One model at a time: Integrating and running Deep Learning models in production at EyeEm


This is a guest by Michele Palmia of @EyeEm.
We’ve now been running computer vision models in production at EyeEm for more than three years - on literally billions of images. As an engineer involved in building the infrastructure behind it from scratch, I both enjoyed and suffered the many technical challenges this task raised. This journey has also taught me a lot about managing processes and relationships with different teams, tasks of an especially challenging nature in a dynamic startup environment.
What follows is an attempt to consolidate the computer vision pipeline history at EyeEm, some of the challenges we had to face, some of the learning we’ve gained, and a glimpse into its future.
Index the world’s photos
When I joined EyeEm just over three years ago, the focus was to build a search engine that would allow users to search the company’s full catalog of images. This was to be accomplished by tagging and performing aesthetic scoring of - what was at the time - a quickly growing library of 60 million images, and indexing the results thus allowing users to search freely over the images. Keep in mind this was at the very beginning of the AI fever: fresh out of college, I was very excited and insanely scared.
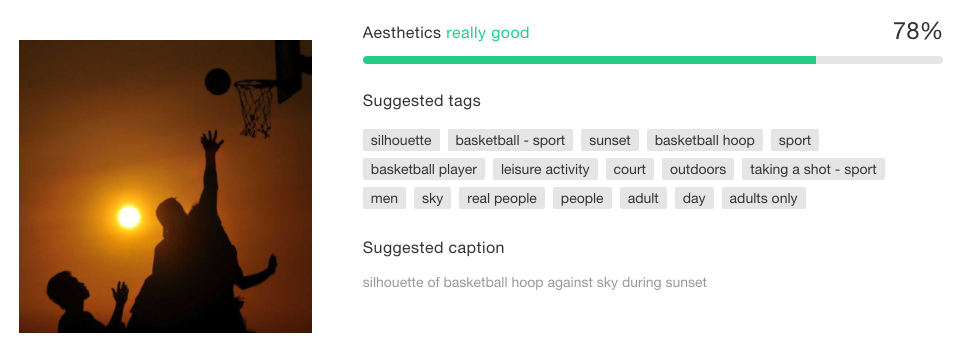
The goal was to calculate an aesthetic score and a list of tags for each image. Captioning was also introduced later on.
Team structure
The day I joined I sat at a long table with a few researchers, a photo curator and a fellow engineer. The cross-functional team was fully dedicated to the search project. The curator would select the images. The researchers would develop algorithms for tagging and scoring. And us engineers would integrate them in the production-ready search application and plan its infrastructure for scale.
With the company in its infancy, a number of new projects were being kickstarted during the same time. Over that period, it quickly became clear that having a united engineering team would be beneficial for everybody. Moving away from the cross-functional approach helped us share knowledge more effectively, reuse components more easily, and create an effective engineering culture.
The two separate and independent teams’ roles and responsibilities haven’t changed since:
The R&D team produces self-contained machine learning models that are able to take a simple input, typically an image, and return a simple output, like an aesthetic score or a list of proposed tags. The models are wrapped in a Python API that also defines the needed pre-processing steps and the eventual post-processing actions. Each of these algorithms are strictly versioned, with major versions indicating updates to the underlying model, and minor versions indicating updates to the wrapping Python code.
The Core Engineering team receives the product of the R&D team’s work and, after a knowledge exchange and an assessment of the deliverables, designs and develops code and infrastructure to run the models at scale. The more complex exchange process usually happens only on major version updates, and typically with direct communication between team members.
Knowledge exchanges are usually performed in the form of a very lightweight checklist, including information on input and output formats, especially changes with respect to previous versions, application requirements and hardware requirements, and finally test coverage. They typically happen directly between an R&D and a Core Engineering engineer, with escalation necessary only in case of drastic output changes that would affect internal or user-facing features.
I’m a very strong believer in horizontal collaboration:
“anybody should talk to anybody else according to what they think is the fastest way to solve a problem for the benefit of the whole company”
(Musk 2017).
I’m happy to say that, with our highs and lows, this is the way my colleagues and I have been allowed and encouraged to work over this whole time, and we couldn’t have made it this far otherwise.
Making it work
The first system to be designed had to be able to tag and aesthetically score every single image in the EyeEm library, and every new image streaming in.
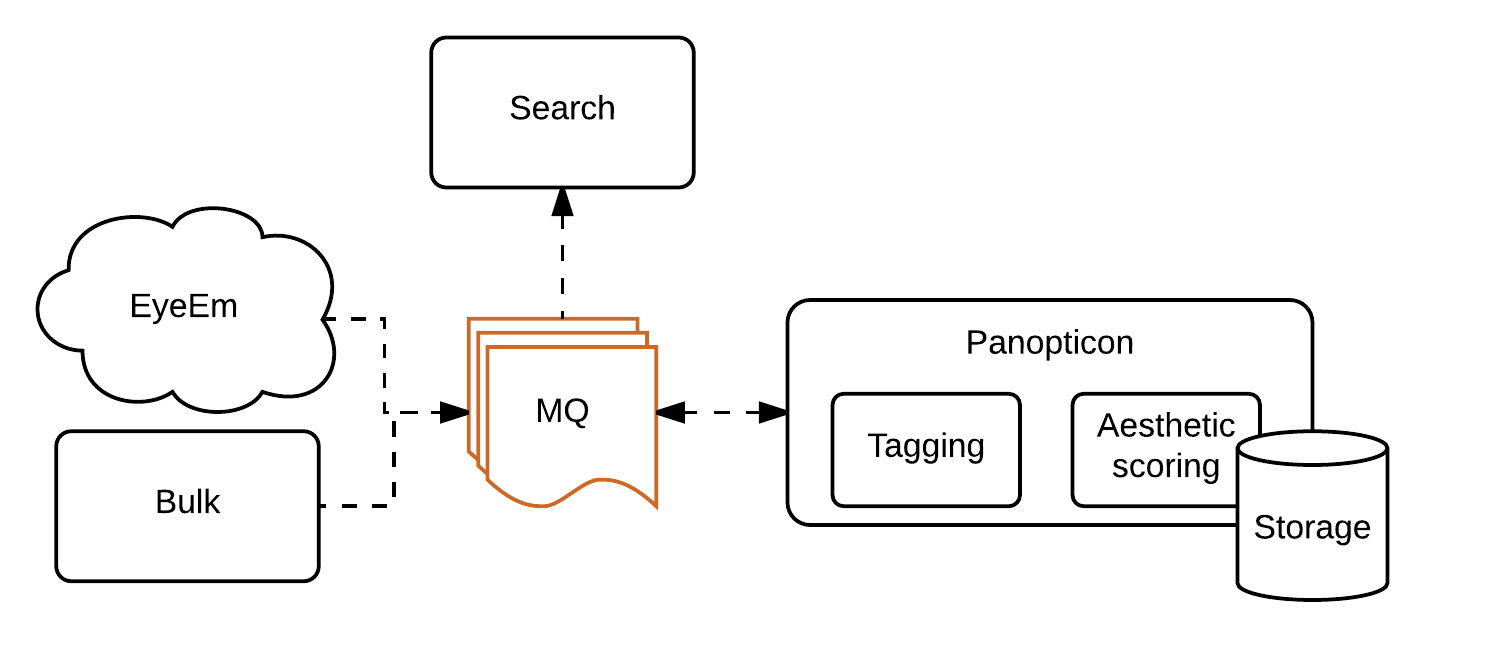
As with many startups, after a beginning based on a single monolithic application, the company was shifting to a distributed architecture. The new service was named Panopticon, after the single-watchmen prison design introduced in the 18th century. As you’ll notice in the article, at EyeEm we cultivate a fine art for naming projects.

Panopticon’s role was to simply read incoming messages from a queue, containing the ID’s of new photos being uploaded, perform inference on the original images, store results and send them to the search system, once again over a queue. Requesting tagging or aesthetic scoring results previously calculated would also happen over queues.
The framework that the Research & Development team had decided to use was Caffe. Our team had Python experience, making it obvious that's how the service would be written. Python also allowed very quick iteration which is appreciated in such a quickly evolving project. RabbitMQ was already in use as the message system, and Cassandra seemed a perfect fit for data that would essentially need to be kept forever, with almost no deletions, and that only needed to be accessed by ID with no scans. Amazon’s GPU instances that needed to run the Deep Learning algorithms designed by R&D, would be managed by a simple Auto Scaling Group. The configuration was managed by Chef, as for the rest of infrastructure at the company.
Because of Panopticon being based on queues, the easiest way to process big sets of images at the time was to inject their ids. In order to keep results for different models isolated, machines would need to be configured to load different models and hooked to different queues.
A number of issues emerged fairly quickly. While we’ve luckily learned a lot on the way, these are some of the fundamental problems we still battle every day:
GPU machines are (very) expensive.
While the machines we’d use for serving APIs typically cost less than $0.4 per hour, the cheapest GPU machine on Amazon is $0.7 per hour. Fortunately, there are now more resources to deploy containers on GPU machines and thus likely reduce costs, but these were not available when we started — and are still not trivial to use.
Loading inputs and pre/post-processing them are typically long CPU operations.
Only one input (or preferably a batch of them) can be processed by a GPU at a time. Applications are thus typically configured to wait for a processing task to be over before proceeding to the next one. Performing CPU operations within the frame of such a task means having the GPU, a very expensive resource, idle for a possibly relevant amount of time.
Quickly processing batches of hundreds of millions of images with limited resources is hard.
In a pub/sub model, message injection rates need to strictly match consumption rates. In a client/server model, the pool of servers will eventually exceed the power of a single client. In general, scaling up will eventually hit hidden bottlenecks of all sorts.
Juggling multiple different models each with different requirements and contracts is hard.
We have changed the output format of the quality score model, that we’ll talk about later, at least four times. Handling the output of research requires diligence.
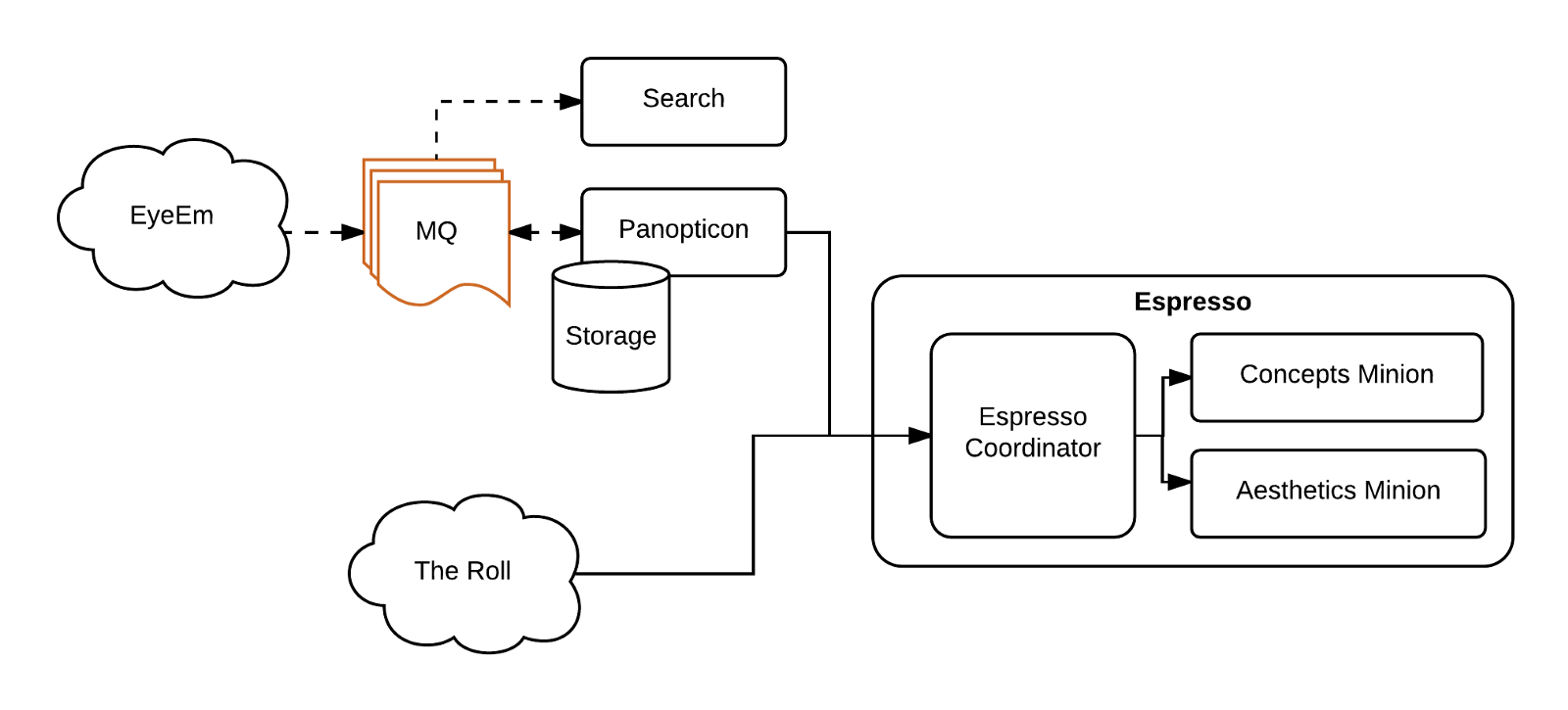
Enter The Roll
Panopticon worked well, but was only designed to process EyeEm’s images. We introduced The Roll, an iOS app to organize and find a user’s best photos. This app was meant to tag and assign an aesthetic score to entire camera rolls, with images having nothing to do with the EyeEm library. After receiving the technical requirements for this new project, we established that we needed a new, platform agnostic system able to process any arbitrary input image on the available models. After a quick brainstorming session we came up with the very creative and fitting name for the system that would wrap the Caffe-based models: Espresso!
Espresso was designed to be the one and only inference system in production at EyeEm, and Panopticon was quickly refactored to stop running models itself, and use it instead. We iterated quickly on Espresso to fix issues that we had noticed with Panopticon, and to adjust new complications as they came up.
We implemented gatekeeping in Espresso from the very beginning to introduce at least a weak guaranteed response times for clients.
We allowed each Deep Learning model to define independent requirements and to run in its own virtual environment, enabling the R&D team to use different frameworks for different models. Keras and Tensorflow were coming.
We allowed batching that we had not employed before.
We’ll discuss each of them in detail in the following paragraphs.
Gatekeeping
The one substantial change that distinguished Panopticon (EyeEm-specific) from Espresso (agnostic) was the middleware. While the former’s API was based on queues, the latter relied completely on a couple of HTTP endpoints. As opposed to panopticon, that was in no hurry to process incoming images, Espresso would need to quickly give an answer back — a problematic guarantee for queues. Models had also grown faster, allowing this paradigm shift.
A GPU can only process an image-or a batch of images-at a time, typically in the hundreds of milliseconds. Each requests needs to be handled sequentially, unless multiple GPUs are available. But when we receive a high volume of requests, we can’t allow them to pile up indefinitely, as we want to ensure we can give reasonable response times to clients.
Espresso was thus equipped with a very simple gatekeeping mechanism. The application would need to be configured with the maximum number of requests to accept at any given time. Any request exceeding the threshold would be refused with a 429 HTTP code (Too Many Requests). If the threshold would be set at 10 and 11 requests would reach the application in a very short burst, the first 10 would be accepted and queued, while the 11th would be refused.
If tagging would be performed with a 99th percentile of 500ms, a gatekeeping threshold of 10 requests would guarantee a response time of 5 seconds. While this is a weak guarantee because of that last percentile, it was more than enough for our clients.

The launch of The Roll was a success. We monitored the number of requests being served growing steadily, with new machines booting up as soon as the amount of 429s would be seen consistently for a few minutes. Retrying on 429 allowed for the load to distribute graciously between machines. In the days following the release, we had an average of a thousand images being processed per second.
This worked very well until a few months after The Roll went to production.
Isolating R&D code
Initially, all models produced by the R&D team were packaged as a single Python library, first used by Panopticon and later by Espresso. Around the time we launched The Roll, we started to realize that the models’ requirements were starting to diverge, and we needed our infrastructure to support such possibility.
Caffe was being abandoned in favor of Theano (and Keras, and Tensorflow), thus we needed to run each model in its own virtual environment, initialized with the right requirements. This also meant that we could no longer run a single Python application on each GPU machine anymore: we had to run a single Python process per model, but we still needed to provide a unified interface to clients with the same API as before. Packaging each model independently was trivial, but we had to rethink our architecture to support this shift.
The Espresso Coordinator
With the need to keep everything operational came the strict requirement for compatibility. Instead of a single process running multiple models on each GPU machine, we now had one Python process per model, each of which we started to call minion. Minions would run the same code as the previous Espresso application, but instead of serving multiple outputs, they would serve a single one. A new coordinator application was developed to query the minions and merge their responses, offering a unified API to clients. I don’t think you need a tinfoil hat to figure out the name we gave the coordinator application: the Espresso Cup (I’ll keep calling it coordinator for clarity).
Batching and scaling
Performing inference on GPU means the fastest way to process multiple inputs at once is passing them as a single batch to the model, as opposed to invoking inference independently multiple times. As an example, if a single inference is performed in 500ms, a batch inference for two images would be performed in around 800ms, with larger batches providing higher gains. At some point in the processing pipeline, images from independent requests need to be batched together, sent on as a single batch, and split up in independent responses upon reception of the results.
In the first iteration of The Roll, batching had been delegated to the machines responsible for The Roll API itself, the “first line” receiving requests from users, and working as a client for Espresso. The system was designed so that a first new request coming from users would open a brand new batch. A new batch could either be filled before a configurable timeout, or sent over unfilled if the timeout occurred: the busier the API, the bigger and more efficient the batches.
Placing the batching logic on The Roll API working as client for Espresso, means that given a fixed number of Espresso machines, the batch size depends only on the number of public API machines. If two photos come in from users concurrently and there’s only one API machine, one single batch will be created, regardless of the number of Espresso serving machines. On the other hand, placing the batching logic on the servers allows batches to be generated according to processing capacity. If two photos come in concurrently and there is only one Espresso machine, they will be batched; if there are two Espresso machines, they will be processed concurrently.
Batching always needs to be performed at the latest possible stage in the processing chain.
Growing the family
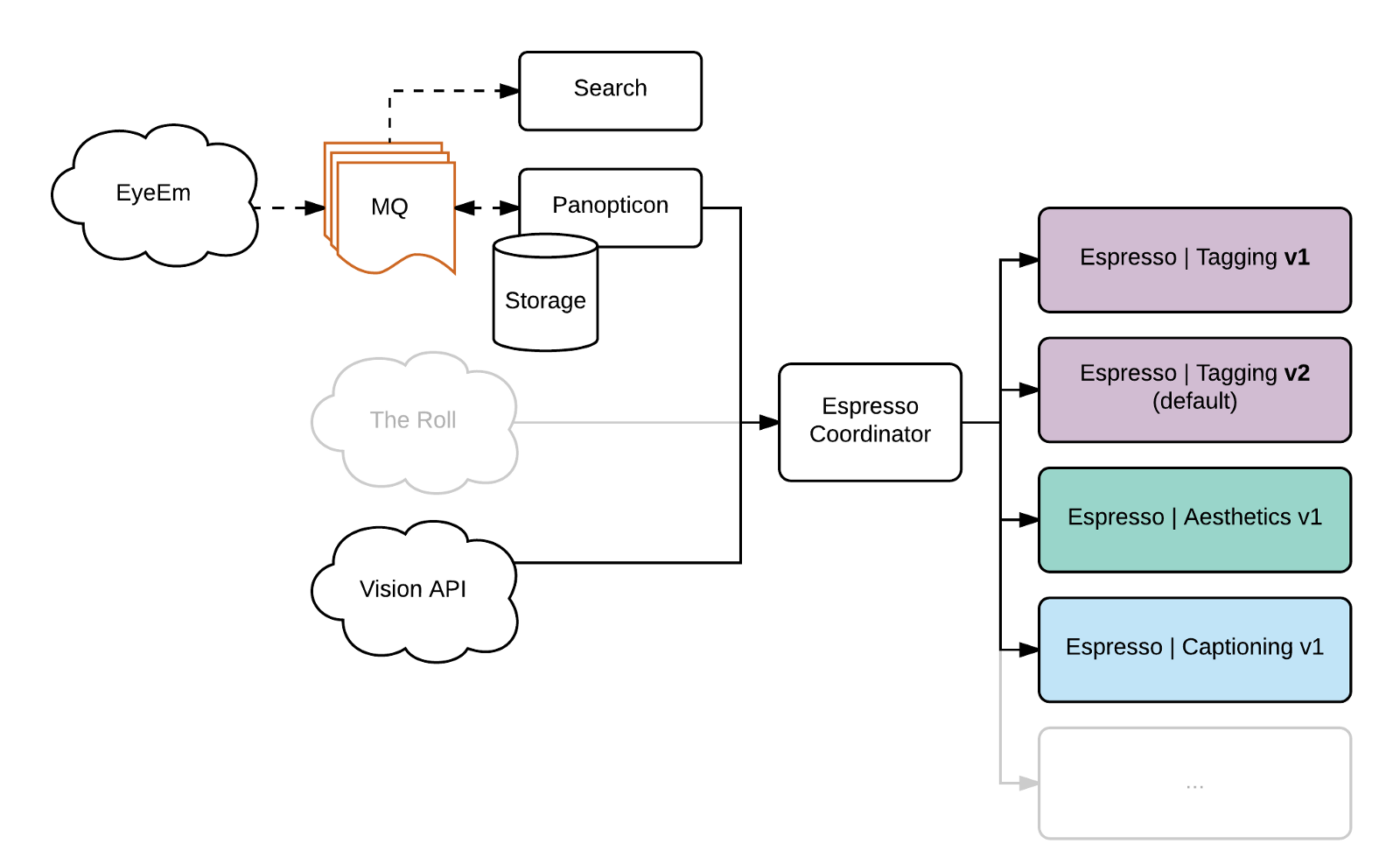
The Roll had an adventurous but short life, as its features were soon to be integrated in the main EyeEm app. Nonetheless, new versions of the tagging and aesthetics models kept being produced and, more importantly, completely new models were needed due to new business goals.
At the beginning of 2017, on top of the long-lived tagging and aesthetic scoring models, we had a captioning model, internal photo quality model, and a personalized aesthetics scoring system, broken in a feature extractor, a personalized training model and a personalized scoring model. Running more than a couple of these on a single machine would always have to be done sequentially on GPU, increasing overall response times. Moreover, the GPU memory itself got too busy, reducing the maximum batch size.
In a migration effort that required a few months, we decided to
allow multiple versions of the same model to run in the same stack — the client would have to specify a version for a model, or simply request a default;
use one machine per model, simplifying greatly the management of the infrastructure and allowing independent scaling of single minions;
offload preprocessing to an independent server, to avoid occupying GPU machines with CPU tasks;
perform batching at the lowest possible level, on the minions, allowing the best possible usage of resources.
The Way Forward
It’s always hard to stay focused on the high level architecture when so many system issues have to be addressed every single day. Working towards a unified, organic approach for handling new and existing models, staying flexible toward both the R&D team upstream and the clients downstream, fighting with pressing deadlines and constant bug fixing. Yet, I believe every single one of the people that contributed to build our inference pipeline can be proud of the results we achieved. I hope all team members tasked with solidifying and evolving the system going forward will enjoy the challenge too.
I hope you as a photographer or as a creative enjoy using our product, knowing that a great deal of technology is helping in so many different ways.



