Stuff The Internet Says On Scalability For September 27th, 2019

Wake up! It's HighScalability time:
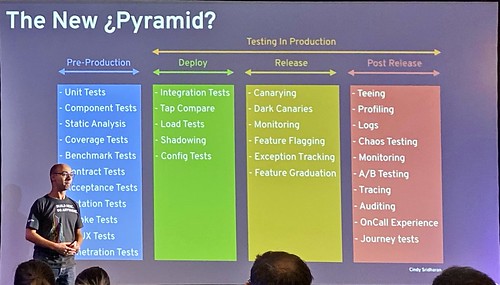
Nifty diagram of what testing looks like in an era or progressive delivery. (@alexsotob, @samnewman)
Do you like this sort of Stuff? I'd greatly appreciate your support on Patreon. I wrote Explain the Cloud Like I'm 10 for all who want to understand the cloud. On Amazon it has 55 mostly 5 star reviews (131 on Goodreads). They'll thank you for changing their life forever.
Number Stuff:
- 2: percentage of human DNA coding for genes, so all the extra code in your project is perfectly natural. And 99.9% of your DNA is like any other person's, so all that duplicate code in your project is also perfectly natural.
- 40%: do some form of disaster testing annually in production.
- 1 billion: Windows 10 devices in 2020.
- ~1.5: Bit-Swap better compression than GNU Gzip.
- 1 billion: Slack messages sent weekly.
- 1.4%: decline in electronic equipment salescompared to the same quarter of last year.
- 50%: increase year-over-year in enterprise adoption and deployments of multi-cloud. 80%+ of customers on all three clouds use Kubernetes. 1 in 3 enterprises are using serverless in production. AWS Lambda adoption grew to 36% in 2019, up 12% from 2017.
- $100 million: fund to empower individual creators, galvanize open-standard monetization service providers, and allow users to directly support content they value.
- #1: most dangerous software error is: Improper Restriction of Operations within the Bounds of a Memory Buffer.
- $0.030 – $0.035: Backblaze's target per gigabyte of storage cost.
- $16.5 billion: record investment in robot sector along with a staggering jump in the number of collaborative robot installations last year.
- 100,000: free AI generated headshots.
- 37%: Wi-Fi 6 single-user data rate is faster than 802.11ac.
Quotable Stuff:
- @cassidoo: My 55-year-old father-in-law has been trying to get a junior coding job for over 2 years and seeing him constantly get rejected for younger candidates at the last interview round is ageism in tech at its finest 😞
- Robert Wolkow: We've built an atomic scale device that's as disruptive to the transistor and as the transistor was to the vacuum tube. It will change everything. (paper)
- @gitlab: We learned that @NASA will be flying Kubernetes clusters to the moon 🚀
- Yunong Shi: The first classical bits used on the giant ENIAC machine are a room of vacuum tubes (around 17000 in total). On average, there was only one tube that fails every two days. On the other hand, for the first generation of qubits we have now, the average lifetime is on the scale of a millisecond to second...after about one hundred to one thousand operations, all qubits are expected to fail
- @wattersjames: "The latest SQL benchmarks on AWS demonstrated that YSQL is 10x more scalable than the maximum throughput possible with Amazon Aurora. "
- outworlder: AWS support is stellar. We have workloads on the three major cloud providers, and AWS support is better by an order of magnitude. If anything, this has spoiled us. When things that take minutes to solve (or figure out) on AWS takes days on another cloud provider, no amount of technical wizardry can make up for it. They won't be dragging your feet just because you have a lower level plan, but if you want to call them to solve stuff right now on the phone or have them showing up at your company with specialists in tow, then you have to fork over the required amount. It's well spent, IMHO.
- Andrei Alexandrescu: Speed Is Found In The Minds of People
- throwsurveill: It took basically until now for the bloom to come off the rose. Think about that. For 20 years Google has been supposedly hiring the smartest guys in the room and all it took was free food, some ball pits and slides, contributing some tech to open source, and working on a handful of "moonshots" that haven't gone anywhere to keep the sheen of innovation going. And it worked. For 20 years. People have been saying Google is the new Microsoft for a few years but it basically took until now for that to become consensus. Microsoft, who's been on the back foot until recently, has recast themselves as the new Open Source Champion, basically using the Google playbook from 20 years ago. And it's working!
- Jerry Neumann: Moats draw their power to prevent imitation from one of four basic sources: The state, Special know-how, Scale, or System rigidity.
- QuestionsHurt: I've used most hosting setups in my time, shared hosting, dedicated servers, VPS, PaaS like Heroku, EC2 et al., Serverless, and JAMStack like Netlify. Plus other things that sound new but aren't. I keep coming back to VPS like Digital Ocean, Vultr and the likes. You get more control of the server and more control of your bill. Which is vital to newborn projects.
- Slack: It’s a race to scale shared channels to fit the needs of our largest customers, some of which have upward of 160,000 active users and more than 5,000 shared channels.
- @colmmacc: I know that Internet is a great success and all but goddamnit UDP is such a piece of garbage. Even in the 70s, the designers should have had the sense to do fragmentation at layer 4, not layer 3, and put a UDP header in every packet. Don't get me started on DNS.
- @elkmovie: N.B.: the highest Geekbench 5 single-core score for *any* Mac is 1262. (2019 iMac 3.6) So the iPhone 11 now offers the fastest single-core performance of any computer Apple has ever made.
- @anuraggoel: Serverless has its place, but for the love of everything that is holy, please don't move your whole stack to serverless just because an AWS consultant told you to.
- @edjgeek: Best practice is not to couple lambda's in this pattern. For resiliency we recommend SNS/SQS/EventBridge for pub/sub and queueing in serverless. When locally testing, an event from any of these can be mocked for testing via 'sam local generate-event' use --help if needed
- @it4sec: If you plan to fuzz CAN Bus in real vehicle, please make sure that Airbags are disabled.
- 250bpm: It is said that every year the IQ needed to destroy the world drops by one point. Well, yes, but let me add a different spin on the problem: Every year, the IQ needed to make sense of the world raises by one point. If your IQ is 100 and you want to see yourself in 2039 just ask somebody with IQ 80 and listen carefully.
- Haowei Yuan: a Dropbox user request goes through before it reaches backend services where application logics are executed. The Global Server Load Balancer (GSLB) distributes a user request to one of our 20+ Point of Presences (PoPs) via DNS. Within each PoP, TCP/IP (layer-4) load balancing determines which layer-7 load balancer (i.e., edge proxies) is used to early-terminate and forward this request to data centers. Inside a data center, Bandaid is a layer-7 load balancing gateway that routes this request to a suitable service...The core concept of our work is to leverage real-time information to make better load balancing decisions. We chose to piggyback the server load information in HTTP responses because it was simple to implement and worked well with our setup.
- Marc Greenberg: There needs to be a fundamental shift in what a computer looks like for compute in memory to really take off. There are companies using analog properties of memory cells to do interesting things. Those technologies are still very early in their development, but they’re really interesting.
- @QuinnyPig: There's at least a 60% chance that I could start talking about a fictitious @awscloud MoonBase and I'd be suspected of breaking an NDA somewhere.
- Jeff Klaus: Globally we are still seeing increasing data center growth. As noted in a recent report, “the seven primary U.S. data center markets saw 171 megawatts (MW) of net absorption in H1 2019, nearly 57 percent of 2018’s full-year record. That absorption nearly eclipsed the 200 MW of capacity added in H1. Northern Virginia, the largest data center market in the world, accounted for 74 percent of net absorption in the primary markets.”
- Burke Holland: So is the cost of Serverless over-hyped? No. It's for real. Until you reach a sizeable scale, you'll pay very little if anything at all. Serverless is one of the most remarkable technologies to come your way in quite some time. Couple that with the automatic infinite scaling and the fact that you don't even have to deal with a runtime anymore, and this one is a no-brainer.
- Graham Allan: And 3D stacking for DDR4 and eventually DDR5, as well. And then increased capacity beyond that, you’re taking it on the DIMM and adding all the RC buffers and the data buffers. Registered DIMMS of 3D stacked devices is probably where you’re going to see the sweet spot for DDR5 for very very high capacity requirements. You can get 128 to 256 gigabytes, and maybe 512 gigabytes in the not-to-distant future, in one DIMM card. And that’s just DRAM.
- Andy Heinig: the ever-increasing expansion of autonomous driving will also place significantly higher demands on integration technology. The data transfer rate between the circuits will be very high because extensive image and radar data is processed, leading to large data quantities per unit of time. Then this data must be processed in the circuits of the chiplets, and therefore regularly exchanged between the circuits. This requires high data rates that can only be realized with fast and massively parallel interfaces, so the corresponding package technology also has to be prepared. Only approaches such as 2.5D integration (interposers) or fan-out technologies can satisfy these requirements.
- Kurt Shuler: It was also clear from the conference [HotChips] that AI is driving some huge chips, the largest being Cerebras’ 1.2 Trillion transistor 46,225 square mm wafer-sized chip, and that interconnect topologies and more distributed approaches to caching are becoming fundamental to making these designs work with acceptable throughput and power.
- JoeAltmaier: Ah, my sister endured all this sort of thing during 20 years as a VP in corporate America. She successfully deployed new data systems to 120 plants in 50 regions in one year. Didn't cost $25M. Her method? Ruthlessly purge the region of the old data system and install the new (web-based API to a central, new data system). Investigate every regional difference and consolidate into one model. Before deployment day, get all the regional Directors in one room and tell them it was going to happen. Tell them there was no going back, no push-back would be permitted, and have the CEO in the room to confirm this.
- NoraCodes: The elephant in the room (post?) is that the reason all these open chat protocols are failing is because of deliberate and serious damage done by attack from corporate software companies, especially Facebook and Google. Back in the day, I used XMPP to chat with people from all over the Internet, and so did a lot of my friends, precisely because it was easy to connect with people outside whatever walled garden you used primarily from a single desktop client software. Google and Facebook deliberately killed that model. That’s on them. Same thing with Slack, which had IRC and XMPP gateways for a long time.
- Maureen Tkacik: Nearly two decades before Boeing’s MCAS system crashed two of the plane-maker’s brand-new 737 MAX jets, Stan Sorscher knew his company’s increasingly toxic mode of operating would create a disaster of some kind. A long and proud “safety culture” was rapidly being replaced, he argued, with “a culture of financial bullshit, a culture of groupthink.”
- PaulAJ: "Core competencies" is a widely misunderstood term. Lots of people equate it to "business model", as in "we sell widgets so therefore selling widgets is our core competence". A thing is a core competence if, and only if: * It makes a difference to your customers. * It is difficult for your competitors to replicate. * It provides access to a wide range of markets.
- @mweagle: "Guarantees do not necessarily compose into systems." On Eliminating Error in Distributed Software Systems
- Erik Brynjolfsson: Artificial intelligence (AI) is advancing rapidly, but productivity growth has been falling for a decade, and real income has stagnated. The most plausible explanation is that it will take considerable time for AI-related technologies to be deployed throughout the economy.
- Lauren Smiley: The criminal oversights didn't end there. As Karen's body was unzipped from the body bag and laid out at the morgue, the coroner took note of a black band still encircling her left wrist: a Fitbit Alta HR—a smartwatch that tracks heartbeat and movement. A judge signed a warrant to extract its data, which seemed to tell the story Karen couldn't: On Saturday, September 8, five days before she was found, Karen's heart rate had spiked and then plummeted. By 3:28 in the afternoon, the Fitbit wasn't registering a heartbeat.
- DSHR: When HAMR and MAMR finally ship in volume they will initially be around 20% lower $/GB. L2 Drive promises a cost decrease twice as big as the cost decrease the industry has been struggling to deliver for a decade. What is more, their technology is orthogonal to HAMR and MAMR; drives could use both vacuum and HAMR or MAMR in the 2022-3 timeframe, leading to drives with capacities in the 25-28TB range and $/GB perhaps half the current value.
- Duje Tadin: We often neglect how we get rid of the things that are less important. And oftentimes, I think that’s a more efficient way of dealing with information. If you’re in a noisy room, you can try raising your voice to be heard — or you can try to eliminate the source of the noise.
- Desire Athow: With an uncompressed capacity of 9TB, it translates into a per TB cost of $6.55, about 12x less than the cheapest SSD on the market and 1/4 the price of the 12TB Seagate Exos X14, currently the most affordable hard disk drive on the market on a per TB basis. In other words, if you want a LOT of capacity, then tape is the obvious answer
- Michael Graziano: Attention is the main way the brain seizes on information and processes it deeply. To control its roving attention, the brain needs a model, which I call the attention schema. Our attention schema theory explains why people think there is a hard problem of consciousness at all. Efficiency requires the quickest and dirtiest model possible, so the attention schema leaves aside all the little details of signals and neurons and synapses. Instead, the brain describes a simplified version of itself, then reports this as a ghostly, non-physical essence, a magical ability to mentally possess items. Introspection – or cognition accessing internal information – can never return any other answer. It is like a machine stuck in a logic loop. The attention schema is like a self-reflecting mirror: it is the brain’s representation of how the brain represents things, and is a specific example of higher-order thought. In this account, consciousness isn’t so much an illusion as a self-caricature.
Useful Stuff:
- The equivalent of razor blades in SaaS is paying double for all the services you need to "support" the loss leader service. That's wrong.
- @aripalo: Someone once asked how AWS makes money with #serverless as you don't pay for idle. I'm glad that someone asked, I can tell you: CloudWatch. One account CW cost 55% because putMetricData. I'll have to channel my inner @QuinnyPig, start combing through bills & figure out options.
- @magheru_san: You do pay for idle but in a different way. If your Lambda function responds in single digit milliseconds, you are getting charged for 100ms or >10x than what your function actually consumed. Including if the function is sleeping or waiting for network traffic with an idle CPU
- @QuinnyPig: ...Then CloudWatch gets you again on GetMetric calls when Datadog pulls data in. Then you pay Datadog.
- @sysproc: Don't forget the price you pay per month for each unique metric namespace that you then pay more to populate via those PutMetricData calls.
- Videos from CloudNative London 2019 are now available.
- Fun graph of Moore's Law vs. actual transistor count along with a lively discussion thread. In 2002 michaelmalak: Not quite. It was the Itanium flop.The x86 instruction set was ugly. Everyone -- Intel, Microsoft, software developers -- wanted a clean slate. So Intel kind of put x86 development on the back burner and started working on Itanium. Itanium is what you see explode in the graph in 2002, leapfrogging the dreadfully slow Pentium 4 (although it had high transistor count and high clock rate, it was just bad). Despite Microsoft making a version of Windows for Itanium, Itanium was a commercial flop due to lack of x86 backward compatibility (outside of slow emulation).
- Behold the power of the in-memory cache. Splash the cache: how caching improved our reliability. The problem: a spike in webhook requests caused a backup do to slow DynamoDB look ups. Doubling the provisioned capacity is an insanely expensive temporary workaround and didn't really solve the problem. Switching to auto provisioning was 7x more expensive. The solution: an in-memory 3 second cache in the publisher. How much difference could 3 seconds make? A lot. They went from 300 reads per second to 1.4 reads per second—200x fewer database reads. And 3 seconds is short enough that when a webhook URL is updated they won't be inconsistent for long. Why use an in-memory cache than an external cache like Redis? So many reasons: No external dependencies; Minimal failure rate; No runtime errors; In-memory is orders of magnitude faster than any network request.
- A few videos from AppSec Global DC 2019 are now available.
- 10 Things to Consider While Using Spot Instances: Cost savings - customers can realize as much as 90% in cost savings. In fact, IDC has recently estimated that enterprises can save up to $4.85 Million over a period of 5 years by using Spot instances; Business flexibility and growth; Cost vs. Performance; Right-sizing instances for optimal performance; Developer & DevOps productivity; Application architectures; Enterprise grade SLA; Multi-cloud; Integration; Competitive advantage. @QuinnyPig: I have a laundry list of reasons why SaaS companies are a bad fit for meaningful cost optimization. Spotinst avoids nearly all of them. I like what they’re up to.
- Serverless: 15% slower and 8x more expensive. CardGames.io runs on AWS using a traditional mix of S3, CloudFront, EC2, Elastic Beanstalk, ELB, EBS, etc. at a cost of $164.21 a month. What happens if you move to a serverless platform? It's not all cookies and cream. Serverless setup was 15% slower and 8x more expensive: "Our API accepts around 10 million requests a day. That's ~35$ every day, just for API Gateway. On top of that Lambda was costing around ~10$ a day, although that could maybe be reduced by using less memory. Together that's around 45$ per day, or 1350$ per month, vs. ~164$ per month for Elastic Beanstalk." This generated much useful discussion.
- Hugo Grzeskowiak: If you have constant load on your API, use EC2 or (if containerised) ECS. Choose instances based on the application profile, e.g. CPU, memory or throughput. There's also instances with ephemeral volumes which are the fastest "hard drives" in case that's the bottleneck. - If your load is high but fluctuating a lot (e.g. only having traffic from one time zone during rush hours), consider the burstable instances (t3 family). For non customer facing services (backups, batch jobs, orchestration) Lambda is often a good choice. - Lambda can be used for switching Ops costs to AWS costs.
- Samuel Smith: Though I've only moved one off serverless, the general idea is to leave them all there until they find some traction, then when the cost warrants it, convert them
- Jeremy Cummins: You can use an ALB instead of API Gateway in front of a Lambda. You can also configure an Elastic Beanstalk cluster, ECS cluster, or any other container service to serve as a proxy to serve requests from your lambdas (instead of an ALB or API Gateway). If you are serving your lambda requests through a CDN as you described you can use Lambda@Edge to modify the request responses directly, so no load balancer or proxy needed.
- dread_username: Don't forget to factor in the managed UNIX Administration costs too I think this is the real argument. Fully burdened cost for a senior developer where I live is about US$150000 a year. Given the article number of $1200 a month extra ($16200 a year), if a single developer can leverage serverless for an extra 11% revenue, it's paid for itself, and the product potentially has more features for the market.
- marcocom: So, the reason serverless doesn’t work for most is because they don’t truly buy-in to the heavy front-end necessary to run it. They use their old JSP-style approach and that doesn’t fit the philosophy. You have to believe in JavaScript and a server-side comprises of small stupid lambdas that only know their tiny slice of the whole picture and the data they send to the front end to be consumed and persisted by a very smart stateful single-page-application.
- endproof: Serverless is not meant to run your api or anything with relatively consistent volume. It’s meant to serve for things that have huge spikes in traffic that would be uneconomical to have resources allocated for consistently. Of course it’s slower if they’re dynamically spinning up processes to handle spikes in traffic.
- TheBigLewinski: Given how the code was running in the first place, directly from a server behind a load balancer, why was the API gateway used? This could have been loaded into a Lambda function and attached to the ALB, as a direct replacement for the Ec2 instances. The author then admits memory simply could have been lowered, but doesn't provide any more detail. I'm guessing if that level of traffic is currently being handled by a "small" instance, the level of memory per request should be reduced to the bare minimum. But there were no details provided about that. There are billing details on the instances, but for the latter parts, we'll just have to take their word that it was all properly -and optimally- implemented (And they obviously were not). This is, at best, a lesson on the consequences of haphazard deployments and mindlessly buying into hype. But instead of digging in, to more deeply understand the mechanics of building an app and how to improve, they blamed the technology with a sensationalist headline.
- abiro: PSA: porting an existing application one-to-one to serverless almost never goes as expected. 1. Don’t use .NET, it has terrible startup time. Lambda is all about zero-cost horizontal scaling, but that doesn’t work if your runtime takes 100 ms+ to initialize. The only valid options for performance sensitive functions are JS, Python and Go. 2. Use managed services whenever possible. You should never handle a login event in Lambda, there is Cognito for that. 3. Think in events instead of REST actions. Think about which events have to hit your API, what can be directly processed by managed services or handled by you at the edge. Eg. never upload an image through a Lamdba function, instead upload it directly to S3 via a signed URL and then have S3 emit a change event to trigger downstream processing. 4. Use GraphQL to pool API requests from the front end. 5. Websockets are cheaper for high throughput APIs. 6. Make extensive use of caching. A request that can be served from cache should never hit Lambda. 7. Always factor in labor savings, especially devops. The web application needs of most startups are fairly trivial and best supported by a serverless stack. Put it another way: If your best choice was Rails or Django 10 years ago, then it’s serverless today.
- claudiusd: did the same experiment as OP and ran into the same issues, but eventually realized that I was "doing serverless" wrong. "Serverless" is not a replacement for cloud VMs/containers. Migrating your Rails/Express/Flask/.Net/whatever stack over to Lambda/API Gateway is not going to improve performance or costs. You really have to architect your app from the ground-up for serverless by designing single-responsibility microservices that run in separate lambdas, building a heavy javascript front-end in your favorite framework (React/Ember/Amber/etc), and taking advantage of every service you can (Cognito, AppSync, S3, Cloudfront, API Gateway, etc) to eliminate the need for a web framework. I have been experimenting with this approach lately and have been having some success with it, deploying relatively complex, reliable, scalable web services that I can support as a one-man show.
- danenania: "It's also great for when you're first starting out and don't know when or where you'll need to scale." To me this is probably the most significant benefit, and one that many folks in this discussion strangely seem to be ignoring. If you launch a startup and it has some success, it's likely you'll run into scaling problems. This is a big, stressful distraction and a serious threat to your customers' confidence when reliability and uptime suffer. Avoiding all that so you can focus on your product and your business is worth paying a premium for. Infrastructure costs aren't going to bankrupt you as a startup, but infrastructure that keeps falling over, requires constant fiddling, slows you down, and stresses you out just when you're starting to claw your way to early traction very well might.
- This nuanced discussion from Riot Games on the Future of League's Engine is a situatiion a lot of projects find themselves in. Do they go engine-heavy and move more functionality into C++ or engine-light and move more functionality into scripting? You adopt a scripting language to make your life simpler. Put the high performing core in C++ and bind it to a much easier to use scripting language. Who wants to go through a compile cycle when you can dynamically run code and get stuff done? But eventually you find clean abstractions break down and core functionality is all over the place and it becomes a nightmare to extend and maintain. Riot has consciously choosen to move away from scripting and use more C++: "The reasoning described in this article has been the direction that the Gameplay group on League has been walking for a couple years now. This has lead to some shifts on how we approach projects, for example how the Champions team encapsulated the complexity of Sylas into higher-level constructs and dramatically simplified the script implementation involved. The movement towards engine-heavy and explicitly away from engine-light will provide us with a more secure footing for the increasing complexity of League." You may still need a scripting layer for desginers and users, but put the effort into making the abstractions in your core easier to use and keep it there.
- One person's boring is anothers pit of complexity. The boring technology behind a one-person Internet company. This is a great approach, but it it really that boring? It's only boring if you already know the technology. Imagine a person just starting having to learn all this "boring" stuff? It would be daunting. It's only boring because you already know it. The new boring is always being reborn.
- Root Cause is a Myth: root cause can’t be determined in complex socio-technical systems...Instead of choosing blame and finger-pointing when breaches happen, DevSecOps practitioners should seek shared understanding and following blameless retrospective procedures to look at a wider picture of how the event actually unfolded. We shouldn’t fire the engineer who didn’t apply the patches, nor the CISO who hired the engineer. Instead, we look at what organizational decisions contributed to the breach.
- It's always hard to change a fundamental assumption of your architecture. Twitter took a long time to double their character count to 280. Slack is now supports shared channels—A shared channel is one that connects two separate organizations. Yah, it's a pain to change, but the pain of trying to create an architecture so flexible it has no limits is much greater. Make limits. Optimize around those limits. And stick your tongue out at anyone who bitches about technical debt over a taking pride in a working system. How Slack Built Shared Channels.
- The backend systems used the boundaries of the workspace as a convenient way to scale the service, by spreading out load among sharded systems. Specifically, when a workspace was created, it was assigned to a specific database shard, messaging server shard, and search service shard. This design allowed Slack to scale horizontally and onboard more customers by adding more server capacity and putting new workspaces onto new servers.
- We decided to have one copy of the shared channel data and instead route read and write requests to the single shard that hosts a given channel. We used a new database table called shared_channels as a bridge to connect workspaces in a shared channel.
- This makes sense. Replace limits with smarts. Password Limits on Banks Don't Matter: banks aggressively lock out accounts being brute forced. They have to because there's money at stake and once you have a financial motivator, the value of an account takeover goes up and consequently, so does the incentive to have a red hot go at it. Yes, a 5-digit PIN only gives you 100k attempts, but you're only allowed two mistakes...Banks typically use customer registration numbers as opposed to user-chosen usernames or email addresses so there goes the value in credential stuffing lists..."Do you really think the only thing the bank does to log people on is to check the username and password?"...implement additional verification processes at key stages of managing your money.
- HotChips 31 keynote videos are available.
- From the Critical Watch Report: Encryption-related misconfigurations are the largest group of SMB security issues; In SMB AWS environments, encryption & S3 bucket configuration are a challenge; Weak encryption is a top SMB workload configuration concern; Most unpatched vulnerabilities in the SMB space are more than a year old; The three most popular TCP ports account for 65% of SMB port vulnerabilities; Unsupported Windows versions are rampant in mid-sized businesses; Outdated Linux kernels are present in nearly half of all SMB systems; Active unprotected FTP servers lurk in low-level SMB devices; SMB email servers are old and vulnerable.
- Update on fsync Performance: In this post, instead of focusing on the performance of various devices, we’ll see what can be done to improve fsync performance using an Intel Optane card...The above results are pretty amazing. The fsync performance is on par with a RAID controller with a write cache, for which I got a rate of 23000/s and is much better than a regular NAND based NVMe card like the Intel PC-3700, able to deliver a fsync rate of 7300/s. Even enabling the full ext4 journal, the rate is still excellent although, as expected, cut by about half.
- It turns out the decentralized DNS system is actually quite centralized in practice. DNS Resolver Centrality: While 90% of users have a common set of 1.8% of open resolvers and AS resolver sets configured (Figure 4), 90% of users have the entirety of their DNS queries directed to some 2.6% of grouped resolvers. In this case out or some 15M experiments on unique end points, some 592 grouped resolvers out of a total pool of 23,092 such resolver sets completely serve 90% of these 15M end points, and these users direct all their queries to resolvers in these 592 resolver sets. Is this too centralised? Or is it a number of no real concern? Centrality is not a binary condition, and there is no threshold value where a service can be categorised as centralised or distributed. It should be noted that the entire population of Internet endpoints could also be argued to be centralised in some fashion. Out of a total of an estimated 3.6 billion Internet users, 90% of these users appear to be located within 1.2% of networks, or within 780 out of a total number of 65,815 of ASNs advertised in the IPv4 BGP routing system
- Why is Securing BGP So Hard?: BGP security is a very tough problem. The combination of the loosely coupled decentralized nature of the Internet and a hop-by-hop routing protocol that has limited hooks on which to hang credentials relating to the veracity of the routing information being circulated unite to form a space that resists most conventional forms of security.
- So many ways to shoot yourself in the lambda. Serverless Cost Containment: concurrency can bite you by parallelising your failures, enabling you to rack up expenses 1,000 times faster than you thought!; A common error cause I've seen in distributed systems is malformed or unexpected messages being passed between systems, causing retry loops; If a Lambda listening to an SQS queue can't process the message, it returns it to the queue... and then gets given it back again again!; A classic new-to-serverless example is related to loops: an S3 bucket event (or any other Lambda event source) triggers a function that then writes back to the same source, causing an infinite loop; Using messages and queues as a way to decouple your functions is generally a good architectural practice to use; it can also protect you from some cost surprises; Create dashboards to visually monitor for anomalies; Setting a billing alert also serve as a catch-all for other scenarios that you'd want to know about (e.g. being attacked in a way that causes you to consume resources).
- High autonomy and little hierarchy is a trait tech companies and startups share. Software Architecture is Overrated, Clear and Simple Design is Underrated: Start with the business problem; Brainstorm the approach; Whiteboard your approach; Write it up via simple documentation with simple diagrams; Talk about tradeoffs and alternatives; Circulate the design document within the team/organization and get feedback.
- No disagreement with this well written and well thought out article, but the idea that anyone can agree on what is simple and clean in any complex domain is wishful thinking. That's why there are so many rewrites on projects. New people coming in that were not part of the context that produced the "simple and clean" design so the inevitably don't understand what's going on, so they create their new "simple and clean" system. Complexity happens one decision at a time and if you weren't part of those decisions chances are you won't understand the resulting code. Prgrammers produce solutions, let's stop pretending they are simple and clean.
- gregdoesit: We had a distributed systems expert join the team, who was also a long-time architect. A junior person invited him to review his design proposal on a small subsystem. This experienced engineer kept correcting the junior engineer on how he’s not naming things correctly and mis-using terms. The design was fine and the tradeoffs were good and there was no discussion about anything needing changes there, but the junior engineer came out devastated. He stopped working on this initiative, privately admitting that he feels he’s not experienced enough to design anything this complex and first needs to read books and learn how it’s done “properly”. This person had similar impact on other teams, junior members all becoming dis-engaged from architecture discussions. After we figured out this pattern, we pulled this experienced engineer aside and had a heart to heart on using jargon as a means to prove your smart, opposed to making design accessible to everyone and using it to explain things. I see the pattern of engineers with all background commenting and asking questions on design documents that are simple to read. But ones that are limiting due to jargon that’s not explained in the scope of the document get far less input.
- And here's a great explanation of a common at attractor in the chaotic dynamical system that is a company. Why are large companies so difficult to rescue (regarding bad internal technology): There are two big problems that plague rescue efforts at big companies: history and trust...All of which helps explain why technology rescues at bigger, older companies are so difficult. One is constantly fighting against history...To a large extent “be agile” is almost synonymous with “trust each other.” If you’re wondering why large companies have trouble being agile, it is partly because it is impossible for 11,000 people to trust each other the way 5 people can. That is simply reality. Until someone can figure out the magic spell that allows vast groups of people, in different countries, with different cultures, speaking different languages, to all trust each other as if they were good friends, then people in the startup community need to be a lot more careful about how carelessly they recommend that larger companies should be more agile.
- Everything You Need To Know About API Rate Limiting. An excellent overview of different methods—request queues, throttling, rate-limiting algorithms—one to add would be use an API Gateway and let them worry about it.
- The 64 Milliseconds Manifesto: In an interactive software application, any user action SHOULD result in a noticeable change within 16ms, actionable information within 32ms, and at least one full screen of content within 64ms. dahart: Waiting for the response before updating the screen is the wrong answer. It’s not impossible, you’re assuming incorrectly that the manifesto is saying the final result needs to be on screen. It didn’t say that, it said the app needs to respond to action visually, not that the response or interaction sequence must be completed within that time frame. The right answer for web and networked applications is to update the screen with UI that acknowledges the user action and shows the user that the result is pending. Ideally, progress is visible, but that’s tangential to the point of the manifesto. A client can, in fact, almost always respond to actions within these time constraints. The point is to do something, rather than wait for the network response.
- StackOverflow on why they love love love .NET Core 3.0. The presentation is glitzy, not your normal tech blog post. Can't wait to see the series on Netflix. Stack Overflow OLD. It's faster; apps can run on Windows, Macs, Linux, and run in Azure cloud; cloud deploys are easier because there are fewer moving pieces; SO is being broken up into modules that can be run in different areas which allows experimenting with k8s and Docker; most interestingly since they can run in a container they can ship appliances to customers which lowers support costs and makes it easier to onboard customers; they can move code to become middleware; it's easier to test because they can test end-to-end; since .NET core is on GitHub they can fix errors; they can just build software instead of dealing with the meta of building software.
Soft Stuff:
- RSocket (video): Developed by Netifi in collaboration with Netflix, Facebook, Pivotal, Alibaba and others, RSocket combines messaging, stream processing and observability in a single, lightweight solution that provides the connectivity needed for today’s web, mobile and IoT applications. Unlike older technologies such as REST or gRPC, RSocket is equally adept at handling service calls as well as high-throughput streaming data and is at home in the datacenter as well as in the cloud, browsers and mobile/IoT devices.
- fhkingma/bitswap (article, video): We introduce Bit-Swap, a scalable and effective lossless data compression technique based on deep learning. It extends previous work on practical compression with latent variable models, based on bits-back coding and asymmetric numeral systems. In our experiments Bit-Swap is able to beat benchmark compressors on a highly diverse collection of images.
- dgraph-io/ristretto (article): a fast, concurrent cache library using a TinyLFU admission policy and Sampled LFU eviction policy.
Pub Stuff:
- Weld: A Common Runtime for High Performance Data Analytics (article): Weld uses a common intermediate representation to capture the structure of diverse dataparallel workloads, including SQL, machine learning and graph analytics. It then performs key data movement optimizations and generates efficient parallel code for the whole workflow.
- Low-Memory Neural Network Training: A Technical Report: Using appropriate combinations of these techniques, we show that it is possible to the reduce the memory required to train a WideResNet-28-2 on CIFAR-10 by up to 60.7x with a 0.4% loss in accuracy, and reduce the memory required to train a DynamicConv model on IWSLT'14 German to English translation by up to 8.7x with a BLEU score drop of 0.15.
- Quantum Supremacy Using a Programmable Superconducting Processor: The tantalizing promise of quantum computers is that certain computational tasks might be executed exponentially faster on a quantum processor than on a classical processor. A fundamental challenge is to build a high-fidelity processor capable of running quantum algorithms in an exponentially large computational space. Here, we report using a processor with programmable superconducting qubits to create quantum states on 53 qubits, occupying a state space 253 ∼1016 Measurements from repeated experiments sample the corresponding probability distribution, which we verify using classical simulations. While our processor takes about 200 seconds to sample one instance of the quantum circuit 1 million times, a state-of-the-art supercomputer would require approximately 10,000 years to perform the equivalent task. This dramatic speedup relative to all known classical algorithms provides an experimental realization of quantum supremacy on a computational task and heralds the advent of a much-anticipated computing paradigm.



