How to Setup a Highly Available Multi-AZ Cassandra Cluster on AWS EC2


This is a guest post by Alessandro Pieri, Software Architect at Stream. Try out this 5 minute interactive tutorial to learn more about Stream’s API.
Originally built by Facebook in 2009, Apache Cassandra is a free and open-source distributed database designed to handle large amounts of data across a large number of servers. At Stream, we use Cassandra as the primary data store for our feeds. Cassandra stands out because it’s able to:
Shard data automatically
Handle partial outages without data loss or downtime
Scales close to linearly
If you’re already using Cassandra, your cluster is likely configured to handle the loss of 1 or 2 nodes. However, what happens when a full availability zone goes down?
In this article you will learn how to setup Cassandra to survive a full availability zone outage. Afterwards, we will analyze how moving from a single to a multi availability zone cluster impacts availability, cost, and performance.
Recap 1: What Are Availability Zones?
AWS operates off of geographically isolated locations called regions. Each region is composed of a small amount (usually 3 or 4) physically independent availability zones. Availability zones are connected with a low latency network, while regions are completely independent of each other, as shown in the diagram below:
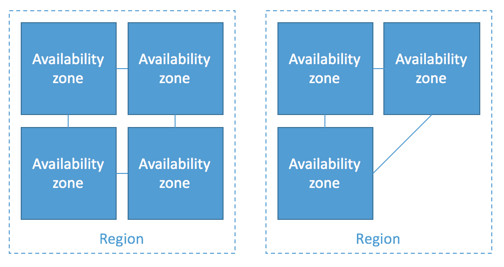
In order to achieve high availability, AWS resources should be hosted in multiple availability zones. Hosting in multiple availability zones allows you to ensure that if one goes down, your app will stay up and running.
Recap 2: Cassandra and High Availability
One of the primary benefits of Cassandra is that it automatically shards your data across multiple nodes. It even manages to scale almost linearly, so doubling the number of nodes give you nearly double the capacity.
Cassandra has a setting called “replication factor” that defines how many copies of your data should exist. If your replication factor is set to 1 and a node goes down, you will lose your data because it was only stored in 1 place. A replication factor of 3 will insure that your data is always stored on 3 different nodes, ensuring that your data is safe when a single node breaks down.
Configuring Cassandra for multi AZ availability
Now that we’ve covered the basics, let’s explain how to setup Cassandra for multi-AZ availability.
If you’re new to Cassandra and want to learn how to setup your own cluster, this article is a good starting point.
Part 1 - The Snitch
As a first step we have to make sure Cassandra knows which region and availability zone it’s in. This is handled by the “snitch”, which keeps track of the information related to the network topology. Cassandra provides several built-in snitches. The Ec2Snitch and Ec2MultiRegionSnitch work well for AWS. The Ec2Snitch is meant for a single region deployment, and the Ec2MultiRegionSnitch is meant for clusters that span multiple regions.
Cassandra understands the concept of a data center and a rack. The EC2 snitches treat each EC2 region as a data center and the availability zone as the rack.
You can change the Snitch setting in cassandra.yaml. Beware that changing the Snitch setting is a potentially destructive operations and should be planned with care. Read the Cassandra documentation about changing the Snitch setting.
# IF YOU CHANGE THE SNITCH AFTER DATA IS INSERTED INTO THE CLUSTER, # YOU MUST RUN A FULL REPAIR, SINCE THE SNITCH AFFECTS WHERE REPLICAS # ARE PLACED. # # Out of the box, Cassandra provides ... # - Ec2Snitch: # Appropriate for EC2 deployments in a single Region. Loads Region # and Availability Zone information from the EC2 API. The Region is # treated as the Datacenter, and the Availability Zone as the rack. # Only private IPs are used, so this will not work across multiple # Regions. # - Ec2MultiRegionSnitch: # Uses public IPs as broadcast_address to allow cross-region # connectivity. (Thus, you should set seed addresses to the public # IP as well.) You will need to open the storage_port or # ssl_storage_port on the public IP firewall. (For intra-Region # traffic, Cassandra will switch to the private IP after # establishing a connection.) # # You can use a custom Snitch by setting this to the full class name # of the snitch, which will be assumed to be on your classpath. endpoint_snitch: Ec2Snitch |
The above is a snippet from cassandra.yaml
Part 2 - The Replication Factor
The replication factor determines the number of replicas that should exist in the cluster. Replication strategy, also known as replica placement strategy, determines how replicas are distributed across the cluster. Both settings are keyspace properties.
By default Cassandra uses the “SimpleStrategy” replication strategy. This strategy places replicas in the cluster ignoring which region or availability zone it’s in. The NetworkTopologyStrategy is rack aware and is designed to support multi-datacenter deployments.
CREATE KEYSPACE mykeyspace WITH replication = { 'class': 'NetworkTopologyStrategy', 'us-east': '3' }; |
In the above code snippet we’ve declared a keyspace called “mykeyspace” with a NetworkReplicationStrategy which will place the replicas in the “us-east” datacenter only, with a replication factor of 3.
To change an existing keyspace you can use the example below. Beware that changing the replication strategy of a running Cassandra’s cluster is a sensitive operation. Read the full documentation.
ALTER KEYSPACE mykeyspace WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'us-east' : '3' }; |
Part 3 - Consistency levels
When you read or write from Cassandra, you have the ability to specify the “consistency level” on the client-side. In other words, you can specify how many nodes in the Cassandra cluster are required to agree before a read or write request is valid.
If you ask for a higher consistency level than Cassandra is able to answer with nodes in the local availability zone, it will query the other zones. To stay up during an availability zone outage, you need to use a consistency level that the remaining nodes are able to satisfy. The next section will discuss failure scenarios and consistency levels in more detail.
Handling AZ(s) Outages
How a Cassandra cluster behaves when an availability zone goes down depends on several factors:
Scale of the failure (how many AZs are down)
Number of AZs used by the cluster
Replication factor
Consistency level
Let’s have a look at the diagram below, which shows a couple of scenarios:

Figure 2. How consistency level affects availability
In the first scenario shown on the left we show a cluster running on 2 AZs with 6 nodes (3 per AZ) and a RF=2. When 1 AZ goes down, half of our cluster will be offline. With 2 AZs and a RF=2, we will have the guarantee that our entire dataset is still present on at least 1 node. As you can see in the table next to the cluster diagram, the outcome of a query depends on the requested consistency level. For example, a query with CL=ONE will succeed because we still have at least 1 node available. On the other hand, queries with higher CL requirements such as. QUORUM and ALL will always fail because they both require responses from 2 nodes.
In the second scenario, we run Cassandra with 9 nodes on 3 different AZs and a replica factor of 3. With this deployment, our cluster is clearly more resilient in the event of 1 AZ failure. Cassandra will still be able to satisfy queries with CL=QUORUM.
It is worth noting that in the event of an availability zone outage, the capacity left in service for the 2 clusters is different. With the first cluster setup you lose 50% of the capacity, while the second setup only affects 33% of the capacity.
How Much Latency Is Introduced by a Multi-AZs Setup?
Estimating query latency introduced by the multi-AZ setup is not easy due to the nature of Cassandra and the number of factors that fluctuate in a cloud environment (e.g. network latency, disk I/O, host utilization, etc.).
For our tests we used the cassandra-stress tool to generate read and write load on clusters running on single and multiple AZs. In order to keep the variance as low as possible, and to lower the deviation on disk I/O, we used instances with ephemeral storage instead of network attached storage (EBS).
We then came up with two test scenarios:
The first used a cluster of 6 i2.xlarge instances (AWS network performance = “moderate”) and was running without enhanced networking:
|
Median |
95th percentile |
|
|
WRITE |
||
|
Single AZ |
1.0 |
2.5 |
|
Multi AZ (3 AZs) |
1.5 |
2.8 |
|
READ |
||
|
Single AZ |
1.0 |
2.6 |
|
Multi AZ (3 AZs) |
1.5 |
23.5 |
Table 1. Scenario 1: performance test Single AZ vs Multi AZ (time in milliseconds). Setup: Cassandra 2.0.15; RF=3; CL=1
The second scenario used a cluster of 6 i2.2xlarge (AWS network performance = “high”), with enhanced networking turned on:
|
Median |
95th percentile |
|
|
WRITE |
||
|
Single AZ |
0.9 |
2.4 |
|
Multi AZ (3 AZs) |
1.1 |
2.3 |
|
READ |
||
|
Single AZ |
0.7 |
1.5 |
|
Multi AZ (3 AZs) |
1.0 |
1.9 |
Table 2. Scenario 2: performance test Single AZ vs Multi AZ (time in milliseconds). Setup: Cassandra 2.0.15; RF=3; CL=1
Interesting enough, networking performance varies between the two instance types. When using i2.2xlarge with enhanced networking enabled, we saw very little difference between single AZ and multi AZ deployments. Therefor we recommend enabling enhanced networking and selecting an instance types with “high” network performance.
Another interesting fact is that Cassandra reads are – to a certain extent – rack-aware. When coordinating a query, Cassandra nodes will route the request to the peer with lowest latency. This feature is called “dynamic snitching” and has been part of Cassandra since version 0.6.5.
Thanks to dynamic snitching, most of the read queries to Cassandra do not “hit” nodes on different availability zones and give Cassandra some sort of rack-awareness. We could reproduce this behavior on our read tests as shown in the following chart:
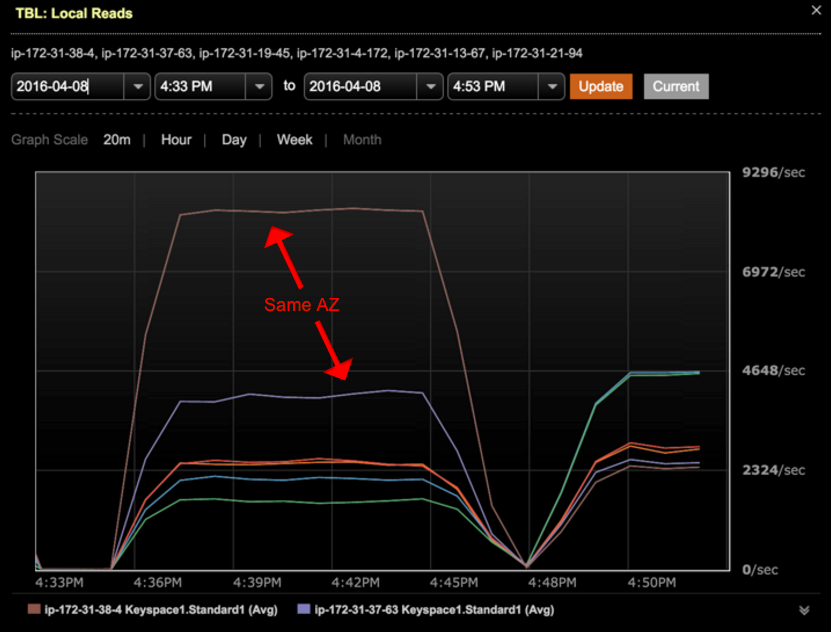
Figure 1. Number of local read-requests per node on multi-AZ setup. Replicas in the same AZ are preferred. Set up: 6 nodes cluster spanning across 3 Azs. Read are performed with Consistency Level=ONE
Figure 1 shows how 10M read requests are distributed across the cluster. As you can see, most requests are handled within the local availability zone.
About enhanced networking: AWS offers enhanced networking on their most recent instance families. Using enhanced networking results in consistently lower inter-instance latency. For more information about this topic, please follow this link.
Guidelines for Deciding the Number of Availability Zones to Use
Cassandra can be configured in such a way that every availability zone has at least 1 entire copy of the dataset. Cassandra refers to this scenario as making an AZ self-contained. To achieve this, you need to place your nodes across a number of AZs that is less or equal your replication factor. It is also recommended to have the same number of nodes running on every AZ.
In general it is beneficial to have:
Availability Zones <= Replication Factor
At Stream we’ve chosen to use a replication factor of 3 with 3 different availability zones. This ensures that every availability zone has a copy of the data, and that we have enough capacity left to handle read and write requests in the unlikely event of an AZ outage.
Conclusion
Cassandra is an amazing database. At Stream we rely heavily on it to keep the feeds running for tens of millions of end users. In short, we do so because Cassandra has the ability to:
Shard data automatically
Handle instance failures without data loss or downtime
Scale (almost) linearly
In this post we’ve explained how to configure Cassandra in a highly available Multi-AZ setup on AWS EC2. The costs and performance are almost identical to a single availability zone deployment. A few key takeaways:
Placing nodes across multiple availability zones makes your Cassandra cluster more available and resilient to availability zone outages.
No additional storage is needed to run on multiple AZs and the cost increase is minimal. Traffic between AZs isn’t free but for most use cases this isn’t a major concern.
A replication factor of 3 combined with using 3 availability zones is a good starting point for most use cases. This enables your Cassandra cluster to be self-contained.
AWS has done a great job at keeping the latency between availability zones low. Especially if you use an instance with network performance set to “high” and have enhanced networking enabled.



