Google's Transition from Single Datacenter, to Failover, to a Native Multihomed Architecture

Making a system work in one datacenter is hard. Now imagine you move to two datacenters. Now imagine you need to support multiple geographically distributed datacenters. That’s the journey described in another excellent and thought provoking paper from Google: High-Availability at Massive Scale: Building Google’s Data Infrastructure for Ads.
The main idea of the paper is that the typical failover architecture used when moving from a single datacenter to multiple datacenters doesn’t work well in practice. What does work, where work means using fewer resources while providing high availability and consistency, is a natively multihomed architecture:
Our current approach is to build natively multihomed systems. Such systems run hot in multiple datacenters all the time, and adaptively move load between datacenters, with the ability to handle outages of any scale completely transparently. Additionally, planned datacenter outages and maintenance events are completely transparent, causing minimal disruption to the operational systems. In the past, such events required labor-intensive efforts to move operational systems from one datacenter to another
The use of “multihoming” in this context may be confusing because multihoming usually refers to a computer connected to more than one network. At Google scale perhaps it’s just as natural to talk about connecting to multiple datacenters.
Google has built several multi-homed systems to guarantee high availability (4 to 5 nines) and consistency in the presence of datacenter level outages: F1 / Spanner: Relational Database; Photon: Joining Continuous Data Streams; Mesa: Data Warehousing. The approach taken by each of these systems is discussed in the paper, as are the many challenges is building a multi-homed system: Synchronous Global State; What to Checkpoint; Repeatable Input; Exactly Once Output.
The huge constraint here is having availability and consistency. This highlights the refreshing and continued emphasis Google puts on making even these complex systems easy for programmers to use:
The simplicity of a multi-homed system is particularly valuable for users. Without multi-homing, failover, recovery, and dealing with inconsistency are all application problems. With multi-homing, these hard problems are solved by the infrastructure, so the application developer gets high availability and consistency for free and can focus instead on building their application.
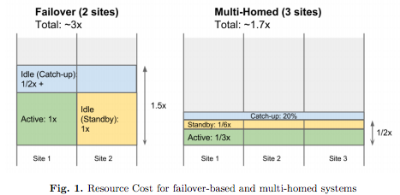
The biggest surprise in the paper was the idea that a multihomed system can actually take far fewer resources than a failover system:
In a multi-homed system deployed in three datacenters with 20% total catchup capacity, the total resource footprint is 170% of steady state. This is dramatically less than the 300% required in the failover design above
What’s Wrong With Failover?
Failover-based approaches, however, do not truly achieve high availability, and can have excessive cost due to the deployment of standby resources.
Our teams have had several bad experiences dealing with failover-based systems in the past. Since unplanned outages are rare, failover procedures were often added as an afterthought, not automated and not well tested. On multiple occasions, teams spent days recovering from an outage, bringing systems back online component by component, recovering state with ad hoc tools like custom MapReduces, and gradually tuning the system as it tried to catch up processing the backlog starting from the initial outage. These situations not only cause extended unavailability, but are also extremely stressful for the teams running complex mission-critical systems.
How do Multihomed Systems Work?
In contrast, multi-homed systems are designed to run in multiple datacenters as a core design property, so there is no on-the-side failover concept. A multi-homed system runs live in multiple datacenters all the time. Each datacenter processes work all the time, and work is dynamically shared between datacenters to balance load. When one datacenter is slow, some fraction of work automatically moves to faster datacenters. When a datacenter is completely unavailable, all its work is automatically distributed to other datacenters.
There is no failover process other than the continuous dynamic load balancing. Multi-homed systems coordinate work across datacenters using shared global state that must be updated synchronously. All critical system state is replicated so that any work can be restarted in an alternate datacenter at any point, while still guaranteeing exactly once semantics. Multi-homed systems are uniquely able to provide high availability and full consistency in the presence of datacenter level failures.
In any of our typical streaming system, the events being processed are based on user interactions, and logged by systems serving user traffic in many datacenters around the world. A log collection service gathers these logs globally and copies them to two or more specific logs datacenters. Each logs datacenter gets a complete copy of the logs, with the guarantee that all events copied to any one datacenter will (eventually) be copied to all logs datacenters. The stream processing systems run in one or more of the logs datacenters and processes all events. Output from the stream processing system is usually stored into some globally replicated system so that the output can be consumed reliably from anywhere.
In a multi-homed system, all datacenters are live and processing all the time. Deploying three datacenters is typical. In steady state, each of the three datacenters process 33% of the traffic. After a failure where one datacenter is lost, the two remaining datacenters each process 50% of the traffic.
The paper if full of more juicy details and is well worth reading: High-Availability at Massive Scale: Building Google’s Data Infrastructure for Ads.
Related Articles
F1 And Spanner Holistically Compared
Google Spanner's Most Surprising Revelation: NoSQL Is Out And NewSQL Is In
Spanner - It's About Programmers Building Apps Using SQL Semantics At NoSQL Scale



