Code Generation: The Inner Sanctum of Database Performance


This is guest post by Drew Paroski, architect and engineering manager at MemSQL. Previously he worked at Facebook and developed HHVM, the popular real-time PHP compiler used across the company’s web scale application.
Achieving maximum software efficiency through native code generation can bring superior scaling and performance to any database. And making code generation a first-class citizen of the database, from the beginning, enables a rich set of speed improvements that provide benefits throughout the software architecture and end-user experience.
If you decide to build a code generation system you need to clearly understand the costs and benefits, which we detail in this article. If you are willing to go all the way in the name of performance, we also detail an approach to save you time leveraging existing compiler tools and frameworks such as LLVM in a proven and robust way.
Code Generation Basics
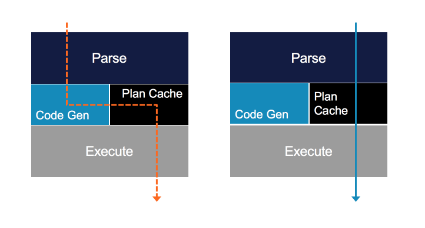
In the database world, human readable SQL queries can be compiled to native code, which executes faster and is more efficient when compared to the alternative of interpreted execution. Code generation helps streamline operations by populating a plan cache with a natively compiled query plan, as shown in the following diagram. While this can take a bit more time at the outset, the performance benefit for a compiling query plans to native code in a database can be significant.
Efficiency and Performance
Software has been one of the greatest forces affecting the world in the last 50 years, and virtually all software is powered by compilers. Compilers massively impact the efficiency and performance of software, and even influence how people use and experience software, as well as how programmers develop software.
There are both qualitative and quantitative benefits of code compilation:
QUALITATIVE BENEFITS: big enough differences in execution performance that change what user experiences are even possible <br>
QUANTITATIVE BENEFITS: improvements in execution efficiency help reduce CPU and resource usage, which often reduces costs and increases profits
Implementing Code Generation as a First Class Citizen
Making code generation a first class citizen sets a foundation for high performance software systems. Some databases such as MemSQL assume code generation as a core competency and ensure broad native compilation capabilities from day one. Other databases implement support for code generation later after the initial release, usually with some partial coverage that expands over time.
Of course it is possible to improve query performance by various means without compiling query plans to native code. However, the alternative requires a layer of software called an “interpreter” to continually act as a go between, where the interpreter runs directly on the CPU and executes lower level machine instructions on behalf of the SQL query. Regardless of whether you run your software on bare metal, in a container, or in a VM, generating native code and passing it directly to the CPU allows for greater potential performance.
Taking a compilation-first mentality when building a database means being able to fully compile all SQL query plans to native code. This is an aggressive stance for databases, as other approaches that delay support for code generation frequently end up with a subset of functionality.
Database Performance When Disk Is No Longer The Bottleneck
With the rise of in-memory databases, the performance landscape for databases has changed substantially. There is also a growing demand for real-time analytics on large, constantly changing datasets. These developments present new and interesting performance challenges to tackle.
When optimizing any software system, it is useful to focus on three broad areas:
- Intelligent I/O scheduling, data movement, and load balancing
- Memory use on individual machines
- How computation is actually performed on the CPU
I/O scheduling, data movement, and load balancing
For many applications, intelligent I/O scheduling, data movement, and load balancing directly impact performance. Poor I/O scheduling can cause an application to stall and leave the CPU idle while waiting for I/O to finish, wasting time that potentially could have been spent doing productive CPU work. Poor planning with respect data movement and load balancing can cause an application to waste precious I/O bandwidth unnecessarily or to overload some nodes in a cluster while leaving other nodes idle. Optimizing I/O scheduling, data movement, and load balancing is critical for reducing an application’s latency and maximizing its overall throughput.
Memory Use
Memory use is another important area of focus. Modern hardware can achieve lightning-fast memory access most of the time through the use of sophisticated multi-level hardware caches that reside on the same die as the CPU. The cache is a limited resource, however, and so the CPU still needs to read from main memory every so often when there is a cache miss. A high cache miss rate can slow down an application by introducing millions of “micro-stalls” per second, where the CPU idles for a few dozen of nanoseconds at a time waiting to retrieve a value from memory. Like I/O, optimizing memory usage and memory access patterns is important both for increasing throughput and reducing latency.
CPU Computation
The last area of focus, how computation performs on the CPU, is perhaps the most obvious. In the simplest terms, optimizing computation consists of changing the application to reduce the total number of CPU executed machine instructions while still performing all of the essential application functions. The CPU only performs so many operations per second, so naturally reducing the CPU burden maximizes application performance.
New Challenges
For traditional databases, efforts to maximize throughput were bottlenecked on I/O. Native code generation can have a substantial impact on CPU and memory usage, but when I/O is the limiting factor, improvements to CPU and memory usage by themselves often have little effect on an application’s maximum potential throughput.
With I/O no longer the bottleneck for in-memory databases, users now push databases systems to extremes, using data to improve business efficiency and yield real-time insights. To support these demands, investing in native code generation has become an essential part of building modern high-performance databases.
Building a Compilation Pipeline
Building a compiler from scratch that generates high quality native code requires a great deal of engineering effort before it pays off. Fortunately, software engineers have devised a number of techniques that leverage existing technologies to reduce the amount of upfront work needed, albeit while accepting some trade-offs and limitations in the longer term.
The “transpilation” approach is a common technique, which works by first translating the desired gsource language (ex. SQL) into a second high- or mid-level programming language (ex. Java, C++) and then leveraging an existing compiler to convert this second language to native code. Notable examples of this technique include Microsoft SQL Server’s natively compiled stored procedures (Hekaton) and earlier versions of MemSQL (prior to MemSQL 5).
Depending on the needs of a business, the trade-offs and limitations imposed by the transpilation approach can eventually become obstacles to supporting new use cases and expanding into new markets. As MemSQL adoption continued to grow larger and more diverse over time, it became apparent that the original approach to native code generation would need an overhaul to deliver on ever-increasing performance requirements. During the development of MemSQL 5, the original compilation pipeline was replaced by a new high-level language virtual machine architecture powered by LLVM, delivering a 20x increase in the speed of code generation itself while still producing high quality native code. Boosting the speed of code generation was an important step towards creating an immersive, interactive experience working with huge datasets.
The New MemSQL Code Generation Architecture
Let’s briefly look at some of the internal details of the new MemSQL code generation architecture.
The compilation pipeline starts with a parametrized SQL query. The query is transformed into an imperative query plan expressed in a high level imperative language called MPL (MemSQL Plan Language), which in turn is lowered down to mid- and low-level intermediate languages (MemSQL Bit Code and LLVM bitcode respectively), and finally the last stage uses LLVM to convert the LLVM bitcode to high quality native code.
The “explain mpl” and “explain mbc” commands give the user some introspection capabilities to see how the MemSQL native compiler works. The compiler does its best to intelligently choose the optimal execution plan, so typically users don’t need to pay attention to these internal details.
Basic example
create database db1;
use db1;
create table t (a bigint primary key not null, b bigint not null);
insert into t values (1,2);
explain select a*a + b from t;
+----------------------------------------+
| EXPLAIN |
+----------------------------------------+
| Project [t.a * t.a + t.b AS `a*a + b`] |
| TableScan db1.t, PRIMARY KEY (a) |
+----------------------------------------+
explain mpl select a*a + b from t;
declare NetworkProcessFn:
function(exprs: exprs_t1*, context: context_t1*) bool <-
with (buffer : ProtocolRowBuffer* <- &(((*(context)).state2).buffer))
with (bufferPartition : int32_t <- 0)
{
with (outRowBase : ProtocolRowBase* <-
cast<ProtocolRowBase*>(ProtocolRowBufferGetNextRow(buffer, bufferPartition)))
OutRowSigned(
outRowBase,
&(AddSignedSigned(
MulSignedSigned((*(*(exprs)).state1).`a`, (*(*(exprs)).state1).`a`),
(*(*(exprs)).state1).`b`)))
ProtocolRowBufferFlushIfNeeded(buffer)
return 0
}
declare ScanTable:
function(exprs: exprs_t1*, context: context_t1*,
xact: Transaction*, foundRowParam: bool*) -> bool
{
foreach (rowPtr in GetSL(rcIndex=0, indexOrdinal=0, takeRowLocks=0))
using transaction xact
{
(*exprs).state1 <- rowPtr
if (call NetworkProcessFn(exprs, context))
return 1
}
return 0
}
As shown above, the sample SQL query gets transformed into an imperative plan written in MPL. The “foreach” block inside the “ScanTable” function loops over all the rows in the table and calls the “NetworkProcessFn” function for each row. The “NetworkProcessFn” computes “a*a+b” for each row and queues the results to be sent to the client.
explain mbc select a*a + b from t;
Function 2 <NetworkOutputFn>:
0x0000 Lea local=&local2 local=context i32=8
0x0010 Lea local=&local1 local=local2 i32=0
0x0020 ProtocolRowBufferFlush local=local1 target=0x0040
0x002c Literal8 local=&rvToReturn i64=1
0x003c Return
...
Function 3 <ScanTable>:
0x0000: VSIterInit local=&vsIter i32=0 i32=0 i32=0 local=xact
0x0018: Literal1 local=&hasMore i32=0
0x0024: GetQueryContext local=&queryContext
0x002c: VSIterHasMore local=&hasMore local=&vsIter target=0x0140
0x0048: JumpIfFalse local=hasMore target=0x0108
0x0054: VSIterGetRowPtr local=&rowPtr local=&vsIter
0x0060: Lea local=&local1 local=exprs i32=0
0x0070: Deref8 local=local1 local=&rowPtr
0x007c: CallManaged func=0 <NetworkProcessFn> target=0x0138
local=&local2 local=exprs local=context
...
0x00cc: VSIterNext local=&vsIter
0x00d4: CheckQueryKilled local=queryContext target=0x0138
0x00e0: VSIterHasMore local=&hasMore local=&vsIter target=0x0130
0x00fc: JumpIfTrue local=hasMore target=0x0054
0x0108: VSLIteratorFree local=&vsIter
0x0110: Literal8 local=&rvToReturn i64=1
0x0120: Literal1 local=hiddenRvParam i32=0
0x012c: Return
...
The MBC generated for the sample SQL query shows the same imperative plan as the MPL, but at a greater level of detail with larger and more complex operations broken down into smaller steps. For example, the “foreach” loop from the MPL has been converted to a sequence of lower level MBC instructions (specifically “VSIterHasMore”, “JumpIfTrue”, and “JumpIfFalse”).
Once the query plan has been converted to MBC, the next steps involve translating the MBC into LLVM bitcode and leveraging LLVM to convert this bitcode to high quality native code. Once LLVM generates native code, we pass it directly to the CPU for execution. All SELECT queries and all data-modifying queries in MemSQL execute in this manner.
Landscape Disruption with First Class Code Generation
Building a high performance database with first class code generation enables new and qualitatively different user experiences that were not possible before. Across industries, areas like personalization, risk management, anomaly detection, billing, and supply chain optimization stand to gain from better database performance. Real-time business analytics provide companies an instant view of their operations through ad hoc and ongoing queries on rapidly changing data sets. This could be manually at the command line or via and visualization tools like Tableau or Zoomdata.
Most importantly, fast performance enabled by native code generation allows developers to write sophisticated capabilities that were previously challenging to integrate into applications. For example, it is impossible to incorporate live query results to an application if they take minutes to calculate. However, results that return in under a second can be presented live to an interactive application. This could range from serving the right content, ecommerce item, or ad to an end user, to fraud alerts with real-time monitoring.
The Path Forward with Natively Compiled Functions
Taking an aggressive stance on native code generation sets a foundation for performance that pushes the bounds of data processing. Having broad native compilation capabilities is imperative to maximizing the efficiency of modern in-memory database systems.
With this foundation in place, database systems can further extend many dynamic and highly programmable features, such as user-defined functions, and ensure that they can take full advantage of the underlying hardware. Given the benefits, we are likely to see several database products striving to deliver the best possible code compilation performance to deliver on low-latency queries and more sophisticated functions as the market evolves.



