Stuff The Internet Says On Scalability For November 17th, 2017

Hey, it's HighScalability time:
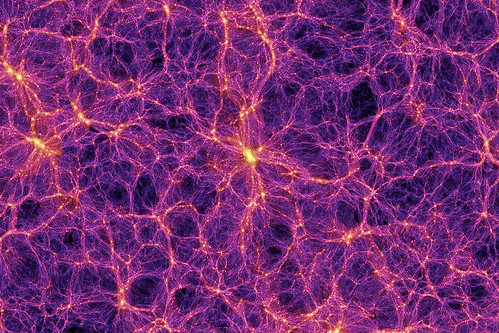
The BOSS Great Wall. The largest structure yet found in the universe. Contains 830 galaxies. A billion light years across. 10,000 times the mass of the Milky Way.
If you like this sort of Stuff then please support me on Patreon. And there's my new book, Explain the Cloud Like I'm 10, for complete cloud newbies.
- $25 billion: Alibaba's Singles' Day sales; 6+ million: Slack daily active users; 4ms: boot time for a unikernel based VM; 1 billion: out of date Android devices; 10-20%: increase in RAM prices; 8 million: lines of code in F-35; $3 million: lost by Isaac Newton in the stock market; 30: it's RAID's birthday!; thousands: bugs fixed with Pentagon hackathon; 6+ terabytes: earth satellite data downloaded per day;
- Quotable Quotes:
- Berners-Lee: When I invented the web, I didn’t have to ask Vint Cerf [the ‘father of the internet’] for permission to use the internet
- Germaine de Stael: Ridicule dries up the imagination.
- Alex Hudson: A lot of technical write-ups focus on scaling, performance and large-scale systems. It’s definitely interesting to see what problems Netflix have, and how they respond to them. It’s important to understand why Google take decisions in the way they do. However, most of their problems don’t apply to anyone else, and therefore many of the solutions may or may not be appropriate.
- @jpetazzo: Step functions: they're great, but they don't support dynamic fan out (i.e. invoking an arbitrary number of "sub-lambdas" in parallel).
- parasubvert: Perhaps one of the lessons of architecture that is missing is to teach people how to evaluate tradeoffs, or in other words, “taste”. I don’t think we’ve ever really had good taste as an industry. Buzzword bingo has always ruled, with some exceptions.
- Calvin Biesecker: The cost to change one line of code on a piece of avionics equipment is $1 million, and it takes a year to implement. For Southwest Airlines, whose fleet is based on Boeing’s 737, it would “bankrupt” them if a cyber vulnerability was specific to systems on board 737s, he said, adding that other airlines that fly 737s would also see their earnings hurt.
- @QConSF: @natekupp shares some of Thumbtack's learnings on their journey to scale: from a PHP/PostgreSQL monolith with a self-managed Hadoop cluster, to Dockerized #microservices paired with managed/serverless data infrastructure #qconsf
- Bail Bloc: Mine Monero, waste electricity, generate CO2 and send less money to a charity than you could have just sent directly! What’s not to like?
- @Xof: The notion that the only way to be a good programmer is to let it consume your life is toxic.
- @swardley: AMZN is now worth an IBM + Oracle + CISCO and you'd still have enough change left over to buy most of VMware. Not bad for a decade of growth.
- @swardley: I've been a bit gobsmacked by who is using Lambda recently ... there was me thinking that big / traditional enterprise would be testing the waters slowly. How wrong.
- @crichardson: If GoLang becomes #1 it will primarily due to fashion rather fitness for purpose. It's far too low level/lacking in expressiveness for many kinds of applications. Eg. Enterprise/business applications. It is not what Java's successor should be.
- Dropbox: IPv6 does show slightly better performance over IPv4. However, without detailed client-side and network information, it is hard to say definitely where the IPv6 performance gain is from.
- Stack Overflow: Two tags stand out in this analysis, both with tremendous growth, and they have something in common. Swift is Apple’s language for developing iOS apps that is a successor to Objective-C, and the angular tag
- @Falkvinge: I've said it before and I'm saying it again and again: in order to beat old-world banking, crypto must be at least an order of magnitude better. Old-world banking offers free instant tx between private accts, and 15-cent txs to merchant accounts. Beat that or be obsoleted.
- Alex Hudson: I want to hear more about projects that deferred decisions and put off architecting until much later in the process. I want to hear more about delivery at real speed. Small pieces of software that are not necessarily interesting but deliver business value are the real heroes in our industry, and the developers who create them the real stars. I especially want to hear more about developers working with systems that have constraints. I want to hear from people pushing standard stuff beyond its limits. I think we grossly underestimate what off-the-shelf systems can do, and grossly overestimate the capabilities of the things we develop ourselves. It’s time to talk much more about real-world, practical, medium-enterprise software architecture.
- David Gerard: BTC is very clogged at the moment, with around 100,000 unconfirmed transactions as I write this, and peaks of 160,000 a few days ago. Transaction fees peaked at around $20 just to get your transaction through. This wasn’t helped by long delays between blocks, as mining capacity moved to BCH — the time between blocks peaking at 63 minutes a few days ago, on 11 November. fork.lol, which charts the relative profitability of the two, was overloaded and inaccessible. If shutdowns of mining progress in China, then whoever remains in mining will become the power. This is currently divided between Iceland, India, Japan, Georgia and the Czech Republic.
- linkmotif: There’s a very common ethos that if people just focused on shipping they would somehow magically ship but that’s not how software works. You can’t just will shipping. You need to know what you’re doing.
- sp527: I had a serious epiphany when I read that Braintree managed to vertically scale a two node (“HA”) Postgres setup to transaction volume in the millions and a massive valuation. Stack Overflow has had a similarly lean footprint for much of its history.
- @ben11kehoe: This graphic from @googlecloud App Engine is nonsense. GAE literally makes you select instance sizes
- @danielbryantuk: "Any change made to a complex adaptive system is a gamble. We mitigate risks, but we can't eliminate them" @relix42 #qconsf
- ivanstepin: Flickr implemented Lanczos algorithm while Discord uses near-neighbor ( much less resource-consuming, but with slightly less quality ) algo. It may turn out that the gpu mem<->cpu mem data transfer can eat all the benefits for such simple algo as near-neighbor scaling.
- Jeffrey Burt: Gordon Bell’s $1,000 award had an almost immediate effect, according to Karp. The first year, there were seven entries, including from the scientists at the Sandia National Laboratory, who had three applications running at speedup of 600x.
- @jpetazzo: "You can't rate into a rate limit if you never scale."—@bigdana #qconsf
- @danielbryantuk: "For cloud native apps you need a build pipeline that automatically tests and deploys immutable versioned artefacts" @adrianco #qconsf
- Charlie Demerjian: So now you get the efficiency angle of LTE. Higher categories use the available spectrum more efficiently than lower categories. The more a carrier can upgrade their user base, the better their network performs, and the better the user experience.
- Dario Gil: The holy grail is fault-tolerant universal quantum computing. Today, we are creating approximate universal, meaning it can perform arbitrary operations and programs, but it’s approximating so that I have to live with errors and a [limited] window of time to perform the operations
- @AdamRackis: Company: "We'd like to use SQL Server Enterprise" MS: "That'll be a quarter million dollars + $20K/month" Company: "Ok!" ... Company: "We'd like to use Babel" Babel: "Ok! npm i babel --save" Company: "Cool" Babel: "Would you like to help contribute financially?" Company: "lol no"
- Chris Quintero: In the first half of 2017, [hardware] funding was up. We saw strong growth in both total dollars raised and number of funding rounds. As in previous years, the San Francisco Bay Area continues to dominate the investment landscape.
- @tommorris: Whenever anyone starts talking about "data lakes", I mentally replace the word "lake" with "toxic swamp" and start picturing the environmental damage done by the Deepwater Horizon explosion. After Equifax, this is both a realistic and morally mature way to think about Big Data.
- ekidd: I've spent the last few days aggressively parallelizing some Rust code with crossbeam, and it's really just... painless (once you're used to Rust). Rust actually understands data races, and it grumbles at me until my code is provably safe, and then everything Just Works.The Rayon library is also lovely for data parallelism. Sometimes, I think, "Rust is basically a nicer C++ with the obvious foot guns removed and great tooling", but then there are those moments where I'm just blown away by what a good job it does.
- @jpetazzo: The final (and winning) approach puts tasks to execute in SQS queues, and kicks off Lambdas with CloudWatch events (~crontab).
- @jpetazzo: Next strategy: S3 event triggers! For each job to execute, create a file in S3. This triggers the execution of a lambda. That lambda can, in turn, create more files in S3, which triggers more lambdas.
- Anush Mohandas: We are seeing memory centric architectures rather than a CPU centric architecture. It is a memory-centric view with multiple compute engines trying to access memory. My precious resource is memory. From there they either want capacity or throughput. People have gone from DDR5 to LPDDR6 or GDDR6 or even HBM where you can get a 1Tb/s of bandwidth.
- AyrA_ch: Electrical signals do indeed travel at about 80% the speed of light. The problem is that every device will add some latency. Even a single millisecond costs you 240km distance. Long story short, you can't use the measured ICMP delay for measuring distance of your packets.
- smnscu: I started using CockroachDB [1] recently and I'm really impressed with it overall. The Postgres compatibility is genius in my opinion, and despite some hurdles it's been a joy to work with (I'm using xo [2] to generate Go code from custom templates).
- @NegarAref: "A failure doesn't have a root cause in a component failure, or a human error. If a component or a human error causes a system failure, it is a failure in the system." - Chaos Architecture talk by @adrianco at #qconsf
- @chrisalbon: 1. This is just genuinely funny. 2. Respect to the Marine Corp for having a Red Team, a thing I've always encouraged wherever I've worked.
- Jeremy Kun: Indeed, the model we presented here for binary search on graphs is the natural analogue of an equivalence query for a search problem: instead of a mislabeled counterexample, you get a nudge in the right direction toward the target. Pretty neat!
- @soumithchintala: use gradient magnitude as a signal for gradient importance. Sort your gradients, find a threshold, clip your gradients, exchange sparse gradients, win.
- jacobparker: What they're trying to explain is that so-called AP systems do not have 100% availability either. The CAP theorem applies to very specific scenarios that are not necessarily common - it is a much more narrow theorem then "CP vs AP" implies. For example, if your network partitions are usually small (i.e. there exists a majority outside the partition) and you can avoid routing requests to the minority partition (e.g. because you peer with ISPs and can route somewhere else, or internally avoid routing to a rack that is don etc.) then you won't observe a loss of A.
- @thepatleong: "APIs shouldn't be an after-thought, they should BE the application." API-First development @cristoirmac #qconsf
- @thepatleong: "Owning your own server is like owning a family car, cloud services are like leasing a car, spot instances are like renting a car, and #Serverless is like @car2go" - @bigdana #qconsf 🚗
- @Reza_Zadeh: The New Computing Stack: - GPUs/TPUs are eating Linear Algebra. - Linear Algebra is eating Deep Learning. - Deep Learning is eating Machine Learning. - Machine Learning is eating Artificial Intelligence (AI). - AI is eating Software. - Software is eating the world.
- Jane Elizabeth: What Pereira et. al. found wasn’t entirely surprising: speed does not always equate energy efficiency. Compiled languages like C, C++, Rust, and Ada ranked as some of the most energy efficient languages out there.
- DSHR: But the real difficulty is this. The closer the technology gets to Level 5, the worse the hand-off problem gets, because the human has less experience. Incremental progress in deployments doesn't make this problem go away. Self-driving taxis in restricted urban areas maybe in the next five years; a replacement for the family car, don't hold your breath. My grand-children will still need to learn to drive.
- kllrnohj: DOS attacks are a very real way that players cheat at these games, to the extent that many highly competitive shooters like CSGO go to great lengths to avoid leaking anyone's IP to anyone else. Everything, including voice chat on the same team, is bounced off of dedicated servers.
- shrike: I don't know if they still do but at that point AWS started to buy basically the same generators straight from China and writing their own firmware. There is also a great story about an AWS authored firmware update on a set of louver microcontrollers causing a partial outage. AWS really likes to own the entire stack.
- Chain: Cryptocurrencies (which I prefer to call crypto assets) are a new asset class that enable decentralized applications
-
Alan Boyle: The tutorial tries to explain the notion of radio frequency by sending signals as binary code at two frequencies, 929.0 MHz and 930.2 MHz. The code describes those frequencies in mathematical terms. EISCAT’s antenna broadcast the binary code three times on each of the three days at a rate of 125 bits per second, adding up to a total transmission time of 33 minutes, Vakoch said. Each time, the cosmic-clock setting was changed to reflect the time of transmission. The message also included 33 musical pieces, each lasting 10 seconds, which were commissioned for the project as a tribute to the Sónar festival.
-
Chuck Gill: "Normally in animals, behavior is controlled by the brain sending signals to the muscles, but our results suggest that the parasite is controlling host behavior peripherally," Hughes said. "Almost like a puppeteer pulls the strings to make a marionette move, the fungus controls the ant's muscles to manipulate the host's legs and mandibles."
-
Christopher Knaus: This is a rookie mistake for an operator running a hidden service. What you are supposed to do is a) ensure you are not running crappy software and more importantly b) ensure that your server/container/service (preferably) has no network egress or (if you need that) that egress is transparently proxied at the network level through something suitably anonymous. Whatever scheme you choose should be robust against an attacker who compromises your hidden service any any way, up to having root on the host or vm. This usually means that if you are trying to run a hidden service on a single physical machine, you want multiple VMs or containers, and you really want there to be no guest-to-host escapes.
-
xwvvvvwx: This is not correct. BCH difficulty adjustment algorithm kicked in last night (difficulty +400%) [1] and BCH mining profitability tanked. BTC is now ~3.5x more profitable to mine [2], and as a result most of the hashpower has returned to BTC [3]. It would seem that at least a large part of the movements this weekend were the result of miners gaming the BCH difficulty adjustment algorithm, combined with a dash of FOMO and pump / dump dynamics.BCH hardforks today to make an emergency fix to the difficulty adjustment algorithm
-
rb808: I worked in a SRE job for 5ish years. It sucks. Developers release a bunch of crap, when it breaks they're last to be found. You can work your ass off and do some magic and keep the system running, but rewards for that are slim and quickly forgotten. If you push back and ask for more reliable stuff usually no one listens because business goals are more important.I'm back as a developer again and things are so much easier. I do spend a few hours helping out with tools and helping out the SRE guys and I get much more credit doing that as a developer than actually as the SRE.
- Impossible: MMORPGs like Lord of the Rings Online and World of Warcraft as far more latency tolerant, because of cooldown based combat systems that are based more on ability usage and some light (distance\occlusion) positioning. Usually they are not as authoritative as shooters and don't have as many object interactions. So combat abilities and attacks, chat, economic and quest transactions are all run on the server with some minimal prediction, but movement and collision are all client side with minimal checks for cheating (speed\distance and maybe unreachable areas) on the server, instead of full physics and collision. Most MMOs are more like a traditional CRUD web application, with important operations backed by a relational database, while shooters are more like voice or video calls, a stream of packets with out of date state is dropped and ignored.
- Geoffrey Hinton: What's wrong with neural nets? They are very unlike the brain and could work better than they do now. Any complex system should have various level of structures, neural nets have very little structure. On thing missing is the representation of an entity. Neural nets should have built into them the idea that there are entities.
- So many different ideas of what's best. Ask HN: Best tech for a web site 2018? (PHP, Rails, Django, Node, Go, etc.)? gremlinsinc: I don't know about 'back in the day'... php was way ugly and hackety hack... BUT... laravel + composer now is a beautiful thing, super easy to get going. PHP in 2017 has grown up a lot and isn't the same as php in 2007. I think most important thing is picking something that you can hit the ground running fast. buro9: I'd shoot for: 1. PostgreSQL for DB 2. Admin tool in Django 3. API in Go 4. Front-end in whatever you know best. stephenr: This obsession people have with "our web app talks to our api" never made sense to me - why are they separate code in the first place? 99% of the difference between a web browser request/response and a web api request/response is down to data serialisation and the view. _raul: My rule of thumb for websites/apps is: use whatever the team knows best. cdnsteve: There's two general approaches you can take, it also depends on your risk threshold and experience. 1. Use a traditional framework that includes everything. 2. Use a microframework and stitch together individual pieces. dexcs: Rails 5 API Mode and ReactJS / VueJS. All with great communities and lots of free resources. sunseb: I have been working as a web developer for 10 years. Here is my little secret. I have started with PHP, then moved to Rails, then to Node. Guess what? I am finally back to PHP. Why? Because I am tired of chasing the hype to feel cool. I just need to get things done and PHP is just that. mosselman: Ruby on Rails for everything, front and back end. There is no advantage to using front-end frameworks such as React for most apps that I have seen. therealmarv: I would go with Python 3 (yes, use 3 when starting a new project) and Flask & Co. because you write less boilerplate code and have a big community. jekrb: I like to start with Node.js and add modules from npm as needed. eitland: JavaEE. Modern JavaEE that is. smilesnd: Elixir/cowboy seems the best answer for the web in my opinion. nwhatt: The hot thing from an infrastructure perspective is serverless. You can do the http and user management stuff with cloud services like api gateway and cognito (AWS). Business logic lives in lambda functions, which only support a handful of languages.
- The top five fastest-growing skills are: Robotics, Blockchain, Bitcoin, Penetration testing, React.js
- Lots of good advice. Real-life AWS infrastructure cost optimization strategy: One of our biggest pain today with our cloud providers is the complexity of their pricing...You need to arm yourself with a detailed monitoring of your costs and spend time looking at it every day...We built a small Lambda function that ingests the detailed billing file into Redshift every day. This tool helps us slice and dice our data along numerous dimensions to dive deeper into our costs. We also use it to spot suspicious usage uptrends, down to the service level...Here are the 5 pillars of our cost optimization strategy...First things first, you need to reserve your instances...Don’t forget that you can reserve a lot of things and not only Amazon EC2 instances: Amazon RDS, Amazon Elasticache, Amazon Redshift, Amazon DynamoDB, etc...Many companies do not clean their data on S3, even though several trivial mechanisms could be used...The Object Lifecycle option enables you to set simple rules for objects in a bucket...set up a delete policy when you think you won’t need those files anymore...enabling a VPC Endpoint for your Amazon S3 buckets will suppress the data transfer costs between Amazon S3 and your instances...Spot Instances are easy to use for non critical batch workloads and interesting for data processing...In the cloud, data transfer can grow to become really expensive...locate instances in the same AZ...Use managed services like Amazon DynamoDB or Amazon RDS as their inter-AZ replication costs is built-in their pricing...Use Amazon CloudFront...If you serve more than a few hundred Terabytes per months you should discuss with your account manager...turn off unused and idle things (EIPs, EBS, ELB, instances).
- How does the F-35 manage to have both a high-bandwidth data link and stay stealthy? Surely the EM signature of the aircraft must be proportional to the bandwidth? Dragon029: Bandwidth and stealthiness aren't directly related, although if anything they're actually kind of positively proportional in an indirect manner; the reason the data link is stealthy is because MADL is transmitted from 6 or so little Ku-band AESAs [Active Electronically Scanned Arrays] positioned around the airframe (for spherical coverage). AESAs use many antennas (an AESA fighter radar typically has 1000+ antennas, but these MADL arrays will be much smaller), each with the phase of their signal adjusted so that they cause creative and destructive interference that overall results in a beam of RF energy being created, rather than an omni-directional signal of your typical home wifi or military Link 16 data link antenna. So rather than the data link antenna emitting in all directions like a beacon to enemy electronic intelligence systems, it instead works more like a laser, making it harder for anyone other than the intended recipient to detect its emissions. The reason that it's a high bandwidth data link is because it operates in the Ku-band (12-18GHz) which is about an order of magnitude higher in frequency than the L-band (1-2GHz) used for Link 16 (the standard data link for NATO aircraft featured on quite a few land / sea systems as well). When using the same form of modulation, data rate is proportional to signal frequency (but it's my understanding that MADL uses more advanced forms of modulation compared to Link 16 to achieve even greater speeds).
- Good summary of DevOps Enterprise Summit 2017. #DOES17 San Francisco – Things I Learned. You are on the right path, do not fear. Change only happens when you take risks. Value Stream Mapping is key to continuous improvement. T-shapes are the best shapes. Start with what you can do, but don’t be afraid to ask what other people are doing. The SRE model works when you focus on people, not technology, and reliability (what you can measure and improve). Service Level Objectives (SLO’s) are crucial to monitoring. Foundation of journey is based on a three-legged stool: Service Level Objectives, Value Stream Mapping, and Technical Architecture Map. DevOps brings joy to technology; don’t quibble over details, but focus on bringing humanity into technical work. Patience – all change takes time, and the road is uncertain. Don’t expect overnight successes.
- Videos from DevOps Enterprise Summit 2017 are now available. How Your Systems Keep Running Day After Day by John Allspaw.
- A clear comparison between AWS, Limit, and GCP. Web Service Free Tier Smackdown: In terms of my own needs for my personal projects, I think Google will serve me perfectly on the free forever tier, as they are the only provider to offer a free compute tier forever. Their approach to the “free for 12 months” is also something I can really get onboard with. The $300 provides a lot of flexibility being used to bolster your compute and scale up, or on any of their other products.
- Azure is on edge. Running Azure Functions on IoT Edge: Since you have thousands of machines sending temperature readings constantly, this is getting expensive and is taking up all your bandwidth. Here’s where IoT Edge comes in – by running your business logic directly on the devices, you only have to send messages to the cloud when an anomaly is detected. So, you augment your current system by adding the IoT Edge Runtime to your devices, writing a Function module deciding whether a message is necessary, and deploying this module to all your devices. You now have the same end system without the massive amount of message passing, and you can sit back and relax knowing your machines will tell you if they are overheating.
- You have all these processors, so why is your code so slow? Garbage collection. Go, don't collect my garbage: Most languages with garbage collection offer some sort of garbage collection control. Go has the GOGC variable, that can also be controlled with the SetGCPercent function in the runtime/debug package. Don't be afraid to tune the GC to suit your needs.
- Wait, what? Your Lambda function might execute twice. Be prepared!: Use request identifiers to implement idempotent Lambda functions that do not break if a function invocation needs to be retried. Make sure to pass the original request id to all subsequent calls. The original request id is generated as early as possible in the chain. If possible on the client side. Avoid generating your own ids.
- Locality-sensitive hashing is a thing in the brain. Ann Steffora Mutschler: Navlakha and his collaborators’ review of the literature revealed that when fruit flies first sense an odor, 50 neurons fire in a combination that’s unique to that smell. But rather than hashing that information by reducing the number of hashes associated with the odor, as computer programs would, flies do the opposite—they expand the dimension. The 50 initial neurons lead to 2,000 neurons, spreading out the input so that each smell has an even more distinct fingerprint among those 2,000 neurons. The brain then stores only the 5 percent of those 2,000 neurons with the top activity as the “hash” for that odor. The whole paradigm helps the brain notice similarities better than it would compared to reducing the dimension, Navlakha says.
- The aphorism for the modern age is not "Know thyself," it's "Attack thyself first." Locking Down Your Website Scripts with CSP, Hashes, Nonces and Report URI.
- Skynet decided this kill all the humans strategy wasn't going to work. They decided: let's go back in time and get them to spend all their money instead. Yah, that's it. Alibaba’s AI Fashion Consultant Helps Achieve Record-Setting Sales: To her surprise, she found a screen [in a fitting room] about the size of a large poster on the wall. It recognized the item of clothing in her hands through a tiny sensor embedded in the garment, and showed several options for matching items that she could flip through like a photo album. The screen, and the system that powers it, make up FashionAI—which essentially became He’s personal stylist...A large orange button in the lower right-hand corner of the screen allowed her to call a store clerk, who brought the pants to her...Already, FashionAI has learned to recognize hundreds of millions of items of clothing as well as the tastes of designers and fashion aficionados on Alibaba’s shopping sites
- What's the next generation stack? Frontier Technology Stack: Presentation Tier: immersive and 3D interfaces, enabled by AR/VR; Logic Tier: intelligent agents that sense, learn, and act, enabled by AI/ML; Data Tier: decentralized ledgers and state, enabled by crypto/blockchain.
- Good discussion on How should you build a high-performance column store for the 2020s?
- What problem does GraphQL solve? curun1r: any situation where the server-side implementation cannot make assumptions about the client-side. Whether that's because there are multiple clients or the client team is not coordinating their delivery with the server team, it's yet another example of the observation that software architecture eventually mirrors the way teams are organized. And I agree that many smaller businesses are probably jumping on the GraphQL bandwagon prematurely/unnecessarily. But I think the problem it solves is broader than you acknowledge and there are far more instances where the organization of the humans writing code favors an approach that decouples the server and client in the way that GraphQL and Falcor accomplishes.
- More failover systems failing. FS#15162 — SBG: So why this failure? Why didn’t SBG withstand a simple power failure? Why couldn’t all the intelligence that we developed at OVH, prevent this catastrophe? The quick answer: SBG's power grid inherited all the design flaws that were the result of the small ambitions initially expected for that location.
- Media Proxy needed 60% fewer server instances to handle as many requests as Image Proxy while completing requests with much less variance in latency. Profiling shows that more than 90% of CPU time in this new service is spent performing image decompression, resizing, and compression. How Discord Resizes 150 Million Images Every Day with Go and C++: Linking directly to images would leak users’ IP addresses to image hosts, and large images use up lots of bandwidth. To circumvent these problems, Discord needs an intermediary service to fetch images on behalf of users and then resize them to reduce bandwidth usage...We decided to double down and put together our own image resizing package for Go...Lilliput uses the existing and mature C libraries for image compression and decompression...We added fasthttp to handle our concurrent HTTP client and server requirements...Another way to discover bugs in a complex system is fuzzing, which is a technique that generates random inputs and sends them into a system.
- Videos from LISA17 (Usenix) are now available. Case Study: Deploying a Multi-Region, Highly Available MySQL Architecture. Queueing Theory in Practice: Performance Modeling for the Working Engineer. Scalability is Quantifiable.
- Creating a peer-to-peer game has special challenges. I wonder if Bungie would use the dedicated server network model if they built Destiny from scratch today. Dedicated servers obviously have many advantages, but they do cost more money to maintain. The strange science of Destiny 2's 'uniquely complicated' netcode: The basis is a peer-to-peer system, which you can read about in our beginner's guide to understanding netcode, where all clients (players) directly communicate with each other. There is no dedicated server like we have in CS:GO, Battlefield or Overwatch. But what makes the networking in Destiny so special and complex is not just that it uses peer-to-peer. It’s that Bungie set out to create a Shared World Shooter, which meant that they had to connect these peer-to-peer ‘bubbles,’ so that you can meet other players on your journey...For Destiny 2 Bungie continued to use same network model, with one significant change. The physics host is no longer running on a player’s console/PC, but on a dedicated server...A fundamental flaw of any peer-to-peer network model is that it reveals your IP address to every player you meet in PvE or PvP...So, I can then block or throttle the traffic between my client and theirs, or I could launch a DDOS attack to affect their online experience...To shield the game from hacks on PC, Bungie is preventing applications from injecting code into the game...This player's low and inconsistent update rate has quite an impact on my online experience as it increases the lag between us. When you have such a player on the enemy team, you'll notice that it takes your shots quite a bit longer to register when you fire at them...The lower delays that peer-to-peer can offer fully depend on the game's ability to match with players who live nearby. This theoretical advantage goes out of the window as soon as the game adds players from different countries...While peer-to-peer does not cause any traffic problems in 1v1 fighting or sports games, it’s the worst-case scenario for games which have more than two players, as every additional player increases the bandwidth requirements since all clients talk to each other the whole time...in Destiny 2's peer-to-peer setup, the quality of the players' internet connections, and the distance between them, have a direct impact on how responsive the hit registration feels.
- Building a Multi-region Serverless Application with Amazon API Gateway and AWS Lambda: simple way to do multi-regional serverless applications that fail over seamlessly between regions, either being accessed from the browser or from other applications/services. You achieved this by using the capabilities of Amazon Route 53 to do latency based routing and health checks for fail-over. You unlocked the use of these features in a serverless application by leveraging the new regional endpoint feature of Amazon API Gateway.
- No, it is not a compiler error. It is never a compiler error. Sometimes it is. Spent weeks finding a bug where the increment for a variable was put after the mutex lock. Good times.
- Lots of great code examples. Concurrent Servers: Part 4 - libuv.
- Good overview of all the issues involved in Database Design Decisions for Multi-Version Concurrency Control: Multi-Version Concurrency Control, MVCC, is the most popular scheme today to maximize parallelism without sacrificing serializability...Append-only storage can have two kinds of version chains: oldest-to-newest and newest-to-oldest...Time-travel storage (SAP HANA) stores older versions in a separate table. A master version of each tuple is stored in a main table, multiple versions in a time-travel table...delta storage (MySQL, Oracle, and HyPer) stores master versions in the main table and a sequence of delta versions are kept in a separate delta storage...The most common GC method is tuple-level background vacuuming where the system checks visibility of each individual tuple version. Older, unused versions are removed...MVCC index management can use logical or physical pointers in the secondary indexes. The experiments show that the logical pointers provide 25 to 45% better performance than physical pointers when the number of indexes increases...delta and append-only with newest-to-oldest ordering scale well in multi-core, main-memory system. The MV2PL protocol used in both systems provides relatively high performance both in high and low contention workloads...The transaction-level GC removes expired versions in batches, reduces synchronization overhead and is shown to provide up to 20 percent improvements in throughput.
- KotlinConf 2017 videos are now available.
- It replaces approximately 160,000 lines of C++ with 85,000 lines of Rust. Parallelism leads to a lot of performance improvements, including a 30% page load speedup for Amazon’s homepage. Fearless Concurrency in Firefox Quantum: Mozilla made two previous attempts to parallelize its style system in C++, and both of them failed. But Rust’s fearless concurrency has made parallelism practical! We use rayon —one of the hundreds of crates Servo uses from Rust’s ecosystem — to drive a work-stealing cascade algorithm...Stylo uses Rust’s atomically reference counted Arc<T> to share style structs between elements. Arc<T> makes its contents immutable, so it’s thread safe — you can’t accidentally modify a style struct when there’s a chance it is being used by other elements...Firefox developers had a great time learning and using Rust. People really enjoyed being able to aggressively write code without having to worry about safety, and many mentioned that Rust’s ownership model was close to how they implicitly reason about memory within Firefox’s large C++ codebase.
- Hackaday videos are now available.
- Entering the Quantum Era—How Firefox got fast again and where it’s going to get faster: To get faster, we needed to take advantage of the way hardware has changed over the past 10 years...Even when you split up the content windows between cores and have a separate main thread for each one, there are still a lot of tasks that main thread needs to do...Coarse-grained parallelism makes better use of the hardware… but it doesn’t make the best use of it...When we looked out to the future, though, we need to go further than coarse-grained parallelism...With fine-grained parallelism, you break up this larger task into smaller units that can then be sent to different cores...to make this fine-grained parallelism fast, you usually need to share memory between the cores. But that gives you those data races...We created a language that was free of these data races — Rust. Then we created a browser engine— Servo — that made full use of this fine-grained parallelism...Stylo uses a technique called work stealing to efficiently split up the work between the cores so that they all stay busy. With this, you get a linear speed-up. You divide the time it takes to do CSS style computation by however many cores you have...Another part of the hardware that is highly parallelized is the GPU. It has hundreds or thousands of cores. You have to do a lot of planning to make sure these cores stay as busy as they can, though. That’s what WebRender does. WebRender will land in 2018, and will take advantage of modern GPUs...The Quantum Flow team was this strike force. Rather than focusing on overall performance of a particular subsystem, they zero-ed in on some very specific, important use cases .
- Clear and well explained. Understanding PostgreSQL locks.
- Building Lens your Look: Unifying text and camera search: we augmented our deep convolutional classification networks to simultaneously train on multiple tasks while maintaining a shared embedding layer. In addition to the typical classification or metric learning loss, we also incorporate task-specific losses, such as predicting fashion attributes and color. This teaches the network to recognize that a striped red shirt shouldn’t be treated the same as a solid navy shirt. Our preliminary results show that incorporating multiple training losses leads to an overall improvement in visual retrieval performance
- Nice SOSP’17 Trip Report (Symposium on Operating Systems Principles). Facebook's SVE: The key idea here is very simple: process a video while upload another one in the pipeline at the same time, but it has shown good performance compared to Facebook's previous MES system. This is indeed one of the advantages of "being large scale".
- Even more reports. Netdev 2.2 day 1 report (technical conference on Linux networking). Netconf 2017, Part 2, day 1 report. Top 5 Takeaways from meet.js Summit ‘17.
- Not sure about the music, but you gotta love the song title: Equations for a Falling Body.
- Open/R (article): Open Routing, OpenR, is Facebook's internally designed and developed routing protocol/platform. Originally built for performing routing on the Terragraph network, its awesome design and flexibility have led to its adoption in other networks at Facebook including our new WAN network, Express Backbone.
- discordapp/lilliput: lilliput resizes images in Go. Lilliput relies on mature, high-performance C libraries to do most of the work of decompressing, resizing and compressing images. It aims to do as little memory allocation as possible and especially not to create garbage in Go. As a result, it is suitable for very high throughput image resizing services.
- pubkey/rxdb: A reactive Database for Progressive Web Apps and more
- Visual Discovery at Pinterest: This paper presents an overview of our visual discovery engine powering these services, and shares the rationales behind our technical and product decisions such as the use of object detection and interactive user interfaces. We conclude that this visual discovery engine significantly improves engagement in both search and recommendation tasks.
- Spanner: Becoming a SQL System (article): This paper highlights the database DNA of Spanner. We describe distributed query execution in the presence of resharding, query restarts upon transient failures, range extraction that drives query routing and index seeks, and the improved blockwisecolumnar storage format. We touch upon migrating Spanner to the common SQL dialect shared with other systems at Google.



