Stuff The Internet Says On Scalability For March 15th, 2019

Wake up! It's HighScalability time:
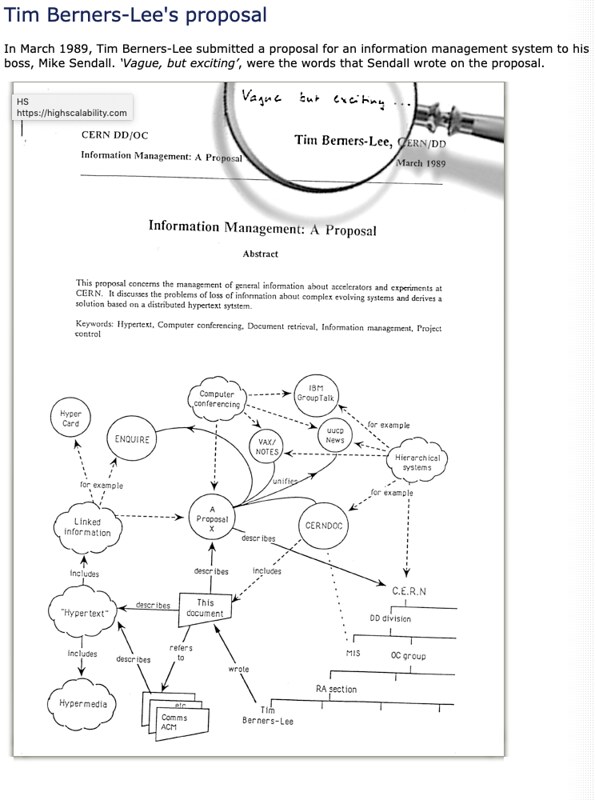
The web is 30! Some say it's not the web we wanted. But if we got that web, would it have ever grown so big? Worse usually is better.
Do you like this sort of Stuff? I'd greatly appreciate your support on Patreon. Know anyone who needs cloud? I wrote Explain the Cloud Like I'm 10 just for them. It has 40 mostly 5 star reviews. They'll learn a lot and love you even more.
- 300%: AWS IoT growth per year; 74%: mobile games user spending in the App store; 31.4 trillion: new record for calculating digits of pi (121 days); 112Gbps: Intel's SerDes; 100M: image and video dataset; 1.5 trillion suns: weight of the Milky Way; 300+: backdoored apps on GitHub; 10%: hacked self-driving cars needed to bring traffic to a halt; $3 million: Marriott data breach cost after insurance;
- Quoteable Quotes:
- @kelseyhightower: Platform in a box solutions that are attempting to turn Kubernetes into a PaaS are missing the "as a service" part. It's more like PaaR: Platform as a Responsibility. Your responsibility to purchase, staff, patch, scale, and upgrade.
- DHH: We’re stopping all major product development at Basecamp for the moment, and dedicating all our attention to fixing these single points of failure that the recent cloud outages have revealed. We’re also going to pull back from our big migration to the cloud for a while, until we’re able to comfortably commit to a multi-region, multi-provider setup that’s more resilient against these outages...We were using Google Cloud Storage, but given too many issues big and small over the year, we’ll be migrating to AWS S3 for storage going forward.
- Daniel Ek: after careful consideration, Spotify has filed a complaint against Apple with the European Commission (EC), the regulatory body responsible for keeping competition fair and nondiscriminatory. In recent years, Apple has introduced rules to the App Store that purposely limit choice and stifle innovation at the expense of the user experience—essentially acting as both a player and referee to deliberately disadvantage other app developers. After trying unsuccessfully to resolve the issues directly with Apple, we’re now requesting that the EC take action to ensure fair competition.
- @lizthegrey:"We used to have an illusion that we were in control and nothing was broken. But our systems are full of emergent behaviors and are broken all the time." --@mipsytipsy #ServerlessDaysBOS
- J. Paul Reed: A system under scrutiny is the 737Max’s Maneuvering Characteristics Augmentation System or MCAS; this is an automation system intended to keep the plane from stalling. One of the things it measures is the angle-of-attack: if the plane exceeds a particular flight angle, it will fall out of the sky. The MCAS, in the default configuration, uses a single sensor as input to measure this critical metric.
- John Hagel: There’s a third zoom in initiative that, in my experience, is typically the most challenging one. It requires us to identify what significant part of the business we are going to shut down or divest in the next 6-12 months in order to free up more resources to scale the edge and strengthen the core. Once again, the 80/20 rule can provide a very helpful lens here. What about the 80% of the products, customers or facilities that are only generating 20% of the profits of the business? Why are we still in these parts of the business?
- Ian Cutress: I was quite surprised to hear that due to managed risk, we’re unlikely to see much demand for [SSD] drives over 16TB. One message starting to come through is that storage deployments are looking at managing risk with drive size – sure, a large capacity drive allows for high-density, but in a drive failure of a large drive means a lot of data is going to be lost.
- Shoshana Zuboff: A detailed analysis of Nest’s policies by two University of London scholars concluded that were one to enter into the Nest ecosystem of connected devices and apps, each with their own equally burdensome and audacious terms, the purchase of a single home thermostat would entail the need to review nearly a thousand so-called contracts.
- @drewharwell: The New Zealand massacre was livestreamed on Facebook, announced on 8chan, reposted on YouTube, commentated about on Reddit, and mirrored around the world before the tech companies could even react.
- Geoff Huston: The overall picture of security in the Internet is pretty woeful. The path between recognising a URL on a screen and clicking on it and believing that the presented result is actually the genuine article requires a fair amount of blind trust. We are trusting that the DNS mapping of the name to an IP address is genuine, trusting that the routing system is passing the IP packets to the ‘correct’ endpoint, trusting that the representation of the name on your screen is actually the name of the service you intended to go to, and trusting that the TLS connection is genuine, to name but a few.
- Tim Bray: There was a time when commercial chat services supported XMPP because it was felt to be the right thing to do. But that was old-school hippie thinking, because if chatterers can just go ahead and talk to anyone anywhere, then your service probably won’t go viral and how are you going to monetize?
- Sir Tim Berners-Lee: I broadly see three sources of dysfunction affecting today’s web: Deliberate, malicious intent, such as state-sponsored hacking and attacks, criminal behaviour, and online harassment. System design that creates perverse incentives where user value is sacrificed, such as ad-based revenue models that commercially reward clickbait and the viral spread of misinformation. Unintended negative consequences of benevolent design, such as the outraged and polarised tone and quality of online discourse.
- Jeremy HU: Given so many advantages, why I am switching back to C++? The most beautiful thing about Rust is also a disadvantage. When you implement an algorithm using C++, you can write it down without one second of pause, but you can’t do that in Rust. As the compiler will stop you from borrow checking or something unsafe again and again, you are being distracted constantly by focusing on the language itself instead of the problem you are solving.
- Alex Wauters: Track host Sam Newman mentioned serverless as the logical next step for cloud computing. Critics like Ben called Jeff Bezos the apex predator of capitalism and cited how wasteful functions are: main memory reference has a latency of about 100 ns. A round trip within the same datacenter: 500,000 ns.
- nemil: The early growth of MongoDB is a story that should be taught to every software developer. It’s an example of the periodic technical hype cycles that can lead to bad engineering decisions.
- @GregorMacdonald: 7/ Ask not: how much further in price will storage have to fall, to make it economic. But rather, how cheap does generation have to get to make building storage economic? Answer: we're here.
- Mantin Lu: App Annie believes hyper-casual games with simple gameplay will rapidly fuel downloads and user engagement in 2019. Spending by mobile game users is expected to dominate the revenue performance of the overall gaming industry, estimated to eventually account for 60% of the total. This estimate includes PC/Mac, Console, Handheld, and mobile devices in its analysis.
- @facebook: Yesterday, as a result of a server configuration change, many people had trouble accessing our apps and services. We've now resolved the issues and our systems are recovering.
- @google: On Monday 11 March 2019, Google SREs were alerted to a significant increase in storage resources for metadata used by the internal blob service. On Tuesday 12 March, to reduce resource usage, SREs made a configuration change which had a side effect of overloading a key part of the system for looking up the location of blob data. The increased load eventually lead to a cascading failure.
- @copyconstruct: To be clear, this approach might work when dealing with fewer than 5-7 services. Anything about the 5-7 mark becomes fiddly, once past the 10 services mark, it's somewhat painful. 100+ services spun up for local dev with k8s and Docker - you've got to be kidding me.
- @perbu: I think, on a purely technical level, the coolest thing I’ve seen this week is @KentonVarda presenting their FaaS arch using V8 Isolates. As opposed to the clunky stuff others use for FaaS this is just so efficient.
- @lizthegrey: Make serverless choices by having technology not be the point. You may be hired to deliver technology, but customers don't care about the tech. iRobot customers care about clean houses, not about visual navigation and mapping technology. #ServerlessDaysBOS
- @AGuilinger: You can go serverless today in anything. It's a direction not a destination. You can use tools that you only manage parts (i.e. kinesis you need to manage shards and sqs you don't) - get into the to of thinking you've done serverless #ServerlessDaysBOS
- Dustin Volz: The Navy and its industry partners are “under cyber siege” by Chinese hackers and others who have stolen tranches of national security secrets in recent years, exploiting critical weaknesses that threaten the U.S.’s standing as the world’s top military power, an internal Navy review has concluded.
- Brent Ozar: Forget the feature named “In-Memory OLTP” and just put the hardware in that the feature would require anyway. You’re going to have to do it sooner or later, so just start there. Before you go writing the necessary conflict detection code, trying to rip out your unsupported cross-database queries, messing around with hash index troubleshooting, or stressing out about their statistics problems, just buy the damn RAM.
- Zeynep Tufekci: there’s an enormous amount of centralization going on [in thw web], with a few big players becoming gatekeepers. Those few big players have built, basically, surveillance machines. It’s based on surveillance profiling us and then targeting us for ads — which wasn’t the original idea at all.
- lorddimwit: In the 1990s, I wrote code that generated HTML tables. In the 2000’s, I was told that we shouldn’t use tables, because that’s semantic markup, not presentational/layout markup, and we should use CSS. Getting things to just. freaking. work. was a Sisyphean effort and so we’d cheat and just use tables. In the 2010’s, we get CSS Grid. In the 2020’s, I fully expect web apps to just be GTK+/WinForms apps running inside a wasm application.
- scottlamb: You're probably imagining an async, thread-per-core model. One cache per thread might be reasonable then (although having more, smaller caches decreases hit rate, so might fail their requirement #5). Go programs are written in a synchronous, thread-per-request model. You'd end up with _tons_ of small, very cold caches and a miserable hit rate. You could approximate the former in Go by just having an array of N caches and picking from them randomly. This is similar to their "lock striping" with less contention (no stripe is a hot spot) but a lower hit rate.
- @rebeccaballhaus: A software fix to the Boeing 737 MAX was delayed for months as discussions between regulators and Boeing dragged on—and U.S. officials said the government shutdown halted work on the fix for five weeks.
- Gregor Hohpe: Architecture diagrams tend to show all the individual parts rather than illustrating the system’s key purpose. Inverting this not only produces more expressive diagrams, it also improves decision making
- @caseyf: Our datacenter is closing the location that we've been in for 13 years so we'll need a new home. How do little businesses afford the cloud? S3 is one thing but I did a *really* conservative estimate for moving computing to AWS & it came out to $175,000/year for EC2 + bandwidth. That's $175K a year for AWS compared to our current DIY costs of $58K a year max: 10 machines, replace 2 or 3 per year = $10000-$15000 colocation fees (cab, electricity, etc) = $13920 100 mbps burstable = $7800 1 gbps to Internet = $21000 and these prices aren't even that great
- @manisha72617183: My favourite quote when reading up on Frequentists and Bayesians: A Frequentist is a person whose long-run ambition is to be wrong 5% of the time. A Bayesian is one, who vaguely expecting a horse, and catching a glimpse of a donkey, strongly believes he's seen a mule.
- @BenLesh: I just realized in 21 years, I've never worked at a company where I saw an engineer get a promotion except Google. And at Google, you basically have to move a mountain to get one if you're senior. I think everywhere else people just find new jobs for promotions. 🤔
- @fchollet: Fascinating graph. Since 1990, computers, databases, and the internet should have dramatically cut the personnel cost of hospital administration. It has instead increased by 20-30x. The problem is structural, not technological, and I doubt AI will have any impact there.
- @rowlsmanthorpe: In the last 10 years, the 5 biggest tech firms have bought over 400 smaller companies Google has bought more than 150, swallowing one every 18 days Not one was stopped. 99% were never even investigated
- Lawrence Hecht: C-level executives often don’t have a clue when it comes to IT and application development. I’ve been analyzing survey data from IT end users for over 15 years, and responses received from business managers and even CIOs are often drastically different than what actual practitioners say.
- @dvassallo: I fought hard at AWS for 1 monolith per AWS service within my dept. We did that successfully in my ex-team, despite heavy pushback initially. 1 git repo, 1 build artifact, and the whole service runs from the IDE. In prod the same binary gets deployed to 1000s of machines, but ... with different runtime modes on different sets of hosts (frontend, backend, storage, etc). 1 deployment always deploys to all hosts, regardless of what changed. Only versions n & n-1 (during deploy) would ever be running in prod. Everyone on the team became a fan of this.
- @itamarst: This company built a tool to analyze git repos, and used it to analyze their own work during crunch time. Punch line: "the team became less effective per hour as they worked more hours compared to their normal pattern." Crunch time is an anti-pattern!
- @anshelsag: Guy, guys, guys. Operators will have to make SIGNIFICANT network upgrades to enable REAL 5G NR SA networks. @PatrickMoorhead and I wrote a paper on it. However, I do not believe that they need to raise their prices to accomplish this. I believe they are charging to limit users.
- @sarah_edo: Our interview processes are largely broken but a lot of companies aren't brave enough to actually fix them because people secretly like how elitist they are.
- Sanjana Varghese: But the real pressure came closer to the end. Built into y-cruncher are two base algorithms – one for the calculations of pi itself, and another for the verification. The verification algorithm runs alongside the calculation, but it only calculates one single digit of pi, and it takes a lot of time and resources. So you couldn’t use the verification program to calculate every single digit, because it would simply take even more time and storage. What it can do is prove that your results are correct. “The final multiplication is important, because if you miss one digit during those calculating processes, then the entire result is wrong,” says Iwao.
- JackSpyder: You're the first person i've seen on reddit who realises being cloud agnostic isn't necessarily about switching provider. Its usually about being in a strong negotiating position.
- @antirez: I don't think most of the Redis community is understanding what paradigm shift Redis Streams *as a data structure: log of hashes* are, because the feature is seen from the POV of streaming (Kafka (TM) style basically). However most of the value is as pure data structure. (also)
- Scobleizer: Niantic started by thinking about a game you play while walking or moving around the real world. Listening to Finman you hear that focus and core competency everywhere. They don’t want to just figure out what you are doing in your Living Room, they want to figure out the real world and how to apply that to making their World-Scale platform and games better.
- @adamhjk: Here is my summary of whats happening with Elastic and AWS. tl;dr - Tight Open Core makes for unsustainable community resources, AWS didn't have much choice, and Elastic doesn't either. Free Software is the only winner.
- @devoncestes: They said "Over the last [timeframe] we've found that using Elixir for [our new product] has been so beneficial to our business that we now consider our use of Elixir as a major competitive advantage that we don't want or competitors to have, so please keep this inquiry private."
- stingraycharles: You're missing the point of the author. It's not so much that Docker as a technology is bad; there's nothing wrong with it. The point is that Docker, the company, cannot monetize upon the technology, because the moment they start charging for their containerization technology, people will switch to an alternative container technology, especially now that Kubernetes has won the orchestration "wars" and made it so easy to switch the underlying technology.
- ChuckMcM: It has never been impossible to run a company by injecting money into it to cover the difference between how much customers 'value' the product versus what it costs to provide the product. But the dot com days showed that without a point in the business model where the value exceeds the cost by enough margin to keep the business going, such businesses don't survive. What neither Lyft, nor Uber, has yet provided is a credible 'size' at which they would be a going concern (covering all their costs), nor a really good idea of how being larger scales revenues more than costs in sufficient measure to become profitable.
- @jamonholmgren: Electron app memory usage: 150 MB Native app memory usage: 0 MB (because you never ship it)
- @simonbrown: Product owners likely won’t ask for “security” though, which is why software development teams need one or more people performing a technical leadership role, asking questions and ensuring relevant quality attributes are catered for. This is what software architecture is about.
- Kcufftrump: Are you insane? We make software for banks. If we're down an hour, they could potentially lose millions of dollars, not to mention customers, reputation, etc. No. We do not "test in production." Our systems and databases are cloned to VMs in tandem, renamed and tested there.
- HarwellDekatron: From personal experience writing and deploying micro services in a very large tech company, the biggest advantage of micro services comes from a scalability perspective, both it terms of computing and engineering resources. Mind you, those two advantages materialize if and only if you have very good infrastructure to share code across projects and to make deployment as easy as possible, otherwise you’ll spend tons of time doing devops and reinventing the wheel (say, implementing distributed locking) on every project. If you are Google or Netflix, you already have those problems solved. If you are a tiny startup with a single product, then over engineering just to be buzzword complaint might literally kill your business.
- c_o_r_b_a: Serverless. Cloud native. Functions-as-a-Serverless CI/CD Service. Web scale. Web scale. Cloud native! Web scale. Blitzscale. K8 Beckubesale.js. Gitlab continuous YAML orchestration image registry pipeline in a Docker container in a Kubernetes pod in a Docker container on a VM on a VM on a server inside another server, in a datacenter, on a boat, inside another boat.
-
@stevesi: 30/ The hardest thing for me about regulating tech is that actions always start from something a big company is doing strategically that seems wrong. The problem is these actions are almost always wrong for them as well, but you just can’t see it inside.
- @odrotbohm: Suggestion: remove the Kafka bit, replace with visualization of event based communication. Kafka itself is not the point. In fact, critical, centralized infrastructure is sort of an antithesis to independently operating services, isn’t it?
- Osh Agabi: Yes. Neurons process signals differently. Also, a neuron does not do a single computation. There is a common misconception that a neuron is equivalent to a transistor. No! A neuron is more equivalent to an FPGA chip...and I don't believe its a faster path, ...going out on a limb here... it's probably the only path. Some intelligence is possible with silicon as we can clearly see. I suspect intelligence built with structured data, in a virtual domain will have a hard time competing with intelligence built on sparse data in the real world with massive degrees of freedom.
- @AWSonAir: “AWS hosts nearly two times as many Windows Server instances in the cloud as Microsoft” - Adrian Cockcroft, VP Cloud Architecture Strategy at the #AWSSummit Tel Aviv
- Ken Ellis: For 100,000 users and an aggregate 1200 messages per second, this comes to $400/day [SQS + Lambda], or around $150k per year. That sort of capacity you could probably handle with 2 or 4 well designed mid-range EC2 servers using Nginx and Redis, and only be out $5k or $10k per year. So the operational costs are higher once you reach significant scale. You probably over-provision fixed servers to accommodate load, even with auto-scaling. Given the approximate 4x markup of Lambda functions over EC2 instances, if your servers are running at 25% load or less, you would probably save money going serverless. In this example, the economics of serverless are a bit more expensive due to the high call volume to the SQS API coupled with the relatively short 10 second long-polling timeout, making cost increases closer to a factor of 20. However, operational simplicity, time-to-market, and development costs can all make the choice favorable. The low upfront costs are also beneficial. The big bills don't come in until the product is successful, and once it's successful, it's easier to find the money.
- AWS really wants you to think they are good Open Source citizens. New – Open Distro for Elasticsearch && Keeping Open Source Open – Open Distro for Elasticsearch. Good thread on HN and on Twitter. Needless to say not all agree. @adrianco: What should we have done instead, that Elastic would have agreed to? We have customers to support. Jedd: I think Eben, rms, et al are 100% right when they observe that 'open source' hides the actual, important point -- even if the person you're talking to doesn't want to talk about freedom(s). You used the phrase 'open source' 9 times in your three paragraphs, but didn't mention 'free' or 'freedom'. (Hmm, the F in FOSS may count as one veiled instance.) Talking in terms of freedom for people to use free software however they want makes more sense than trying to dance through the forest of varyingly-free 'open source' licences. HillRat: Definitely creates a new risk model for hybrid OSS-Enterprise software: build something attractive enough for the big players to co-opt and they might just, ah, fork you up.
- There's now something called the Continuous Delivery Foundation (or CDF). Netflix is giving a housewarming gift: The CDF is a neutral organization that will grow and sustain an open continuous delivery ecosystem, much like the Cloud Native Computing Foundation (or CNCF) has done for the cloud native computing ecosystem. The initial set of projects to be donated to the CDF are Jenkins, Jenkins X, Spinnaker, and Tekton. Second, Netflix is joining as a founding member of the CDF. klebsiella_pneumonae: Spinnaker is amazing, but at our company it takes a team of 5 devs busy to keep it up and running. It is definitely meant for the enterprise.
- You're sticking your head in the ground if you can't see how ML at the edge is different in kind than decision making systems built in the past. Google's An All-Neural On-Device Speech Recognize: To improve the usefulness of speech recognition, we sought to avoid the latency and inherent unreliability of communication networks by hosting the new models directly on device. As such, our end-to-end approach does not need a search over a large decoder graph. Instead, decoding consists of a beam search through a single neural network. The RNN-T we trained offers the same accuracy as the traditional server-based models but is only 450MB, essentially making a smarter use of parameters and packing information more densely. However, even on today's smartphones, 450MB is a lot, and propagating signals through such a large network can be slow.
- [WePay] The Whys and Hows of Database Streaming: So by using change data capture with the write-ahead log, we get the best of all the worlds. We don't have to worry about implementing distributed transaction, but we get all of the transactional guarantees. And because we're asynchronously tailing this MySQL Binlog or some kind of a write-ahead log, we don't have to worry about impacting the performance when we're writing the data into the database because it's asynchronous...database as a stream of change event is a really natural and useful concept. It would make a lot of sense for every single database out there to be able to provide a CDC interface...log-centric architecture is at the heart of streaming data pipeline. It helps us solve a lot of problems when it comes to distributed transactions, and it's very simple to implement and understand...CDC for peer-to-peer databases is not trivial
- How are new cloud databases different than old style monolithic relational database stacks? Werner Vogels counts the ways. Amazon Aurora ascendant: How we designed a cloud-native relational database (let's take a moment and recognize the title alludes to one of the great TV shows of all time—Andromeda). We challenged the conventional ideas of caching and logging in a relational database, reinvented the database I/O layer, and reaped major scalability and resiliency benefits. Amazon Aurora is remarkably scalable and resilient, because it embraces the ideas of offloading redo logging, cell-based architecture, quorums, and fast database repairs. In Amazon Aurora, the log is the database. Database instances write redo log records to the distributed storage layer, and the storage takes care of constructing page images from log records on demand. At AWS, we engineer for failure, and we rely on cell-based architecture to combat issues before they happen. In fact, Aurora can tolerate the loss of an entire zone without losing data availability, and can recover rapidly from larger failures. Amazon Aurora uses quorums to combat the problems of component failures and performance degradation. With Aurora, our goal is Availability Zone+1: we want to be able to tolerate a loss of a zone plus one more failure without any data durability loss, and with a minimal impact on data availability. We use a 4/6 quorum to achieve this. For each logical log write, we issue six physical replica writes, and consider the write operation to be successful when four of those writes complete. With two replicas per zone, if an entire Availability Zone goes down, a write is still going to complete. If a zone goes down and an additional failure occurs, you can still achieve read quorum, and then quickly regain the ability to write by doing a fast repair. Amazon Aurora uses an entirely different approach to replication, based on sharding and scale-out architecture. An Aurora database volume is logically divided into 10-GiB logical units (protection groups), and each protection group is replicated six ways into physical units (segments). Individual segments are spread across a large distributed storage fleet. When a failure occurs and takes out a segment, the repair of a single protection group only requires moving ~10 GiB of data, which is done in seconds.
- Looking for ~2TB of cheap cloud rsync backup storage that is NOT, AWS, Google, Box or MS. Go! rsync.net, @backblaze, L0pht, Carinet, Stick a RPi and a 2-terabyte flash drive at a friend's house and run OwnDrive?, @linode, tarsnap.com, Digital Ocean Spaces, 1. Create free/low cost accounts at providers - an even # for mirroring. 2. Create VM disks, 1 per provider 3. Xigmanas boot from USB, encrypt all vm disks, make into ZFS vdevs, add pairs to create vmirror devs, add all mirrors to ZFS pool. Encrypted, redundant. striped, local.
- Ever been in a bar where an artist was live painting off in a corner? Programming in Rust: the good, the bad, the ugly: "I figured a good way to get to know the language was to solve all 189 problems from the “Cracking the Coding Interview” book. Not only would I solve them with Rust, but I decided to do it live on Twitch." The upshot from this performance artist is he likes Rust, but it's too verbose.
- You have serveless functions, now what? You need a coordination layer. You have options. Here's a comparison of Apache Airflow and AWS Step Functions. ETL (Extract, Transform, Load) in Insights. They went with Step Functions for a reason we'll keep seeing more of as the focus on delivering "business value" mantra penetrates ever deeper into the developer mindset: It is a tough decision. After considering all the various factors, we decided to go with AWS Step Function. Since it is a managed service, it frees up our engineering resources from maintaining the basic infrastructure of this platform and allows us to focus on building the data pipeline.
- This is a wisdom post, but before you adopt microservices you might want to read it more as a cautionary tale. Microservices after Two Years: Microservices are not mini-monoliths; they’re collaborators that operate independently when they need to; Microservices, on the other hand, require up-front planning before code is written, every time. Every new service or any change to a service may be able to be coupled with completely replacing that service. Anything that has the potential to change the contract in a system (whether with the user or other services), requires more understanding and up-front design than the same change in a monolith; The one crucial decision that a team must make is what is the domain context, is this I’m dealing with talked about differently depending on who I talk to, and what is the maintenance cost of each approach; If you use microservices, you need to allocate a sizable chunk of time to building the tooling necessary to allow people to develop against those services; Microservices deliver on the promises of Object-Oriented Programming; Contracts, Patterns, and Practices should be Code generated; You can’t punt on non-functional requirements; if you’re going to start writing microservices; I highly recommend going down the path of event-driven programming, state machines, and some sort of event stream; Choosing between REST and Events for supporting Microservices is tougher than you may think; Maintaining Microservices requires strong organizational and technical leadership; While developers and consultants tend to espouse microservices in a cloud scenario, they tend to ignore that microservices are orthogonal to their deployment scenario, and they’re orthogonal to technology stacks. Also, Give Me Back My Monolith. Also also, So you think monolith is the only alternative to microservices.
- How We Reduced Our Amazon Redshift Cost by 28%: So how do you optimize your Redshift spend while reducing the risk of bringing your pipeline to a screeching halt by accidentally under-powering your cluster? Measure, measure, measure...the specific metrics you should measure when considering whether you can remove nodes from your Redshift cluster. These are: Current and historic disk utilization; WLM concurrency and queue wait-times; % disk-based queries; Copy and Unload times...After studying the metrics described above, we concluded that we can remove two nodes from our cluster without impacting our workloads...We reduced the cost of operating this cluster by 28% with no negative impact on our pipeline performance!
- Communication-Efficient Learning of Deep Networks from Decentralized Data: We present a practical method for the federated learning of deep networks based on iterative model averaging, and conduct an extensive empirical evaluation, considering five different model architectures and four datasets. These experiments demonstrate the approach is robust to the unbalanced and non-IID data distributions that are a defining characteristic of this setting. Communication costs are the principal constraint, and we show a reduction in required communication rounds by 10–100× as compared to synchronized stochastic gradient descent.
- Reinventing Facebook’s data center network: F16 and HGRID are the topologies, and Minipack and the Arista 7368X4 are the platforms that are the core of our new data center network. They all bring significant improvements in power and space efficiency and reduce complexity in the overall network design, while building upon readily available, mature 100G optics. This new network will help us keep up with increasing application and service demands. We believe in working with the OCP community and networking ecosystem as a whole, so we have shared an overview of our network design in this blog and the complete design package for Minipack via OCP. Arista has also shared the specification from our joint development work with OCP.
- Wonderful recap. Learnings after a day at Serverless Days Boston: Serverless is a way of abstracting the infrastructure from the developer...it is about driving maximum business value to the customers...Serverless is a state of mind and its principles could be applied to any stack...Observability. This I would say was the core theme of the conference. We need tight feedback loops in our systems...Log high cardinality metrics as a part of events...In AWS, always adopt Role-Per-Function model and SAM managed polices for providing better limited security to your applications...Making Cost a first class metric and merging it with the principles of DevOps is being called FinDevOps...Track gross margins to determine the cloud spend.
- Using HTTPS + JSON over constrained networks is a bit crazy, but if you do here's a way to shrink the payload sie by ~65x. Breaking the 100bps barrier with Matrix, meshsim & coap-proxy.
- Nice recap of Embedded World 2019: I was a bit surprised to see the ARM demo of an image recognition neural network running on a mid-range Cortex-M microcontroller. The code used the CMSIS-NN API, and was all in C, mimicking the typical Python-based code you would see in frameworks running on beefier hardware. It is really interesting to see the same types of structures expressed over and over again in different languages...there is an impressively large number of dedicated hypervisors being built for the embedded market. A few of the ones that I found: The open-source ACRN kernel (supported by Intel), Lynx Mosaic, Sysgo PikeOS, Green Hills, QNX, Wind River.
- Another good recap. The main stories of QCon London ’19: building microservices the right way: One of the main recurring themes of the conference was that yes, microservices are old news — but building them correctly is only done by early adopters...He notes there are only two reasons for adopting microservices at all: Accomplish incredible “Computer Science!” feats; Achieve independence and velocity for your teams...This is what helped The Financial Times release 250 times more often and at a lot lower failure rate with their adoption of microservices. Sarah Wells from the FT posed the question that if you aren’t releasing multiple times a day or experimenting more often, consider what’s stopping you...High performing teams get to make their own decisions about tools and technology...Cloudflare, a CDN company, offers a FaaS model where your functions run in the JavaScript v8 engine hosted on of their 165 edge locations. Instead of spawning a docker process for a function invocation...what I found most fascinating instead was a talk from Chris Ford where he demonstrates how music theory can be represented as code.
- gojektech/weaver: a Layer-7 Load Balancer with Dynamic Sharding Strategies. It is a modern HTTP reverse proxy with advanced features
- bullet-db.github.io: A pluggable, persistence-less, real-time, query engine for arbitrary data on arbitrary stream processors.
- tensorflow/privacy (article): a Python library that includes implementations of TensorFlow optimizers for training machine learning models with differential privacy. The library comes with tutorials and analysis tools for computing the privacy guarantees provided.
- projectacrn/acrn-hypervisor: a device hypervisor reference stack and an architecture for running multiple software subsystems, managed securely, on a consolidated system by means of a virtual machine manager. It also defines a reference framework implementation for virtual device emulation, called the "ACRN Device Model".
- The book Microservice Architecture is now available for free.
- Researchers build nanoscale distributed DNA computing systems from artificial protocells: a method for implementing distributed DNA computing systems by compartmentalizing DNA devices inside artificial protocells.
- A Generalised Solution to Distributed Consensus: We derive an abstract solution to consensus, which utilises immutable state for intuitive reasoning about safety. We prove that our abstract solution generalises over Paxos as well as the Fast Paxos and Flexible Paxos algorithms. The surprising result of this analysis is a substantial weakening to the quorum requirements of these widely studied algorithms.



