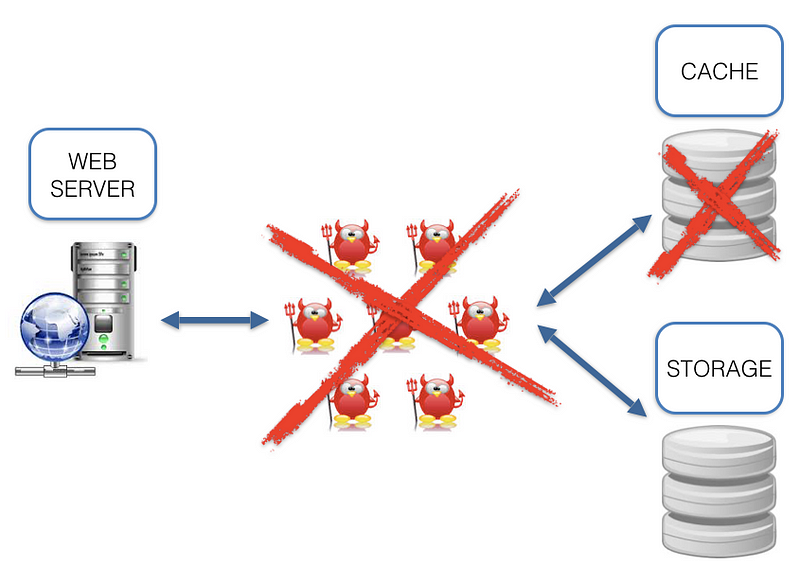
What are the cons of such architecture? While working with it we come across a number of questions: which language (-s) should we use? Which I/O framework to choose? How to synchronize cache and storage? Lots of infrastructure issues. And why should we solve the infrastructure issues when we need to solve a task? Sure, we can say that we like some X and Y technologies and treat these cons as ideological. But we can’t ignore the fact that the data is located some distance away from the code (see the picture above), which adds latency that could decrease RPS.
The main idea of this article is to describe an alternative, built on nginx as a web-server, load balancer and Tarantool as app server, cache, storage.
Improving cache and storage
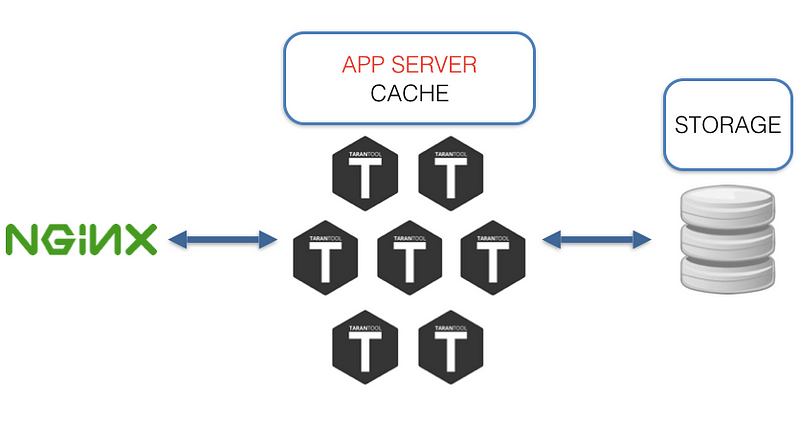
Tarantool has a number of interesting features. Tarantool isn’t just an efficient in-memory DB, but also a fully functional app server; applications are created on Lua (luajit), C, or C++, which means that any logic, no matter how complex, can be created and your fantasy is a limit. If the amount of data exceeds the memory limit, then it can be partially stored on disk using Sophia. Sophia is an optional feature so if you need to use something else then you can store the hot parts of data in-memory and the cold part of data in some other storage system. What are the benefits?
- No “third parties”. The hot data part is located on the same level with the code.
- Hot data in-memory
- Lua applications are simple and easily updated
- Safe and production ready - Tarantool supports transactions, replication, and sharding
Improving web-server
The ultimate data consumer is your user. Usually the user receives data from app server via nginx as a balancer/proxy. The option of creating a daemon capable of communicating with both Tarantool and HTTP wouldn’t work, as it brings us back to the first image where we started. So let’s try to look at this situation from a different angle and ask ourselves another question: “How to get rid of the third party between the data and the user?” The answer to this question was our implementation of the Tarantool nginx upstream module.
About nginx upstream
Nginx upstream is a persistent connection via pipe/socket and backend referred to below as “proxying”. Nginx offers a variety of features for creating the upstream rules; the following possibilities become of key importance for HTTP proxying in Tarantool:
- Load balancing across many Tarantool instances via nginx upstream
- The possibility to have a backup
All these make it possible to:
- Distribute the load across Tarantool instances; for example, together with sharing you can build a cluster with an even load distribution between nodes
- Create a fault tolerance system with the help of Tarantool replication
- Using item 1 and 2 to get a fault tolerance cluster
An example of nginx configuration that partially illustrates the capabilities of Tarantool and nginx:
# Proxying settings in Tarantool
upstream tnt {
server 127.0.0.1:10001; # first server located on localhost
server node.com:10001; # second someplace else
server unix:/tmp/tnt; # third via unix socket
server node.backup.com backup; # here backup
}# HTTP-server
server {
listen 8081 default;
location = /tnt/pass {
# Telling nginx that we need to use Tarantool upstream module
# and specify the name upstream
tnt_pass tnt;
}
}
More information on nginx upstream configuration can be found here: http://nginx.org/en/docs/http/ngx_http_upstream_module.html#upstream
About nginx Tarantool upstream module
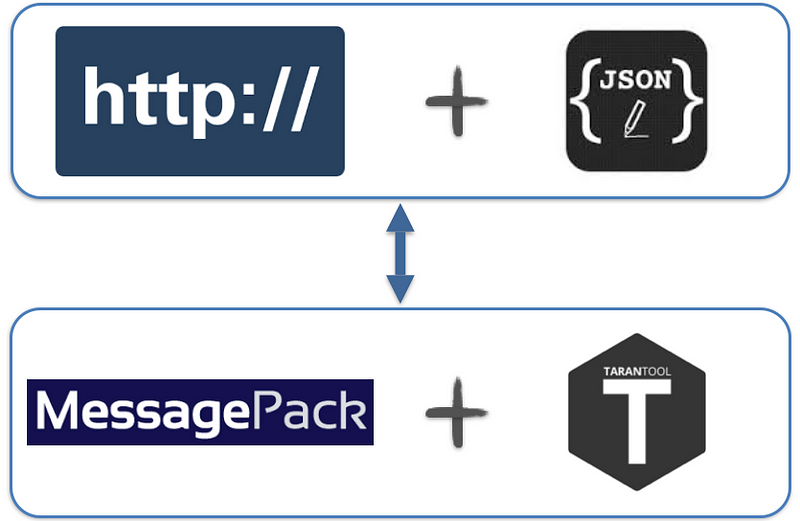
The main features
- The module is activated in nginx.conf by tnt_pass command
- Transform HTTP+JSON to Tarantool protocol
- Non-blocking I/O in both directions
- All nginx and nginx upstream features
- The module allows you invoke stored Tarantool procedures via a JSON-based Protocol
- The data is delivered through HTTP(S) POST, which is convenient for modern web-apps and not only for them
Input data[ { “method”: STR, “params”:[arg0 … argN], “id”: UINT }, …N ]
“method”
The name of a stored procedure. The name should match the procedure name in Tarantool. For example, to invoke the lua-function do_something(a, b), we need: “method”: “do_something”
”params”
The arguments of a stored procedure. For example, to send the arguments to the lua-function do_something(a, b), we need: “params”: [ { “field1”: [ {“a”: ”b”} ], 2 ]
“id”
Numerical identifier; set up by a user
Output data[ { “result”: JSON_RESULT_OBJECT, “id”:UINT, “error”: { “message”: STR, “code”: INT } }, …N ]
“result”
The data returned by a stored procedure. For example, lua-function do_something(a, b) brings back: return {1, 2} то “result”: [[1, 2]]
“id”
Numerical identifier; set up by a user
“error”
In case an error occurs, the information on what caused it will be shown here
Let’s try it
Starting up nginx$ git clone https://github.com/tarantool/nginx_upstream_module.git
$ cd nginx_upstream_module
$ git submodule update -init -recursive
$ git clone https://github.com/nginx/nginx.git
$ cd nginx && git checkout release-1.9.7 && cd -
$ make build-all-debug
“build-all-debug” is a debug-version. We are aiming at less nginx configuration. For those who want to configure from scratch, there is a “build-all”.$ cat test-root/conf/nginx.conf
http {
# Adds one Tarantool server as a backend
upstream echo {
server 127.0.0.1:10001;
}
server {
listen 8081 default; #goes to *:8081
server_name tnt_test;
location = /echo { # on *:8081/echo we send ‘echo’
tnt_pass echo;
}
}
}$ ./nginx/obj/nginx # starting up nginx
Starting up Tarantool
Tarantool can be set up with packages or built.-- hello-world.lua file
-- This is our stored procedure, it’s fairly simple and it doesn’t use Tarantool as a DB.
--All it does — is just returning its first argument.
function echo(a)
return {{a}}
endbox.cfg {
listen = 10001; -- Specifying the location of Tarantool
}box.schema.user.grant('guest', 'read,write,execute') -- Give access
If you set up Tarantool with packages, you can start it up this way:$ tarantool hello-world.lua # the first argument is the name of lua-script.
Invoking the stored procedure
Echo stored procedure can be invoked by any HTTP-connector; all you need to do — HTTP POST 127.0.0.1/echo and in the body there will be the following JSON (see Input Data){
"method": "echo", // Tarantool method name
"params": [
{"Hello world": "!"} // 1 method’s argument
],
"id": 1
}
I’ll invoke this procedure with wget$ wget 127.0.0.1:8081/echo — post-data '{"method": "echo","params":[{"Hello world": "!"}],"id":1}'$ cat echo
{"id":1,"result":[[{"hello world":"!"}]]}
Other examples:
- https://github.com/tarantool/nginx_upstream_module/blob/master/examples/echo.html
- https://github.com/tarantool/nginx_upstream_module/blob/master/test/client.py
Let’s sum it up
The pros of using Tarantool nginx upstream module
- No “third parties”; as a rule, the code and the data are on the same level
- Relatively simple configuration
- Load balancing on Tarantool nodes
- High performance speed, low latency
- JSON-based protocol instead of binary protocol; no need to search for Tarantool driver, JSON can be found anywhere
- Tarantool Sharing/Replication and nginx = cluster solution. But that’s the topic for another article
- The solution is used in production
The cons
- Overhead JSON instead of more compact and fast MsgPack
- It’s not a packaged solution. You need to configure it, to think how to deploy it
Plans
- OpenResty and nginScript support
- WebSocket and HTTP 2.0 support
The benchmark results - which are actually pretty cool- will be in a different article. Tarantool and Upstream Module is open source and welcoming to new users. If you wish to try it out, use it or share your ideas, go to GitHub, google group.
Links
Tarantool — GitHub, Google group



