Stuff The Internet Says On Scalability For February 1st, 2019

Wake up! It's HighScalability time:
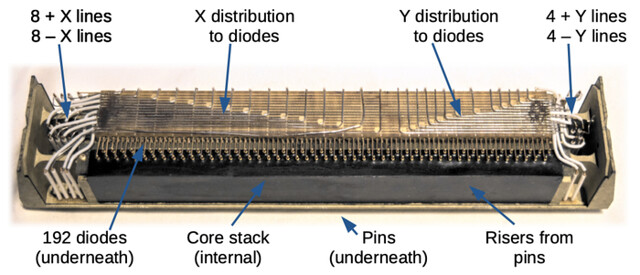
Memory module for the Apollo Guidance Computer (Mike Stewart). The AGC weighed 70 pounds and had 2048 words of RAM in erasable core memory and 36,864 words of ROM in core rope memory. It flew to the moon.
Do you like this sort of Stuff? Please go to Patreon and do what comes natural. Need cloud? Stand under Explain the Cloud Like I'm 10 (35 nearly 5 star reviews).
- $10.9B: Apple's Q1 services revenue; 5 million: homes on Airbnb; 2.5-5%: base64 gzipped files close to original; 60MB/s: Dropbox per Kafka broker throughput limit; 12%: Microsoft's increased revenues; 9: new datasets; 900 million: installed iPhones; $5.7B: 2018 game investment; way down: chip growth;
- Quotable Quotes:
- Daniel Lemire: Most importantly, I claim that most people do not care whether they work on important problems or not. My experience is that more than half of researchers are not even trying to produce something useful. They are trying to publish, to get jobs and promotions, to secure grants and so forth, but advancing science is a secondary concern.
- @da_667: The moral of the story here is that the cloud is NOT revolutionary. There are TRADEOFFS YOU HAVE TO CONSIDER. Glacier is cheap because it isn't "always ready" storage. and if/when you REALLY need the data, you're gonna be waiting a long time.
- @ludovicc: We spent many years to remove stored procedures and put business logic in an application server, why do you want to go back to that? Nice idea for fast prototyping though.
- Robert Graham: The most important rule of cybersecurity is that it depends upon the risks/costs. That means if what you want to do is write down the procedures for operating a garden pump, including the passwords, then that's fine. This is because there's not much danger of hackers exploiting this. On the other hand, if the question is passwords for the association's bank account, then DON'T DO THIS.
- @rbranson: We use SQLite mounted on a shared volume in WAL mode, which uses a shared memory segment. Works great.
- m1rrari: I then requested to work on other things, like our external facing web apps. Instead I got pigeon holed into primarily working on billing because I knew it the best. Bit it was soooo boring because it was all a solved problem in my mind. Rarely would we implement novel features. 99% of the time it is updating some obscure business logic and months of testing.
- Prime Minister Shinzo Abe of Japan: I would like Osaka G20 to be long remembered as the summit that started worldwide data governance. We must, on one hand, be able to put our personal data and data embodying intellectual property, national security intelligence, and so on, under careful protection, while on the other hand, we must enable the free flow of medical, industrial, traffic and other most useful, non-personal, anonymous data to see no borders, repeat, no borders
- "Facebook engineer": Morale is super high. We are paid a ton. Looking forward to my yearly bonus of $100k. F*ck ethics. Money is everything.
- ISABELLE HIERHOLTZ: There has been a gradual decline in overall AR/VR deal volumes in the last 2 years, with the most recent high well over 100 deals in Q4 2017. The stages which have seen the most variance are pre-seed and seed deals. Q4 2018 saw an uptick to approach 80 deals, although again pre-seed was somewhat limited.
- Scott Ford: Just as retailers wouldn’t sell unsafe toys, tainted lettuce or products with toxic chemicals, they have a responsibility to sell safe and secure IoT devices to consumers
- Ory Segal: Bottom line - here is yet another very important reason to go serverless, Let someone else be responsible for the majority of mundane security tasks, and stay focused on developing and securing your core business logic.
- @KentonVarda: TIL: A @GoogleCloud zone can spontaneously "run out of resources" meaning your VMs can't start up anymore. This is apparently not considered an outage because you were supposed to be multi-homed, dummy.
- @silvexis: Hypothesis: 80% of all AWS Serverless function workloads could run in a flavor of Lambda that has no visible network stack with only the ability to call AWS API’s via a an embedded SDK. Why not do this? Could have huge performance, security and design implications
- @dhh: The web isn’t just another software platform. It’s the greatest software platform the world has ever seen. No permissions, no masters, readable source code. Let’s protect the heritage, work in its service, and remind ourselves just what a marvel it all really is
- Jack Nicas: The screw shortage was one of several problems that postponed sales of the computer for months, the people who worked on the project said. By the time the computer was ready for mass production, Apple had ordered screws from China.
- Balgair: One thing to keep in mind is that for each 9 of uptime you have, add about two Zeros to the budget and increase the timeline by one time units up and then double it. So if 99% costs you $100 and a day of timeline on the project, then 99.9% will cost you $10,000 and two weeks of timeline, and 99.99% will cost you $1,000,000 and 4 months of timeline, and 99.999% will cost you $100,000,000 and 8 years of timeline, etc.
- Adam Fisher: Pixar limped along for almost a decade while Catmull and Smith waited for the inexorable advance of computer power to catch up with their movie-making ambitions. The evitable result: Toy Story—which, like the prior era’s Pong, marks the emergence of a new American art form.
- Ted Kaminski: if you think a data representation might need to change, then don’t leak it into a system boundary. There are “easier to change” and “harder to change” designs but this just brings us to “impossible to fix.”
- Shaun Nichols: AWS revenues were $7.43bn on the quarter, up 46 per cent year-on-year, while operating income for the cloud biz was $2.2bn, up 63 per cent. This time last year, sales were $5.1bn and operating income was $1.35bn. That's a 29.6 per cent margin versus 26.5 per cent.
- @FakeRyanGosling: Adventures in AWS autoscaling: I've seen multiple users get unexpected results when manually changing the desired size of a server group that happens to have scaling policies in place. The scaling policies can kick in at any time and lead to... surprises... say you change desired from 25 to 50, you may get 25 new instances as a result, only to have the autoscaler set it back to 25. Depending on your termination policy (say OldestInstance) your 25 up instances could get killed, leaving you with 25 starting (ie unhealthy) instances
- @pbailis: Research shows the final few percentage points of model accuracy can require orders of magnitude more training data than the first 95%. What can we do with models that aren't as accurate but are cheap to train?
- Geroff Huston: it appears that the process of exhausting the remaining pools of unallocated IPv4 addresses is proving to be as protracted as the process of the transition to IPv6. The allocation of 14.5 million addresses in 2018 on top of a base of 3.65 billion addresses that are already allocated at the start of the year represents a growth rate of 0.5% for the year for the total allocated IPv4 public address pool. This is less that one tenth of the growth rate in 2010 (the last full year before the onset of IPv4 address exhaustion).
- @nathangloverAUS: Made use of #Lambda Layers to create a watermark pipeline for my 250+ videos. Turned what was a 2+ day job into 15minutes of parallel compute. Huge thanks to @gojkoadzic for his ffmpeg lambda layer examples!
- ForHackernews~ According to recent discussion (and more importantly, Google's investors) are waking up the fact that they're a mature company in a mature market, and they are trying to cut costs across the organization.
- foobiekr: There are a ton of real-world systems that actually do deferred settlement and reconciliation at their distributed edge - for example, in reality ATMs work this way (and credit cards, in a way). These systems should actually be thought of as sources feeding into a distributed log of transactions which are then atomically transacted in a more traditional data store after reconciliation. In systems like this, you must have a well defined system for handling late arrivals, dealing with conflicts, often you need some kind of anti-entropy scheme for correctness station keeping (which people should think about anyway and must people ignore), and so on. These systems are hard to reason about and have many many challenges and many of them that I have personally seen actually are impossible to make robustly secure
- Will Hamill: The [Cloudflare] cost difference in focusing on very precise billing is attractive, but I don’t think that for many people this yet would be enough to drive them from any of the other platforms - it feels like splitting hairs on a handful of dollars per month vs a smaller handful of dollars per month, compared to self-managed virtual infrastructure at many times this amount. However, as the idea of financial accounting objectives for function development grows this may start to become more of a big deal, and I imagine that this will in turn pressure other providers to move to a similar very precise billing model.
- @mfdii: OH: "We use Stubernetes" "Is that a ultra stable fork of Kubernetes?" "No, we have a guy named Stu that scripts everything"
- Tencent: We chose Flink as the execution engine because of its excellent performance and powerful programming interfaces. Prior to that, our real-time applications were running on a real-time computing platform based on Apache Storm.
- Greg Ferro: "So my company went SD-WAN. Over 100+ sites. We totally did a non-renew on our L3VPN service with our provider, a Tier 1 Carrier, and went with a much smaller broker to get all residential grade broadband (cable and dsl) at our branches. It took a little under a year to complete this enormous undertaking (nearly every branch needed buildout to get coax.) We are now running on Silverpeak with broadband connections and some LTE sprinkled in. In the short term, it’s been awesome. "
- Volk: In a nutshell, NAND storage scales in a linear manner, while storage requirements for AI/ML are just at the beginning of an exponential growth period, fueled by AI/ML technologies becoming more and more available to mainstream users
- Kukushkin~ When you dig into molecules, and the states of ion channels, enzymes, transcription programs, cells, synapses, and whole networks of neurons, you come to realize that there is no one place in the brain where memories are stored. This is because of a property called plasticity, the feature of neurons that memorize. The memory is the system itself.
- @superwuster: I am really fascinated by the fact that a computer with 1000x faster processor and 100x more memory than 20 years ago can still feel slower, because of ads, bloatware, lazy programming -- it seems to capture the strengths and weaknesses of humanity in a nutshell
- Macian: It has been through the emergence of the AI market and AI architectures that the idea of near-memory computing or in-memory computing has found its revival. Once the idea was back on the table, people started looking at ways to use that same concept for things like RISC-V processors. Obviously, all processors have memories, and it has long been very important to select the right memories to obtain a good implementation of the processor in any die. We now have processor developers asking for memory that would perform some operation on the addresses before actually retrieving the data from the memory proper in order to simplify the circuitry around the memory. We are talking here about doing huge amounts of computation in the memory or near the memory, but with key elements, key operations that simplify greatly the logic around it.
- After bringing networks together with the invention of TCP/IP, what do you do for an encore? Vinton Gray Cerf worked on bringing planets together by creating An Interplanetary Internet. TCP doesn't work for an interplanetary internet. TCP flow control assumes hundreds of millisecond response times. It's a 40 minute round trip to Mars. Another problem is planets rotate so they move away while you're talking to them. And DNS lookups don't work either. It takes 7-40 minutes to get a response back, you could have moved by then and the answer is no longer valid. An interplanetary internet must deal with variable delay and disrupted communications. You need to use DTN or delay and disruption tolerant protocols. These are called bundle protocols. The first routing step is to figure out what planet you're going to and then route within the planet. So it's a delayed binding. And rather than dropping traffic when there's no route as TCP does you hang on to data until the link from Mars to Jupiter is back up. Because of celestial motion you know the connectivity is predictably unpredictable. You can build a contact graph based on celestial mechanics of when a connection is likely to be up again. A bundle protocol stores data. Another difference between bundle protocol and IP protocols is ping doesn't work because there's no well defined round trip time. Network management has to be rethought. You can send commands, but you don't know when the response will come back. Strong authentication and cryptology are built-in to protect against someone taking over the network. Much more security is built into bundle protocols than TCP. Bundle protocols have been thoroughly tested. They were used on the International Space Station for non-critical communication. They were also used on IIS for robotic control. A happy result is bundle protocols don't only work between planets, they're fast enough and with have low enough latency for real-time control. Deep space links at best get megabits per second. A test was successful using orbiting space craft around the moon transmitted successfully at 600 mbps using an optical connection. A bundle protocol was also used to track reindeer by creating a store and forward network through radios on the reindeer.
- If you haven't made the conceptual move to HTTP/2 yet, you're in luck, HTTP/3 is here. Excellent history and explanation at HTTP/3: From root to tip: HTTP/3 is just a new HTTP syntax that works on IETF QUIC, a UDP-based multiplexed and secure transport.
- It’s Time to Move on from Two Phase Commit: What I am calling for is a deeper type of change in the way we architect distributed systems. I insist that systems should still be able to process multi-sharded transactions --- with all the ACID guarantees and what that entails --- such as atomicity and durability --- but with much simpler and faster commit protocols. It all comes down to a fundamental assumption that has been present in our systems for decades: a transaction may abort at any time and for any reason...If you look carefully at the two-phase commit protocol, you will see that this arbitrary potential to abort a transaction is the primary source of complexity and latency in the protocol...In my opinion we need to remove veto power from workers and architect systems in which the system does not have freedom to abort a transaction whenever it wants during its execution. Only logic within a transaction should be allowed to cause a transaction to abort...The performance problems of 2PC has been a major force behind the rise of non-ACID compliant systems that give up important guarantees in order to achieve better scalability, availability, and performance. 2PC is just too slow --- it increases the latency of all transactions
- Airbnb doesn't just want to rent houses, they want to be your end-to-end travel platform. How? They use AI to deliver insights to users so they can decide when to travel, where to go, and what to do. Contextualizing Airbnb by Building Knowledge Graph.
- We demonstrated how to leverage AresDB to ingest raw events happening in real-time within seconds and issue arbitrary user queries against the data right away to compute metrics in sub seconds. Introducing AresDB: Uber’s GPU-Powered Open Source, Real-time Analytics Engine. The most common problem that real-time analytics solves at Uber is how to compute time series aggregates, calculations that give us insight into the user experience so we can improve our services accordingly. We needed a unified, simplified, and optimized solution, and thought outside-of-the-box (or rather, inside the GPU) to reach a solution. At a high level, AresDB stores most of its data in host memory (RAM that is connected to CPUs), handling data ingestion using CPUs and data recovery via disks. At query time, AresDB transfers data from host memory to GPU memory for parallel processing on GPU. Unlike most relational database management systems (RDBMSs), there is no database or schema scope in AresDB. All tables belong to the same scope in the same AresDB cluster/instance, enabling users to refer to them directly. Users store their data as fact tables and dimension tables. With the current implementation, the user will need to use Ares Query Language (AQL), created by Uber to run queries against AresDB.
- Revenge is a dish best served with high hourly rates. Banks scramble to fix old systems as IT 'cowboys' ride into sunset: "One COBOL programmer, now in his 60s, said his bank laid him off in mid-2012 as it turned to younger, less expensive employees trained in new languages." COBOL isn't really the problem, it's just a language. What's the problem? MpVpRb: "The problem is complexity, undocumented complexity and lots of poorly understood connections and dependencies The problem is spaghetti code with lots and lots of special behaviors and edge cases The problem is that the old code wasn't the consistent work of one mind. It was years and years of hacks by programmers of varying skill levels, none of who knew exactly how the whole program worked." Will current cloud systems be any different than these old COBOL systems? No. All software is legacy software.
- 40x faster hash joiner with vectorized execution. "vectorized execution” is short hand for the batched, column-at-a-time data processing. vectorized execution improved the performance of CockroachDB’s hash join operator by 40x. The philosophy behind each vectorized operator is to permit no degrees of freedom, or run-time choices, during execution. This means that for any combination of tasks, data types, and properties, there should be a single, dedicated operator responsible for the work. running a series of simple for loops over a single column is extremely fast! The row-at-a-time Volcano model is, by contrast, extremely complex and unfriendly to CPUs, by virtue of the fact that it must essentially behave as a per-row, fully-type-general expression interpreter.
- Two Years of Elixir at Podium: We have over 110 Elixir repos. Of those, 11 are public libraries, a small handful are private libraries (usually to simplify communication between microservices), and the rest are all server applications, all written and managed by 80 (and growing!) engineers, split across 17 teams...Elixir’s functional programming style is what really makes it easy to jump into a codebase and make changes, even having never worked with the language before. In our experience, it is simply much easier to reason about...with Elixir, we can isolate responsibilities to different process supervisors and restart child processes if something goes wrong...Elixir has the best docs...Elixir’s core set of data structures are fantastic. However, if you’re coming from a JavaScript background, they take a little getting...Elixir helps to push you in the right direction, and makes it harder to make mistakes. A lot of languages are great, and I’m not saying Elixir is the best language for every circumstance, but for us, Elixir was an excellent choice.
- If you really want to achieve super low latency you must consider the whole ecosystem. That's the application, the network, the OS, the path. How do we get everyone to work together? To work across silos? Achieving super low latency for critical real world Internet applications. Latency ranges: 500ms - 1.5s: reaction time in auto accident investigations; 250ms: average human response time to visual test; 200ms: speech pause interval; 80ms: shortens skype sessions; 20ms: perceivable video delay (affects AR); 10ms: perceivable haptic delay impacts game bots (jitter); 5ms: cypesickness (AR); <5m: impacts M2M interactions. Lessons learned from an AI controlled slot car simulation: real world is messy, there's error all over the place, between the camera, controller and vehicle there's latency, there's application latency. Data doesn't like to be handled. Data has to be handled near the source not over the internet. Down sampling is key. Shrink the picture to reduce the amount of data. Matching who you're talking to with who you're looking at is difficult. An accident about to happen you have to know you're talking to that vehicle in a secure manner. When everything works computers are way better than humans, but when things don't work it's a disaster. How will we get to a low latency world? For Linux there's XDP (eXpress Data Path) and BPF (Berkely Packer Filter), IETF (mobile protocol, IPv6, L4S (Low Latency, Low Loss, Scalable Throughput Internet Service Architecture)), 3GPP (5G, MCORD). Divide problem into: Network Architecture, Protocols, Implementation, Ecosystem. Speed of light is a fundamental limit. That's 93 miles distance for 1msec RTT. Server and client must be close. Can't be go back to a datacenter. Need to minimize the number of hops to reduce latency and increase reliability. Handovers need to be fast. 0-RTT like TCP fast open. Control plane needs security and to deny DOS attacks. Attack of the killer microseconds - there's a blackhole in terms of latency in the network stack. The best optimization is to eliminate whole parts of a path. Consolidate. Squash the stack. Modularity is not a win.
- Not really simple, but as well written and as clear as such things can be. Building A "Simple" Distributed System - Formal Verification.
- Lessons learned scaling PostgreSQL database to 1.2bn records/month. Good use of startup credits to give different providers a try. They found problems with both Google and AWS, so they went self-hosted: "Now we are renting our own hardware and maintain the database. We have a lot better hardware than any of the cloud service providers could offer, point in time recovery (thanks to Barman) and no vendor lock-in, and (on paper) it is about 30% cheaper than hosting using Google Cloud or AWS. That 30% we can use to hire a freelance DBA to check in on the servers once a day." Some lessons: Using a combination of granular materialized views and materialized table columns we were able to enrich the database in real-time and use it for all our analytics queries without adding the complexity of a logical replicate for data-warehousing; If you are going to use database as a job queue, the table containing the jobs must be reasonable size and the query used to schedule the next job execution must not take more than couple of milliseconds; By moving the database to the same datacenter and reducing latency to <1ms, our job throughout increased 4x; Column order matters. We have tables with 60+ columns. Ordering columns to avoid padding saved 20%+ storage.
- ibrdtn/ibrdtn: This implementation of the bundle protocol RFC5050 is designed for embedded systems like the RouterBoard 532A or Ubiquiti RouterStation Pro and can be used as framework for DTN applications.
- uber/aresdb: a GPU-powered real-time analytics storage and query engine. It features low query latency, high data freshness and highly efficient in-memory and on disk storage management.
- StanfordNLP: is the combination of the software package used by the Stanford team in the CoNLL 2018 Shared Task on Universal Dependency Parsing, and the group’s official Python interface to the Stanford CoreNLP software. Aside from the functions it inherits from CoreNLP, it contains tools to convert a string of text to lists of sentences and words, generate base forms of those words, their parts of speech and morphological features, and a syntactic structure that is designed to be parallel among more than 70 languages.



