Stuff The Internet Says On Scalability For July 13th, 2018

Hey, it's HighScalability time:
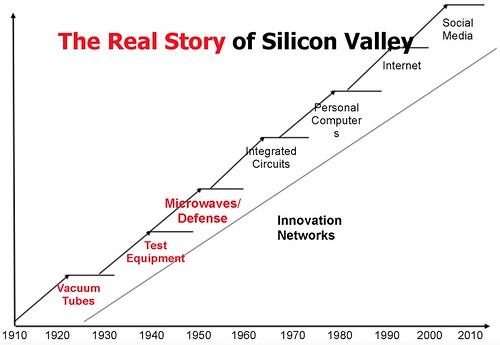
Steve Blank tells the Secret History of Silicon Valley. What a long, strange trip it is.
Do you like this sort of Stuff? Please lend me your support on Patreon. It would mean a great deal to me. And if you know anyone looking for a simple book that uses lots of pictures and lots of examples to explain the cloud, then please recommend my new book: Explain the Cloud Like I'm 10. They'll love you even more.
- $27 billion: CapEx invested by leading cloud vendors in first quarter of 2018; $40 billion: App store revenue in 10 years; $57.5 billion: venture investment first half of 2018; 1 billion: Utah voting system per day hack attempts; 67%: did not deploy a serverless app last year; $1.8 billion: made by Pokeman GO; $13 billion: Netflix's new content budget;
- Quotable Quotes:
- @davidbrunelle: The best developers and engineering leaders I've personally worked with do *not* have a notable presence on GitHub or public bodies of speaking or writing work. I worry that a lot of folks confuse celebrity and visibility with talent and ability.
- Bernard Golden: The tech industry has never seen this level of investment [in datacenters]. The investment we’re seeing in cloud capacity really has no precedent, save perhaps Henry Ford’s manic factory building for his Model T, the US government’s armaments efforts in WWII, and Foxconn’s manufacturing support for smartphones. As Ford’s efforts presaged the boom growth of the industrial economy, so too do (cloud) investments augur the explosion of the digital economy.
- @kellabyte: The issue with microservices is it’s taught people to stop thinking about cohesiveness. Cohesiveness is really important. When you fight against it you experience major pain and Service Autonomy works much better as a cohesive unit not just making “micro” things everywhere.
- Leslie Lamport: Today, programming is generally equated with coding. It's hard to convince students who want to write code that they should learn to think mathematically, above the code level, about what they’re doing. Perhaps the following observation will give them pause. It's quite likely that during their lifetime, machine learning will completely change the nature of programming. The programming languages they are now using will seem as quaint as Cobol, and the coding skills they are learning will be of little use. But mathematics will remain the queen of science, and the ability to think mathematically will always be useful.
- Nolan Bushnell, founder of Atari: What everybody wanted was a party and some beer and some pizza, and they ended up going home with each other.
- @Grady_Booch: Ada Lovelace devised the first program. Grace Hopper wrote the first complier. Margaret Hamilton started the field of software engineering. Women have always been and will always be essential to the advance of computing.
- Hossein Fateh: The largest deal of 2001 was 3.5 megawatts. That same company leased 35 megawatts from us in 2016. The decimal place moved by a column. The next decimal place will move in 2022. Deals will be 350 megawatts.
- Matt Alderman: Based on our estimates, AWS Fargate deployments should save you 5 percent to 10 percent in your compute bill as compared to highly optimized AWS ECS or EKS deployments.
- Memory Guy: Conventional wisdom holds that SSDs will someday displace all HDDs, but in reality SSDs are proving to be more of a challenge to the DRAM market than to the HDD market...So, if you have a fixed budget, SSDs can help you get the most out of your system and are a better alternative than additional DRAM.
- @JoeEmison: Given this context, it is insane to say that something like AWS AppSync is bad lock-in. If I want AppSync functionality, I have two choices: use AppSync, or write AppSync myself. Given those, how is using AppSync until it makes sense for me to write my own a bad move?
- Ben Einstein: Despite all the analyst reports, market speculation, and journalists poring over the Sonos S-1 filing, I always find more truth about a company’s future buried in the plastic and the electronics that make up the products themselves. Hidden in plain sight is the roadmap for how this battle for consumers’ homes is likely to play out.
- Stuart Clubb: The only thing you might do is buy a CPU with a whole bunch of accelerators. But nobody has really figured out the right answer. Ford and GM have said they want the entire self driving subsystem to be 100 watts or less, and right now the demonstrators are the equivalent of driving around with 100 laptops on in the back of your trunk. So there’s a long way to go, and the solution isn’t going to be a whole bunch of GPUs. Somebody will crack a solution either for a generic solution, or very specific bespoke things that have some updatability. This is why we’re starting to see actually a resurgence in the embedded FPGA side of things
-
magsafe: One thing I didn't see mentioned in this article is Firebase. It feels like a hidden gem lurking within the overall GCP offering, and may be overlooked by devs who're not doing mobile-specific work. For me, Firebase was the gateway drug that got me into GCP.
- Alexander Rubin: Stored routines and trigger events are parsed when they are executed. Even “dead” code that will never run can significantly affect the performance of bulk operations (e.g. when running this inside the trigger). That also means that disabling a trigger by setting a “flag” (e.g. if @trigger_disable = 0 then ... ) can still affect performance of bulk operations.
- Hillel Wayne: That’s what makes Bob’s advice so toxic. By being so dismissive of everything but unit tests, he’s actively discouraging us from using our whole range of techniques. He demands we run blind and blames us for tripping.
- partiallypro: Perhaps this is separate, but Azure has a bit of a latency problem on their App Service Plans and the storage. I know that it has something to do with how they are able to offer instant scaling up, down and out. And the ability to move an app slot to another service plan instantly. However it does have some major performance issues, it's also very slow to unzip items
- flatlander_: The crazy thing about GCP is that some of the cloud products are so awesome that they make you think twice before leaving the platform. The article doesn't really mention BigQuery, which is basically a silver bullet for most of your run of the mill data processing needs. Our experience using GKE has also been amazing -- it's made us super productive, to the point that we've not needed to hire as much as we expected in infrastructure roles.
- Radia Perlman: Algorhyme — I think that I shall never see A graph more lovely than a tree. A tree whose crucial property Is loop-free connectivity. A tree that must be sure to span So packets can reach every LAN. First, the root must be selected. By ID, it is elected. Least-cost paths from root are traced. In the tree, these paths are placed. A mesh is made by folks like me, Then bridges find a spanning tree.
- insensible: One of my favorite career moments was the time I tossed up a Varnish instance in a different data center than the site it cached, then used grace mode plus DNS Made Easy's failover to get a significant degree of georedundancy. There have been multiple outages that nobody noticed, some of them hours long. Usually the backend is the one to fail, so more than 90% of end user page loads are straight from RAM nearly all the time. And it costs $20/month or so.
- Morgan Jaffit: Steam is unlike any other store currently on the market, and navigating these waters can be hard for developers. If you built a business on Steam in the Curation + early Greenlight eras it’s entirely possible you learned to make games for Valve staff and for Insiders — and not games for the actual Steam audience. That can kill you in the current market. Make games for the Steam audience, however, and Steam will apply the Rocket Fuel to propel your game in front of the eyes of millions.
- Quirky: The benefits of isolation can also apply at the team level. Ideas compete for acceptance in firms, and if exposed to competition too early may be killed off before they have had time to develop. An idea that initially seems a bit better than others can sweep through an organization, killing off competing ones that could ultimately be better with some development. The result can be a “monoculture” where there is too little variety left in an organization to generate new solutions.
- hmpc: The industry will need to solve this issue long before 5G is widespread. The solution will likely involve DSRC, C-V2X, or LTE-V/LTE Direct, which are tailored for the vehicular communication use case (involving both vehicle-to-vehicle [V2V] and vehicle-to-infrastructure [V2I]). It's unlikely a single technology will be able to handle all the challenges of a V2X scenario (highly mobile nodes, congestion, low SNR, requirements for sub-millisecond connection times), and so a second connection management layer will have to be built on top of multiple existing PHYs to enable simultaneous low-latency, high-throughput, and secure communications.
- ebikelaw: I worked on a system where the company did not really want a reimplementation but they destaffed a project in one site and reconstituted it with all new people at another site. The new people decided to rewrite from scratch. A year and a half later I start getting questions by email from the new people, questions indicating that not only do they not understand the implementation of the legacy system, they also do not clearly understand the business requirements that resulted in that implementation. Meanwhile, the maintenance of the old system had been neglected to such an extent it had fallen behind critical company-wide mandates. This was more of a lesson about why you shouldn’t destaff a project over some petty geographical squabbles, but also quite clearly about why you should always incrementally reimplement software rather that rewriting it.
- slivym: As an engineer in a large company this seems very similar to management structure. Every 6-12 months there's a re-organisation to split the business into vertically aligned business units, and then to horizontally aligned capabilities. Then back again. It's always fun to watch. In reality this process has absolutely nothing to do with the structure of the organisation. It's true purpose is to shuffle out people who are in positions where they're performing poorly, and move in new people. It just provides cover (It's not your fault, it's an organisational change).
- Joey Clover: Once the monolith becomes hard to maintain or extend, start to consider breaking apart your business domains and discover what services your business might need such as payment-service , booking-service , auth-service and such. If your microservices are becoming difficult to maintain or the resource allocations are becoming too complex, consider breaking apart your service into functions such as register-user , authenticate-user , check-acl-permissions and such. You get a lot more flexibility.
- cwinter: The constraining factor in this case is CPU throughput. The CPU cannot execute instructions fast enough to keep up with the data being read in from memory. Of course you are right that this is not the whole picture, it is possible to be bottlenecked on neither memory bandwidth nor CPU throughput. With respect to memory, two additional considerations are read amplification and latency. Read amplification: Read amplification basically means that you are reading data but not actually using it.
- What's coming? 7nm Design Challenges. There will be no simple 7nm chips. 100 billion logic and memory transistors in 7nm. The capacity to design and build such a monster is the primary challenge. Cost per transistor won't get better. So you need to add value with more transistors, you can't just rely on the chip being cheaper. It could take almost a year to make a 7nm device. Big markets that allow for expensive parts will drive 7nm adoption. These include: datacenter, AI chips, autonomous vehicles, mobile. If you move to 7nm it's because you want very high performance data processing, high bandwidth data in and out, and movement and processing on the processor itself. Processing needs to move to the edge because with 5g there won't be enough processing power to aggregate communication back to the cloud. Processing will need to be in the security camera, mobile phones, cars, etc. Not all data needs to be shipped back, but the important data needs to be shipped back, maybe not in real-time. Since autonomous vehicles will be used almost 24 hour a day, that puts more pressure on the data feeds into the processor. These chips are going to be so complex and difficult to build, it may not make sense to build full systems on a chip (SoC) anymore. It may disaggregate chips again and look more like we had in the 80s and 90s where we had a super high performance chip and a board of support elements. Trend will accelerate at 5nm. We're seeing a generational change moving from DDR4 to HVM2, attached memories, DDR5, and DDR6. Once we make this change it will last a couple of years.
- Jeff Atwood on cutting their AWS bill down for hosting Discourse. They started at about $3000/month and got it down to $1,000/month.
- Jeff: The main piece of advice I have is … don’t do it. Don’t take on a complex, “enterprisey” cloud install unless you have to. It’s extremely expensive for what you get. Compare to a simple monolithic Digital Ocean droplet running our standard Docker image, which can get you a very long way even at the $40 and $80 per month price points.
- Sam Saffron: Overall, we have been very happy with our AWS experience, but it is certainly a bit pricey compared to our bare metal setup. We also squeeze a tiny bit more performance out of our bare meta setup than AWS, but we are not talking 2x difference, more like 5-30% difference on the server side. The bottom line is that $10-$80 is perfectly fine for an unmonitored monolithic setup. But once you need to start talking SLAs and need to know this thing will be rock solid and survive random failures… well costs start mounting.
- There's a shocking number of services in the serverless space. Exploring the Ecosystem of Serverless Technologies.
- Broad Band: Radia’s manager at the time tasked her to “invent a magic box” that would fix Ethernet’s limitations without taking up an additional iota of memory, no matter how large the network was. He issued this decree on a Friday, right before he was to leave on a weeklong vacation. “He thought that was going to be hard,” Radia says. That very night, Radia woke up with a start and a solution. “I realized, oh wow—it’s trivial,” she says. “I know exactly how to do it, and I can prove that it works.” Like all the best innovations, it was simple. The packets couldn’t all travel on the same path without stepping on one another, so there had to be unique paths between every computer in the network. These paths couldn’t loop—no doubling back on the journey from point A to point B. Radia’s algorithm automatically created routes for each packet based on a spanning tree, a kind of mathematical graph that connects points to one another with no redundancies. Not only did it solve the Ethernet problem but it was also infinitely scalable and self-healing: if one computer in the network goes down, as computers are wont to do, the spanning-tree protocol automatically determines a new route for the packet. This is Radia’s signature touch. She designs systems that run with minimal intervention, through self-configuring and self-stabilizing behavior. This approach makes a large computer network like the Internet possible. As she said in 2014, “Without me, if you just blew on the Internet, it would fall over and die.” Radia took the rest of the weekend off after inventing the spanning-tree protocol. She wrote up the specifications on Monday and Tuesday.
- Great diagram. Web Architecture 101. A bit dated for the cloud era, but all the ideas are there.
- While there's a lot of interesting details in Building the Google Photos Web UI, you might be interested in how to fake making the UI feel faster than it really is: YouTube had no way of actually measuring the progress, so they just animated it at the speed most pages took, and then it sort of “hangs” towards the end until the page actually does load; we preemptively load content that we think you are about to look at; stay a page ahead so the thumbnails have loaded by the time you scroll; load extremely small placeholders for as many as 4 or 5 full screens in the future, and replacing them once they get closer to the viewport; For a very small increase in extra network traffic we can give the user a much better experience, a grid that always feels full, and always provides visual context; instead of flooding the network with a request for 100 photo thumbnails, we batch them into 10 or so at a time, so if the user suddenly starts scrolling again we don’t end up with 90 photos we loaded but didn’t use; we always prioritize loading the visible thumbnails over the off-screen ones; To make scrolling feel more natural we put a texture in the unloaded sections.
- Looks like FDP or Fine Driven Programming will be a thing. Google may have to make major changes to Android in response to a forthcoming fine in Europe.
- Google Cloud Platform - The Good, Bad, and Ugly (It's Mostly Good). Really gives you a good feel about how GCP works in comparison to AWS at a practical level. Conclusion: Google Cloud has created a compelling offering, with a mix of rock-solid infrastructure, plus unique value-added products like Spanner, Pub/Sub, and Global Load Balancing. They’ve been able to learn from what AWS got right and wrong. Their products integrate well together and are simple to understand. The downside to Google’s more deliberate approach is that it can sometimes feel like AWS is not just ahead of GCP, but accelerating away.
- It's pretty much always been that way, only the pipes and fittings change. The Bulk of Software Engineering in 2018 is Just Plumbing.
- Segment said Goodbye Microservices: From 100s of problem children to 1 superstar. While others are doing the exact opposite, they're ditching microservices and queues: consolidate the now over 140 services into a single service. The overhead from managing all of these services was a huge tax on our team. We were literally losing sleep over it since it was common for the on-call engineer to get paged to deal with load spikes...Given that there would only be one service, it made sense to move all the destination code into one repo, which meant merging all the different dependencies and tests into a single repo...We no longer had to deploy 140+ services for a change to one of the shared libraries. One engineer can deploy the service in a matter of minutes...The proof was in the improved velocity. In 2016, when our microservice architecture was still in place, we made 32 improvements to our shared libraries. Just this year we’ve made 46 improvements. We’ve made more improvements to our libraries in the past 6 months than in all of 2016. There are downsides: Fault isolation is difficult; In-memory caching is less effective; Updating the version of a dependency may break multiple destinations.
- Sensible. 5 Red Flags Signaling Your Rebuild Will Fail: No clear executive vision for the value of a rebuild; You’re going for the big cutover rewrite; The rebuild has slower feature velocity than the legacy system; You aren’t working with people who were experts in the old system; You’re planning to remove features because they’re hard.
- Walt Disney has made cloud and mona island data sets available.
- It's not always easy as a dismissive tweet. BBC News on HTTPS: we compared the page load performance of real users across HTTP and HTTPS, which revealed that many of those on HTTPS received a slower experience, due to the relatively large number of domains our assets are served from and the overhead of negotiating multiple TLS connections...Many of the bugs mentioned above fall into the class of ‘mixed content’, where the browser detects non-HTTPS assets being loaded on an otherwise secure page. This is a particular challenge for BBC News due to the site’s long and complex history. Also, Here's Why Your Static Website Needs HTTPS.
- We've seen someone going from microservices back to a monolith. Goodreads is going the other way. How Goodreads offloads Amazon DynamoDB tables to Amazon S3 and queries them using Amazon Athena: we show you how to export data from a DynamoDB table, convert it into a more efficient format with AWS Glue, and query the data with Athena. This approach gives you a way to pull insights from your data stored in DynamoDB. Also, Migrating a 100K requests-per-minute production from AWS Elastic Beanstalk to ECS and AWS Migration: A Depop story.
- Lambda is moving fast. Jeremy Daly has 15 Key Takeaways from the Serverless Talk at AWS Startup Day: a change in the 95th percentile of response rates from 3 seconds to 2.1 seconds when increasing memory by 50%; for just $0.00001 more, you can save 10.25698 seconds in execution time; only use a VPC if you need to connect to VPC resources; Functions with more than 1.8GB of memory are multi core; Don’t create unnecessary communication layers. Also, Case studies of AWS serverless apps in production.
- Experience report of running serverless in production for over a year. Serverless at Comic Relief. 40 different functions, invoked millions of times, costing no more than a couple hundred dollars. Comic Relief runs big fundraising events. They liked their containers and microservices architecture, but spent a lot of time making it handle traffic peaks. Functions provide a platform that does not require preparing for traffic spikes or worrying about unused infrastructure. Time can be spent building logical components that execute business logic and not worrying much about infrastructure nor scaling. Since invoking makes you pay for execution time, rather than for running the underlying infrastructure, you have an incentive to keep things performant and simple. Here's the pattern they use for all serverless services: A node module for each functional component or service. We really like Javascript, but are looking at Go as well, simply because it runs faster and thus will save us money; A set of functions that map to functional parts of our node module; The incredible serverless framework; Concourse CI to deploy functions to a staging environment, run tests and follow up with a production deployment; If we need to handle persistent data (we prefer queues where possible to decouple and remove direct dependency on a database layer), we rely on Elastic Search or DynamoDB, both managed services provided by AWS.
- The problem is people no more agree on what is simple than they agree on what is good or what is beautiful. Simple, correct, fast: in that order.
- Professor Brian Kernighan explains where Where GREP Came From. I had no idea Ken Thompson built grep in a day using ed. One of the commands in ed is 'g' for global, which I did know. 'p' stands for print. So grep is g/re/p where the 're' is regular expression. Grep, on every line that matches the regular expression, applies an ed command. That's the genius of Ken Thompson. A beautiful program, written in no time at all using another program, with a great name.
- Have APIs gone the way of free love, each according to their need, and cable TV? It's the End of the API Economy As We Know It: The promise of the API economy propelled the technology into the forefront of today’s digital marketplace. But, some of its promises have been short lived. Between the rate of unannounced changes, unreliable performance, unpredictable business policies, and knee jerk political reactions, you can make a good argument that the API economy as we once knew it has ended.
- Scaling Microservices with Message Queues, Spring Boot and Kubernetes. Some cool diagrams and lots of config files and code. The idea is to decouple the front-end and the backend with a queue using a container orchestrator such as Kubernetes to deploy and scale applications automatically. How? The title says it all.
- 'Chaos' was bold, interesting, different. It reeked of rebellion. 'Resilience' is so square man. Chaos — Engineered or Otherwise — Is Not Enough: But there’s one thing that continues to give people pause about about Chaos Engineering: the name...That’s why I read with much interest Netflix’s recent decision to rename its Chaos Engineering team: it’s now the Resilience Engineering team. Also, books on resilience engineering.
- How does eBay scale to handle millions of events with the resiliency to recover from failures as quickly and reliably as possible? Event Sourcing: Connecting the Dots for a Better Future (Part 1). The basic idea is when you record every event instead of updating state in place you have perfect infinite forward and backward flexibility. So now you don't have to watch Memento.
- traildb/traildb:an efficient tool for storing and querying series of events. This repository contains the core C library and the tdb command line tool.
- cswinter/LocustDB (article): Massively parallel, high performance analytics database that will rapidly devour all of your data. An experimental analytics database aiming to set a new standard for query performance on commodity hardware.
- cloudevents/spec: a specification for describing event data in a common way. CloudEvents seeks to ease event declaration and delivery across services, platforms and beyond. The lack of a common way of describing events means developers must constantly re-learn how to receive events. This also limits the potential for libraries, tooling and infrastructure to aide the delivery of event data across environments, like SDKs, event routers or tracing systems. The portability and productivity we can achieve from event data is hindered overall.
- Breakthrough” algorithm exponentially faster than any previous one: Singer and his colleague asked: what if, instead of taking hundreds or thousands of small steps to reach a solution, an algorithm could take just a few leaps? “This algorithm and general approach allows us to dramatically speed up computation for an enormously large class of problems across many different fields, including computer vision, information retrieval, network analysis, computational biology, auction design, and many others,” said Singer. “We can now perform computations in just a few seconds that would have previously taken weeks or months.”



