Stuff The Internet Says On Scalability For November 3rd, 2017

Hey, it's HighScalability time:
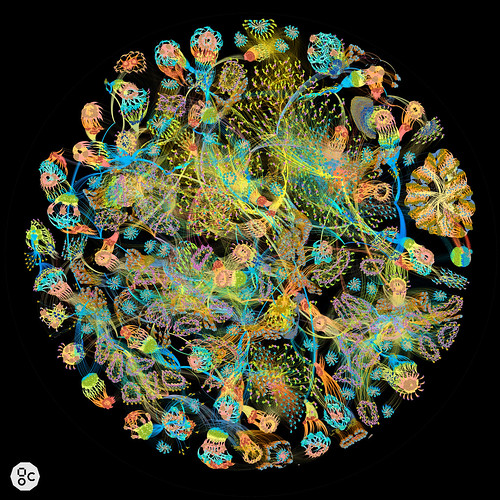
Luscious visualization of a neural network as a large directed graph. It's a full layout of the ResNet-50 training graph, a neural network with ~3 million nodes, and ~10 million edges, using Gephi for the graph layout, to output a 25000x25000 pixel image. (mattfyles)
If you like this sort of Stuff then please support me on Patreon. And take a look at Explain the Cloud Like I'm 10, my new book for complete cloud newbies. Thanks for your support! It means a lot to me.
- 96.4%: adversarial algorithm fools Google's image recognition; 70%+: GOOG and FB influence over internet traffic; 99%: bird reduction on farms using tuned laser guns; 52.45%: people playing my indie game have pirated it; 371,642: open-source projects depend on React; 6: words needed to ID you in email: 2x: node.js speed increase with Turbofan; 3: students who discovered 'Dieselgate'; 215KWh: energy consumed per bitcoin xaction, enough for a car to travel 1,000 miles; 33%: increase in Alphabet's quarterly profits; $1 billion: Amazon's ad business; 1 pixel: all it takes to fool our AI overlords; 61%: increase in Alibaba revenue; 1 minute: time it takes a 1964 acoustic coupler modem to load a Wikipedia page; $30,000: bitcoin lost for want of a PIN; 40%: increased learning speed using direct current stimulation; 1 million: IoT devices owned by Reaper; $52.6 billion: Apple quarterly revenue;
- Quotable Quotes:
- @pasiphae_goals: #33: go’s compiler is extremely fast, giving you ample time to debug data races and deadlocks.
-
Tim O'Reilly: we can choose instead to lift each other up, to build an economy where people matter, not just profit. We can dream big dreams and solve big problems. Instead of using technology to replace people, we can use it to augment them so they can do things that were previously impossible.
-
André Staltz: These are no longer the same companies as 4 years ago. GOOG is not anymore an internet company, it’s the knowledge internet company. FB is not an internet company, it’s the social internet company. They used to attempt to compete, and this competition kept the internet market diverse. Today, however, they seem mostly satisfied with their orthogonal dominance of parts of the Web, and we are losing diversity of choices. Which leads us to another part of the internet: e-commerce and AMZN...In the Trinet, we will have even more vivid exchange of information between people, but we will sacrifice freedom. Many of us will wake up to the tragedy of this tradeoff only once it is reality.
-
@math_rachel: Data is not neutral. Data will always bear the marks of its history.
-
Jeff Bar: p3.16xlarge is 2.37 billion times faster, so the poor little PC would be barely halfway through a calculation that would run for 1 second today
-
@krishnan: I criticized Google calling their App Engine Serverless during their cloud conference Here @ben11kehoe says the same
-
F5: The obvious lesson is that the state of IoT security is still incredibly poor, and we need to do a better job of threat modeling6 the Internet7 of8 Things9.
-
Jakub Kasztalski: I just downloaded one of the pirated copies of my game. They asked me to remove my ad-blocker to keep their site running. Oh the sweet irony
-
Dart: The car would start drifting to side of the road and not know how to recover. The reason for the car’s instability was that no data was collected on the side of the road. During the data collection the supervisor always drove along the center of the road; however, if the robot began to drift from the demonstrations, it would not know how to recover because it saw no examples.
-
Tim O'Reilly: The company wanted to know how to get more developers for its platform. David asked a key question: “Do any of them play with it after work, on their own time?” The answer was no. David told them that until they fixed that problem, reaching out to external developers was wasted effort.
-
@swardley: X: Why do you think Amazon is so dangerous? Don't you think they will slow down?Me: No, they'll get faster.
-
@whispersystems: Signal is back after a brief service interruption. We appreciate your patience as we added more capacity to resolve connection errors.
-
lwansbrough: What the hell is taking up all that RAM? Slack is using over 800MB of RAM on my computer right now, and it's completely idle. I've got a C# process on my computer right now handling thousands of messages per second and consuming 1/20th the RAM. If you rebuild Slack in Xamarin you'd probably drop your RAM consumption to under 50MB, just a guess. JS fiends are gonna tell me C# ain't JS, and I agree. TypeScript ain't JS either, and it's a hell of a lot closer to C# than it is JS.
-
@vgill: Large-scale distributed systems are less about cool algorithms and more about the relentless hunting down of 6-sigma bugs.
-
@JefClaes: Very impressed w my first experience with columnar storage (Redshift). 200GB table compresses into a 25GB table.
-
@chethaase: A Machine Learning algorithm walks into a bar. The bartender asks, "What'll you have?" The algorithm says, "What's everyone else having?"
-
StackOverflow: The most disliked languages, by a fairly large margin, are Perl, Delphi, and VBA. They’re followed by PHP, Objective-C, Coffeescript, and Ruby. On our team we’re certainly happy to see that R is the least disliked programming language, relative to the number of people who liked it.
-
@rob_pike: Imagine how fast that compiler would be on today's hardware. The 3s limit it had for compile and go on the UT HSJS would be ~1ms today.
-
copenja: [Steve Jobs] is widely considered to be a genius and given nearly sole credit for a wide range of innovations. I think it's okay for the guys who invented the GUI to also get a small fist bump.
-
@gpakosz: What a terrible advice. You will never learn as much as when implementing things. Otherwise you never go beyond abstractions’ demo use case.
-
Ben Kehoe: I’m still of the opinion that orchestration is superior to in-code direction of control flow for serverless architectures. Whether that orchestration should be declarative, like the States Language, or imperative, like IBM Cloud Composer, is an open question — and maybe a wash.
-
David Gerard: How’s Bitcoin Gold going? Well, the code doesn’t actually build yet. If only they’d understood the function of #include! Also, there doesn’t appear to be any mining or a publicly available blockchain. Even Bitcointalk wasn’t impressed. It’s interesting to see the “free money fork” model fail on literally the second attempt.
-
linsomniac: Don't get me wrong, I love Postgres, been using it since '96, but Influx/Telegraf/Grafana has given me the ease of Munin with the high resolution data of collectd while also providing low overhead and low maintenance.
-
David Rosenthal: Thus engineering devoted to reducing infant mortality is much more profitable than engineering devoted to extending the drives' service life. Extending service life beyond the current five years is wasted effort, because unless Kryder's law slows even further, the drives will be replaced to get more capacity in the same slot.
-
scrollaway: I don't want to make it sound like Vagrant isn't solving a real problem though, it is. It's just not the unicorn it claims to be.
-
Charlie Hess: With the exception of LSD, there’s no shorter path to questioning your reality than embarking on a large refactor in a JavaScript codebase
-
@housecor: Much of writing testable code boils down to this: Keep logic and I/O separate. Then you can test logic in isolation without mocking.
-
Shubheksha: A better approach [to Distributed Computing] is to accept that there are irreconcilable differences between local and distributed computing, and to be conscious of those differences at all stages of the design and implementation of distributed applications.
-
slackingoff2017: LEDBAT is similar but works on L7 instead of L4 and needs support on both ends. BBR is excellent. It's the first congestion control strategy to really focus on fairness rather than trying to send packets as fast as possible. Combined with fq-CODEL, BBR finally offers a way to load balance traffic on your NAT without allowing someone to monopolize bandwidth
-
Rich Hickey (video): Clojure's target is information-driven situated programs, right? There's not a catchy phrase for that. But I mean that's what I was doing, all my friends were doing that. How many people in this room are doing that? Yeah. So when you look at programming languages, you really should look at...what are they for? Right? There's no like inherent goodness, like suitability constraints.
-
kmax12: There is so much focus on the machine learning algorithms rather than getting data ready for the algorithms. While there is a question that lets respondents pick which of 15 different modeling algorithms they use, there's nothing that talks about what technologies people use to deal with "dirty data", which is agreed to be the biggest challenge for data scientists. I think more formal study of data preparation and feature engineering is too frequently ignored in the industry.
-
throwawayjava: the really interesting thing about clojure is not its design but rather clojure.spec. Sure, you lose a lot of static guarantees, and along with them some of the maintainability/correctness that come along with statically typed languages. But perhaps recovering static checks, and tooling based on static checks, is best done on a library-by-library basis via compositional specification checkers specialized to the particular library. Rather than by a single general-purpose type theory that's rich enough for the "real problems in the messy world" type of programming.
-
Animats: I got the tour of PARC in 1975, years before Jobs. Smalltalk wasn't really working yet, but some Altos and Ethernet were running. Kay described Ethernet as an "Alohanet with a captive ether". They had a file server and a laser printer starting to work. So what they had was the beginnings of an office environment of the 1990s. Kay's point at the time is that this was what you could do if you were willing to spend a large amount of money per user on hardware. It wasn't cost-effective yet. Someday it would be. Xerox was willing to spend the money, so when the hardware became available, they'd own the market.
-
@rezendi: The Plasma paper reads like it was written one afternoon by a hyperactive dog who had 47 Diet Cokes before lunchtime and then saw a squirrel
-
Tim Bray: what I think customers care about most is confidence that the services, cool or boring, will be there 24/7/365. What that means is that everything has to be automated, and much of the most brilliant engineering at AWS, done by some of the smartest people, does its work behind the scenes where nobody will ever see it.
-
Dan Fabulich: tl;dr: Google wants you to build PWAs (Progressive Web Apps), reduce JavaScript file size, use Web Components, and configure autofill. They announced only a handful of features around payments, authentication, Android Trusted Web Activities, Chrome Dev Tools, and the Chrome User Experience Report.
-
moultano: I'd take a slightly different take: - Structure your code so it is mostly leaves. - Unit test the leaves. - Integration test the rest if needed. I like this approach in part because making lots of leaves also adds to the "literate"-ness of the code. With lots of opportunities to name your primitives, the code is much closer to being self documenting.
-
yourbasicgeek: The OWASP Top 10 is killing me, and killing you! The Open Web Application Security Project publishes its Top 10 web development mistakes that often lead to security vulnerabilities. Many items on the list haven't changed since the 2013 and 2010 reports. In other words, we're still screwing up.
-
Ben Tengelson: Split violin plots are a great way to visualize your data at a quick glance, especially when dealing with binary classification problems.
-
Alex "Sandy" Pentland: Current AI is making all these little approximations, and together they may come up to be something useful, but the perception is not in their model. The science would only be in our perception of the model.
-
MIT Tech Review: The bureau anticipates a rise in demand for statisticians, mathematicians, and software developers—occupations that will build the algorithms to control the machines that replace traditional manufacturing workers. Fulfillment jobs for online retailers will continue to grow in number, too, helping to blunt the impact of losing so many manufacturing roles.
-
Kowalczykowski: We’ve shown that there is no coordination between synthesis of the two [DNA] strands. They are completely autonomous. What looks like coordination is actually the outcome of a random process of starting, stopping and variable speeds.
- Ken Shirriff: cells are nothing like the nice, peaceful animations. Cells are extremely crowded and things move extremely fast. Glucose molecules, for instance, move around cells at 250 miles per hour and collides with something billions of times a second. An enzyme might collide with a reactant 500,000 times a second. And proteins can spin a million times per second. So as you suspect, by random chance molecules are in the right spot very frequently.
- Alex Russell: performance budgets are an essential but under-appreciated part of product success and team health. Most partners we work with are not aware of the real-world operating environment and make inappropriate technology choices as a result. We set a budget in time of <= 5 seconds first-load Time-to-Interactive and <= 2s for subsequent loads. We constrain ourselves to a real-world baseline device + network configuration to measure progress. The default global baseline is a ~$200 Android device on a 400Kbps link with a 400ms round-trip-time (“RTT”). This translates into a budget of ~130-170KB of critical-path resources, depending on composition — the more JS you include, the smaller the bundle must be.
- mabbo: Having done Amazon on-call for five years, I can give some background on that. First, the front-line pager duty is usually hit by an ops eng team first. Each of those teams has an India group and an North America group. If they can't resolve the issue, they page in the developers. Having good Ops Eng guys supporting you is a blessing. There's also a very strong incentive for teams to write good software and test before deploying when you know damn well that if you're deploying something that doesn't work, you're the guy who will have to deal with it at 3am. Having strong integration and system tests suddenly becomes incredibly important
- Smerity: The P3 instances are the first widely and easily accessible machines that use the NVIDIA Tesla V100 GPUs. These GPUs are straight up scary in terms of firepower. To give an understanding of the speed-up compared to the P2 instances for a research project of mine: + P2 (K80) with single GPU: ~95 seconds per epoch + P3 (V100) with single GPU: ~20 seconds per epoch. Admittedly this isn't exactly fair for either GPU - the K80 cards are straight up ancient now and the Volta isn't sitting at 100% GPU utilization as it burns through the data too quickly ([CUDA kernel, Python] overhead suddenly become major bottlenecks). This gives you an indication of what a leap this is if you're using GPUs on AWS however. Oh, and the V100 comes with 16GB of (faster) RAM compared to the K80's 12GB of RAM, so you win there too. For anyone using the standard set of frameworks (Tensorflow, Keras, PyTorch, Chainer, MXNet, DyNet, DeepLearning4j, ...) this type of speed-up will likely require you to do nothing - except throw more money at the P3 instance :) If you really want to get into the black magic of speed-ups, these cards also feature full FP16 support, which means you can double your TFLOPS by dropping to FP16 from FP32.
- Ben Kehoe: So let me see if I’ve got this straight: I need to take my microservice, which were already small pieces of my original application, into even smaller functions (unless I’m using GraphQL), in a supported language, and this runs on servers that I don’t need to care about, except that I do sometimes, especially for cold starts. I replace all of the rest of my application with services, which are probably similar to the things I’m using, but if they are different, I don’t have a choice anyway. Deploying anything beyond a simple application is super complicated, nobody’s figured out how to update them properly, and local debugging is barely possible. Is that it?
- Xavier Amatriain: I will go on record and say that in my opinion Alpha Go Zero represents the most significant research advance in AI in the last few years...Why am I saying that?... It is about the fact that Alpha Go Zero learned without any data! This is a feat that can not be understated. We have all hear about the “Unreasonable effectiveness of data”. We have all heard how data-hungry deep learning approaches are. Well, it turns out that (under some constraints) we don’t need data at all! The only thing that was input into the model was the basic rules of the game, not even complex strategies or known “tricks”.
- A lot of good advice. How did you significantly reduce your AWS cost? trjordan: Tactically: spot instances, reserved instances, auto-scaling groups, deleting data that we didn't need. Strategically: I've only ever see it work by making it somebody's job to save money on Amazon, ahead of feature velocity. Find a tool that analyses where you're spending [0], pick the biggest bucket of spend you don't really understand, and drill down until you're sick of looking at it. Make some optimizations around how you're spending that money, rinse, repeat. primax: My favorite that most people miss is the S3 VPC endpoint. Putting an S3 endpoint in your VPC gives any traffic to S3 it's own internal route, so it's not billed like public traffic. I've seen several reductions in the 20-50k a month range with this one trick. Otherwise, stop doing baremetal processes on the cloud. It's dumb. For instance, I see people operating a file gateway server (with 5 figure a year licensing costs) on ec2 using EBS storage. This is a perfect use case for replacement with S3, with lambda code running in response to whatever file gateway event you're monitoring. Lastly, you need to really challenge people's conceptions about when resources need to be in use. Does a dev/test site need to be running the 16 hours that people are not at work? Of course not, except when people are staying late. So you create incentives to turn it off, or you run it on something like ECS or kubernetes with software to stop containers if they're not actively used in a 15 minute window (and then the cluster can scale down). mottomotto: I found OVH is more affordable than DigitalOcean depending on your needs. ebrewste: We stopped storing our IoT raw data in databases. We still need to search it, but now we store only metadata in the database and store the raw data in S3. PebblesHD: After cleaning up all our unneeded instances and optimising our architecture, we finally realised that our developer stacks and test environments didn’t need to run 24/7, which has so far been the biggest single cost saving we’ve implemented. By only running stacks from 8am-8pm then stopping everything, we’re getting a 50% saving on our instance costs. Spotting a Million Dollars in Your AWS Account. kennu: I had lots of DNS zones in Route 53 that didn't really need to be there. So I moved a bunch of them to ClouDNS...I realized that DynamoDB autoscaling is relatively expensive for a large number of tables, because it sets up multiple CloudWatch Alarms for each table. So I turned off autoscaling for tables that don't really need it. I have started to replace DynamoDB tables with Cloud Directory instances in cases where I don't want to have the fixed cost of tables sitting idle. a012: for EBS in general, if your application is not IOPS intensive, use large gp2 volumes instead. CoolGuySteve: Rather than spot instances, use spot fleets and structure your bid such that you arbitrage across different node types and data centers that are equivalent for you. We cut our spot expenses by 20%. itomato: Blueprint your Footprint. endymi0n: We moved to Google Cloud Platform. D3m0lish: For consumer compute consider serverless (api gateway and lambda) - this addresses the problem of idle/pre-prod environments. - Data at rest: consider s3, retention policies and glacier. - Consider aggressive retention policies on cloudwatch logs, watch out for unnecessary cloudwatch metrics (I still prefer statsd because of the percentiles) - If you use Kinesis - monitor In/Out bytes and provision shards as needed, control retention. - Watch out for cross region/hybrid (on prem) stacks - data transfer is very expensive and not obvious. - Use reserved instances. - Remove unused EBS volumes. - Watch out for high IO EBS volumes. - Use Cloudfront to cache static content.
- We learnt a great deal by changing our RDBMS oriented mindset. Here's how Walmart Avoid pitfalls in scaling your Cassandra cluster: lessons and remedies: Pitfall 1: Get your partitions right: Of all the tunings, strategies, tricks that can be applied to Cassandra to gain performance, designing the most optimal schema had the biggest impact in terms of latency, stability, and availability of the cluster. Pitfall 2: Ensure separation of concerns: We finally replaced Cassandra + Solr combination with SolrCloud and the performance has been excellent after the switch with throughput improving significantly! Pitfall 3: Avoid full reads/writes: A better approach would be to read selectively wherever possible. Pitfall 4: Beware of collections: A general mistake is to read the collection in the application, modify it, and then write it back. Pitfall 5: Driver tunings: Driver tuning has a lot of impact on how the queries perform.
- we managed to serve [539 requests a second] on a shoestring budget. About 50 cents over 2 days.
Squeezing every drop of performance out of a Django app on Heroku: If you can avoid it, don’t have user logins. Your life is much easier if pages are fully cacheable...Cloudflare is free and does several useful things by default...We’ve added one extra thing: serving HTML through the CDN, which we can do because most of the pages are static. In theory, this means most requests won’t even touch Django...Serve static assets with WhiteNoise and Cloudflare...In a Heroku dyno’s 512MB of memory, you can serve around 3 concurrent requests...To serve other requests while this is happening, Gunicorn can spin up additional workers using Gevent. Unlike forking, Gevent workers consume very little additional memory, so you can run hundreds of them...pool your database connections so the Gevent workers can share connections. - Here's a blast from the past. My how the world has changed. More Taste: Less Greed? or Sending UNIX to the Fat Farm: You (like us) have 80 to 90 Sun 3/50 machines with 4 megabytes of memory. You have been given some optical discs containing System V.4. Which can you least afford to discard? Things are getting out of hand. Soon, 32 megabyte Ultrasparks will be needed just for us to start the window system in under a minute
- The AWS Lambda & Serverless team held a reddit AMA. Informative, but nothing particularly noteworthy.
- Deadlocks happen in hardware too. Dealing With Deadlocks: imagine Processor A is waiting on data from Processor B before it responds, and Processor B is doing the same thing. Neither is doing anything incorrectly, Ramanujam explained. “They are both doing the right thing in their own universe...At the system level, the focus shifts more to system-level verification, where the idea is to determine whether the IPs play nicely with each other.
- Azure will now give you 12 months of free access to popular products.
- Combining connection pooling and database load balancing allowed us to drastically reduce the number of resources necessary to run our database cluster as well as spread load across our hot-standby servers. For example, instead of our primary having a near constant CPU utilisation of 70 percent today it usually hovers between 10 percent and 20 percent, while our two hot-standby servers hover around 20 percent most of the time. Scaling the GitLab database: For a long time GitLab.com used a single PostgreSQL database server and a single replica for disaster recovery purposes...Using pgbouncer we were able to drop the number of active PostgreSQL connections from a few hundred to only 10-20 by using transaction pooling. We opted for using transaction pooling since Rails database connections are persistent...Our solution essentially works by replacing ActiveRecord::Base.connection with a proxy object that handles routing of queries. This ensures we can load balance as many queries as possible, even queries that don't originate directly from our own code...Sticky connections are supported by storing a pointer to the current PostgreSQL WAL position the moment a write is performed...Our background processing code always uses the primary since most of the work performed in the background consists of writes...To deal with connection errors our load balancer will not use a secondary if it is deemed to be offline.
- Occupy the cloud: distributed computing for the 99%: speed of deployment and ease of use coupled with good enough runtime performance wins. DevOps are the new Kingmakers. Follow that line-of-thought, and the authors take you to an interesting proposition: serverless could be the centrepiece of a new distributed data processing platform.
- Is Intel's new 3D XPoint memory technology living up to the hype? Not yet. The Intel Optane SSD 900P 280GB Review: will still cause some sticker shock for consumers expecting prices in line with M.2 PCIe SSDs...it would work well as a blazing fast primary storage device...the sequential transfer speeds are nothing special for a NVMe SSD these days...The random read and write IOPS are far higher than any consumer SSD has offered before...power consumption show one big reason why the Optane SSD 900P is a desktop-only product...the 10 drive writes per day write endurance rating is far higher than most consumer SSDs get; 0.3 DWPD is more typical. iwod: What i think will be interesting, is the use of Optane SSD on Database server, with those kind of latency, Random Read Write, and Endurance, it think this is going to be a gigantic leap forward. CaedenV: Come on Intel! Storage isn't what this tech is made for! This was supposed to have faster throughput and act as a RAM replacement, not SSD replacement! Kevin G: The really big disappointment is this launch doesn't point toward living up to the remaining hype at all. The lack luster capacity today certainly implies that the DIMM sizes necessary to threaten DRAM may not happen. 128 GB registered ECC DDR4 LR-DIMMs are out there today and 256 GB models are on the horizon. From the looks of it, Optane could make the 256 GB capacities in DIMM form and certainly come in cheaper but that wouldn't be as large of a game changer. bkeroack: 500k sustained random IOPS from a single device is remarkable. To put that in perspective, 500k PIOPS in AWS would cost you $32,500/month. Reflex: Optane is a technology. Today's article is about a product, which happens to use Optane in combination with other technologies. Intel's statements about Optane were about the capabilities of the technology. And indeed, for those who know much about PCM they were reasonable statements. Actual products are not guaranteed to maximize the ultimate potential of a given technology, especially in their first revisions. In 1995 when most motherboards were transitioning from a BIOS ROM to a Flash BIOS, a company could have stated that the potential for Flash was 1000x the performance of the older ROM based technologies. And they would have been correct. Even though the earlier Flash devices achieved speeds only of a couple MB/sec.
- Access to QPX Express API for airfare data is being shut down by Google. The lesson is clear: don't build a business on Google APIs.
- How Droplr Scales to Millions With The Serverless Framework: More than 50% of Droplr services are already migrated to Lambda. Every month, new APIs are moving there. For new microservices, it's our new standard to build them on top of Serverless Framework.
- Changing technology really let's you do a rethink of how things can and should work. Designing Streets for Self-Driving Cars: Parks Instead of Parking Meters: So what does transit heaven look like? In the future, the transportation planners suggest, vehicle lanes can be a lot thinner. Machines, after all, should be better at driving straight—and less distracted by Snapchat—than their human counterparts. That means more room in major boulevards for walking, biking, even loitering. Tiny parks might exist where parking meters once lived—no need to park self-driving taxis owned by companies, not individual drivers. In fact, vehicles might not even have their own dedicated spaces at all. “Flex zones” could be turned over to different services and vehicles for different times of day. During rush hour, there could be more lanes open to vehicles. During heavy delivery hours, there could be curb space dedicated to Amazon delivery vans (or landing delivery drones). Also, Blueprint for Autonomous Urbanism.
- Microservices...on the frontend? Front-end Microservices at HelloFresh: A front-end microservice listens on one or more HTTP hooks (endpoints) and serves the page HTML and links to scoped CSS and JavaScript...If the CDN doesn’t have a recent cached copy of this page, it will direct the request to our entry server which will then forward it to one of our fragments. I drew the RAF (recipe archive fragment), the FF (funnel fragment) and the MDF (my deliveries fragment) here to portray a part of our infrastructure. The fragments in turn will request parts (particles) of the page from the gateway. These particles will return the HTML and CSS needed for the fragment to return a full render. As fragments are cached by the CDN the experience is lightning fast...While previously we had this huge monolithic application that was unmaintainable and nigh-on unbootable in a local environment, now each project has its own server, and its isolated dev environment. sergiotapia: Am I the only one who thinks this is insane and a product of an architecture astronaut? Their whole workflow sounds absolutely exhausting and something ripped straight from the movie Brazil. Layers upon layers upon layer. This is nuts.
- Why would anyone choose Docker over fat binaries?: Docker is a tool that allows you to continue to use tools that were perfect for the1990s and early 2000s. You can create a web site using Ruby On Rails, and you’ll have tens of thousands of files, spread across hundreds of directories, and you’ll be dependent on various environmental variables...Docker is a fantastic achievement in that it allows apps written for one age to continue to seem viable in the current age. However, Docker has a heavy price, in that brings in a great deal of new complexity...But when it comes to managing dependencies or configuration or file systems or paths, I feel confident in saying that Docker is a complete waste of time. For every situation where some developers advocate Docker, I would instead advocate fat binaries. itistoday: Docker has nothing to do with fat binaries. It’s all about creating containers for security purposes. That’s it. It’s about security. adamrt: I use it for managing many projects (go, python, php, rails, emberjs, etc) with many different dependencies. Docker makes managing all this in development very easy and organized. apy: My, limited, experience with Docker has been: It’s always changing and hard to keep up, and sometimes changing in backwards breaking ways. Most container builds I come across are not reproducible, depending on HEAD of a bunch of deps, which makes a lot of things more challenging. Nobody really knows what’s in these containers or how they were built, so they are big black boxes.
- Murat reports on HPTS'17 day 0: Computers hate me...I mentioned about the WAN Paxos protocol I am working on. They were more interested about the semantics of its transaction model, and asked me whether it was MVCC and used snapshot isolation (the answer for our WAN Paxos is no)...We talked about CockroachDB transaction commit protocol. The protocol starts like snapshot isolation, with the reads from a given timestamp, but at commit time it serializes commits and prevents conflicts in a pessimistic manner. That is, unlike the snapshot isolation example above, the protocol checks for the timestamps of the reads at Transaction 1 and Transaction 2 and would not allow those transactions to both commit since both transactions' timestamps are 0 and they overlap accessing same variables...closing restructuring a datacenter is a good chance to get rid of all that junk, much like how we get rid of junk files in our old laptops --by buying a new laptop
- Our battery hungry future will be fed. Will metal supplies limit battery expansion?: The study looked out over the next 15 years, and within that time frame, Olivetti says, there are potentially some bottlenecks in the supply chain [for lithium-ion batteries], but no serious obstacles to meeting the rising demand.
- Backblaze has released Hard Drive Stats for Q3 2017: The hard drive failure rate for the quarter was 1.84%, our lowest quarterly rate ever...The 10- and 12 TB drive models are new. With a combined 13,000 drive days in operation, they’ve had zero failures...8 TB Consumer Drives: 1.1% Annualized Failure Rate...8 TB Enterprise Drives: 1.2% Annualized Failure Rate...are the Seagate 8 TB enterprise drives worth any premium you might have to pay for them?
- NVIDIA GPU Cloud: a GPU-accelerated cloud platform that makes it easy to get started quickly with the top deep learning frameworks on-premises or on Amazon Elastic Compute Cloud (Amazon EC2) and other cloud providers coming soon. coolspot: Basically a set of fine-tuned virtual machine images for Amazon Cloud. Also, High-Performance GPU Computing in the Julia Programming Language.
- Shame making something faster requires an apologia. Netflix functions without client-side React, and it's a good thing: Frameworks are an abstraction. They make a subset of tasks easier to achieve, in a way that's familiar to other users of the framework. The cost is performance – the overhead of the framework. The key is making the cost worth it. I have a reputation for being against frameworks, but I'm only against unnecessary usage, where the continual cost to users outweighs the benefit to developers. But "only use a framework if you need to" is easier said than done. You need to decide which framework to use, if any, at the start of a project, when you're least-equipped to make that decision. If you start without a framework, then realize that was a mistake, fixing it is hard. Unless you catch it early enough, you can end up with lots of independent bits of script of varying quality, with no control over their scheduling, and duplication throughout. Untangling all that is painful. Similarly, it's often difficult to remove a framework it turns out you didn't need. The framework 'owns' the project end-to-end. Framework buy-in can leave you with a lot of simple buttons and links that now have a framework dependency, so undoing all that can involve a rewrite. However, this wasn't the case for Netflix.
- On Disk IO: Access Patterns in LSM Trees: all write operations in LSM Trees are sequential: Write-Ahead Log appends, Memtable flushes, Compactions. Using per-SSTable indexes or pre-sorting data can also help to make at least some read operations sequential. It can only be done to a certain extend as reads have to be performed against multiple files and then merged together.
- Rust is oxidizing fast. Fun facts about Rust's growing popularity: 1) There are now 100 friends of Rust (Be sure to hover to learn about how each company uses Rust) 2) There are now 3 Rust podcasts: New Rustacean, Rusty Spike, and Request for Explanation 3) First year had one conference, the second year had three, and this year had four...
- Deep Voice 3 (paper): By implementing GPU kernels for the Deep Voice 3 architecture and parallelizing another section of workload on CPUs, Baidu is able to address ten million queries per day (116 queries per second) on a single GPU server with a 20-core CPU. In other words, this is not only interesting from an application perspective, but also highlights major progress in making both training and inference highly efficient. Baidu says that this architecture trains an order of magnitude faster, allowing the team to scale over 800 hours of training data and synthesize speech from the massive number of voices—all with their own distinct inflections and accents. The Deep Voice 3 architecture is a fully-convolutional sequence-to-sequence model which converts text to spectrograms or other acoustic parameters to be used with an audio waveform synthesis method. Baidu uses low-dimensional speaker embeddings to model the variability among the thousands of different speakers in the dataset.
- How Facebook uses GraphQL Subscriptions for Live-Updating Features with cool animations. Facebook, uses GraphQL subscriptions in Live Likes, Live Comments, Typing Indicators, Live Video Streaming Reactions, Live Video Comments, etc. Though it's not clear why GraphQL is a win. Also, Introducing the Graphcool Framework.
- All things Linux Performance by Brendan Gregg.
- The life of content creators is pain. It seems book and game authors have converged on similar strategies for making a living in hard cruel zero marginal production cost digital world. There Has to be Another Way to Make Indie Games. The approach is similar to what indie authors are doing with kindle: "To fix this highly risky process. I am distributing risk by making smaller games and releasing them more quickly. At most, release a game every 12 months. Or, ideally, release every 6 months. If this seems to slow, shrink each game’s size and release one every quarter." On kindle, some authors try to write a new book every month. To sell better, book authors are told to write to market. Games also seem to do better when they fit nicely into crisp categories: "I know this is going to sound like sacrilege to indie devs... but I plan to make less original games. It is incredibly difficult and costly to invent a new genre or mechanic." Book authors are also told to write a series instead of individual books. Same for games: "Stick to a genre and make sequels." Releasing a new book even has some of the same downsides as releasing a new game: "My biggest fear with the current system of releasing indie games is that too much is put on a single game. Years and years go into making the game perfect and because you spent so much time on it, the game must be better than all previous and all other games in the same genre. When you do finish the game, the release must go flawlessly. The right day must be selected so it does not get drowned out by another major release (impossible considering something like 127 games release every day on Steam.) All enthusiast review websites must release their reviews at the same time. Popular Twitch and Youtube streamers must also release their videos. Two to three (or even five years) of work rests on this one week where you are hopefully featured by the various stores. Daniel Cook describes this process as “firing a solid gold cannonball at a moving target while wearing a blind fold” If this doesn’t go well, your efforts for the last half decade have been a tiny, worthless splash in the deep deep ocean." Much of the rest of the advise is the same given to book authors.
- The answer to, "What do you want, a pony?", seems to be yes. Why we used Pony to write Wallaroo. What is Pony? an open-source, object-oriented, actor-model, capabilities-secure, high-performance programming language. What is Wallaroo? a distributed data processing framework for building high-performance streaming data applications. Results: leveraging the Pony runtime has been a huge win for us. If we had written our own runtime that had similar performance characteristics, I’m not sure we’d be done yet...On top of that, we have gotten the excellent performance we set out to achieve, and with the support of the Pony’s type system, we are far more confident when we write and refactor code.
- The fear and frustration of migrating a simple web app to serverless. Lift and shift into Lambda is like using a light agile drone as a big bulky passenger plane, they are two very different things. Using a serverless framework without understanding how the whole thing works isn't a recipe for success. Neither is using RDS, all the little tricks like caching and connection pooling won't work. Set up a separate instance to manage connections. Cognito is hard to get working correctly. Agreed. And using Node is probably the easiest way as it's the road most traveled.
- Implementing Stripe-like Idempotency Keys in Postgres. Excellent explanation with code examples and schema definitions. Transactions make a lot of things easier. The request lifecycle: When a new rides comes in we’ll perform this set of operations: 1. Insert an idempotency key record. 2. Create a ride record to track the ride that’s about to happen. 3. Create an audit record referencing the ride. 4. Make an API call to Stripe to charge the user for the ride (here we’re leaving our own stack, and this presents some risk). 5. Update the ride record with the created charge ID. 6. Send the user a receipt via email. 7. Update idempotency key with results.
- Queueing Theory in Practice. Unfortunately just a slide deck, but it still looks useful.
- Nice overview of RIPE 75 (Internet policy?): Richard Cziva presented on his research work in building a real time TCP latency measurement tool capable of visualising traffic carried on a 10G circuit...ARCEP reported on a couple of recent issues concerning interconnection disputes in France...Its distinctive feature is the ability to perform near-real time feeds out of the route collector, using a path attribute compression technique to allow the system to operate efficiently and quickly...Nokia’s Greg Hankins reported on some recent work in refining aspects of the way that BGP works...Babak Farrokhi from Iran gave a fascinating presentation on the DNS in a curious case of broken DNS responses...we heard of the work in Sweden to install a green fields 100G backbone network for the national academic and research sector.
- Gil Tene on Java at Speed: Getting the Most out of Modern Hardware. He knows his stuff. Always a good source of insight.
- Apache Arrow vs. Parquet and ORC: Do we really need a third Apache project for columnar data representation?: Surprisingly, the row-store and the column-store perform almost identically, despite the query being ideally suited for a column-store. The reason why this is the case is that I turned off all CPU optimizations (such as vectorization / SIMD processing) for this query. This resulted in the query being bottlenecked by CPU processing, despite the tiny amount of CPU work that has to happen for this query (just a simple integer comparison operation per row). To understand how it is possible for such a simple query to be bottlenecked by the CPU, we need to understand some basic performance specifications of typical machines. As a rough rule of thumb, sequential scans through memory can feed data from memory to the CPU at a rate of around 30GB a second. However, a modern CPU processor runs at approximately 3 GHz --- in other words they can process around 3 billion instructions a second. So even if the processor is doing a 4-byte integer comparison every single cycle, it is processing no more than 12GB a second --- a far smaller rate than the 30GB a second of data that can be sent to it. Therefore, CPU is the bottleneck, and it does not matter that the column-store only needs to send one sixth of the data from memory to the CPU relative to a row-store.
- Interesting idea. Service Discovery With CRDTs: Service Discovery is a mechanism to resolve the address of a service we want to communicate to...DNS is the well known mechanism to resolve IP address and PORT for a service name. DNS SRV records are registered with the DNS server and can be resolved using standard DNS resolution mechanism...mDNS is a zero configuration alternative which is popular for small intranets and home networks...Zookeeper is a centralized service used to maintain configuration or naming information...Etcd is a linearizable key-value store based on raft consensus protocol. It is used as service registry...Consul is a full fledged service discovery solution...Distributed Data extension with Akka-Cluster, natively supports Conflict Free Replicated Datasets or CRDTs for short. CRDTs make an excellent choice for maintaining service registry...The key aspect of CRDTs is that they are replicated across multiple computers. They can be updated on different nodes without coordinating with other nodes.
- marko-js/marko (article): A friendly (and fast!) UI library from eBay that makes building web apps fun
- google/netstack: IPv4 and IPv6 userland network stack written in Go.
- TileDB (paper): manages data that can be represented as dense or sparse arrays. It can support any number of dimensions and store in each array element any number of attributes of various data types.
- softvar/awesome-web-storage: Everything you need to know about Client-side Storage.
- Synthesizing Robust Adversarial Examples: This work shows that adversarial examples pose a practical concern to neural network-based image classifiers. By introducing EOT, a general-purpose algorithm for the creation of robust examples under any chosen distribution, and modeling 3D rendering and printing within the framework of EOT, we succeed in fabricating three-dimensional adversarial examples. In particular, with access only to low-cost commercially available 3D printing technology, we successfully print physical adversarial objects that are strongly classified as a desired target class over a variety of angles, viewpoints, and lighting conditions by a standard ImageNet classifier.
- Eris: Coordination-Free Consistent Transactions Using In-Network Concurrency Control: Distributed storage systems aim to provide strong consistency and isolation guarantees on an architecture that is partitioned across multiple shards for scalability and replicated for fault tolerance. Traditionally, achieving all of these goals has required an expensive combination of atomic commitment and replication protocols – introducing extensive coordination overhead. Our system, Eris, takes a different approach. It moves a core piece of concurrency control functionality, which we term multi-sequencing, into the datacenter network itself. This network primitive takes on the responsibility for consistently ordering transactions, and a new lightweight transaction protocol ensures atomicity. The end result is that Eris avoids both replication and transaction coordination overhead: we show that it can process a large class of distributed transactions in a single round-trip from the client to the storage system without any explicit coordination between shards or replicas in the normal case. It provides atomicity, consistency, and fault tolerance with less than 10% overhead – achieving throughput 3.6–35× higher and latency 72–80% lower than a conventional design on standard benchmarks.
- Towards Deploying Decommissioned Mobile Devices as Cheap Energy-Efficient Compute Nodes: This work proposes creating a compute dense server built out of used and partially broken smartphones (e.g. screen can be broken). This work evaluates the total cost of ownership (TCO) benefit of using servers based on decommissioned mobile devices and analyzes some of the architectural design trade-offs in creating such servers.



