Behind AWS S3’s Massive Scale

This is a guest article by Stanislav Kozlovski, an Apache Kafka Committer. If you would like to connect with Stanislav, you can do so on Twitter and LinkedIn.
AWS S3 is a service every engineer is familiar with.
It’s the service that popularized the notion of cold-storage to the world of cloud. In essence - a scalable multi-tenant storage service which provides interfaces to store and retrieve objects with extremely high availability and durability at a relatively low cost. Customers share all of the underlying hardware.
It is one of the most popular services in AWS.
Through 18 years since its release in 2006, it has grown into a behemoth of an offering, spanning 31 regions and 99 availability zones as well as boasting numbers that show ground-breaking scale:
- 100 million requests a second
- 400 terabits a second
- 280 trillion objects stored
Here is a short timeline of the major features ever since its release:
- 2006: S3 officially launched
- 2012: Glacier - a low-cost service for data archiving and long-term backup - introduced (retrieval times take minutes to hours)
- 2013: S3 Intelligent-Tiering - a feature that automatically moves your data the most cost-effective access tier
- 2015: Standard-Infrequent Access - a new tier for data that’s less frequently accessed, but requires rapid access when needed
- 2018: Glacier Deep Archive - cheaper Glacier with much slower retrieval times (12 hours)
- 2020: Strong read-after-write consistency introduced
- 2021: Object Lambda - allow customers to add their own code to S3 GET requests, modifying data as its returned to an application
- 2023 - S3 Express released, offering 10x better latencies (single-digit) and 50% cheaper request costs.
It started as a service optimized for backups, video and image storage for e-commerce websites - but eventually grew in scale and demand to support being the main storage system used for analytics and machine learning on massive data lakes. Looking at current trends, it seems to be becoming the staple storage backbone for any cloud-native data infrastructure.
Architecture
S3 is said to be composed of more than 300 microservices.
It tries to follow the core design principle of simplicity.
You can distinct its architecture by four high-level services:
- a front-end fleet with a REST API
- a namespace service
- a storage fleet full of hard disks
- a storage management fleet that does background operations, like replication and tiering.
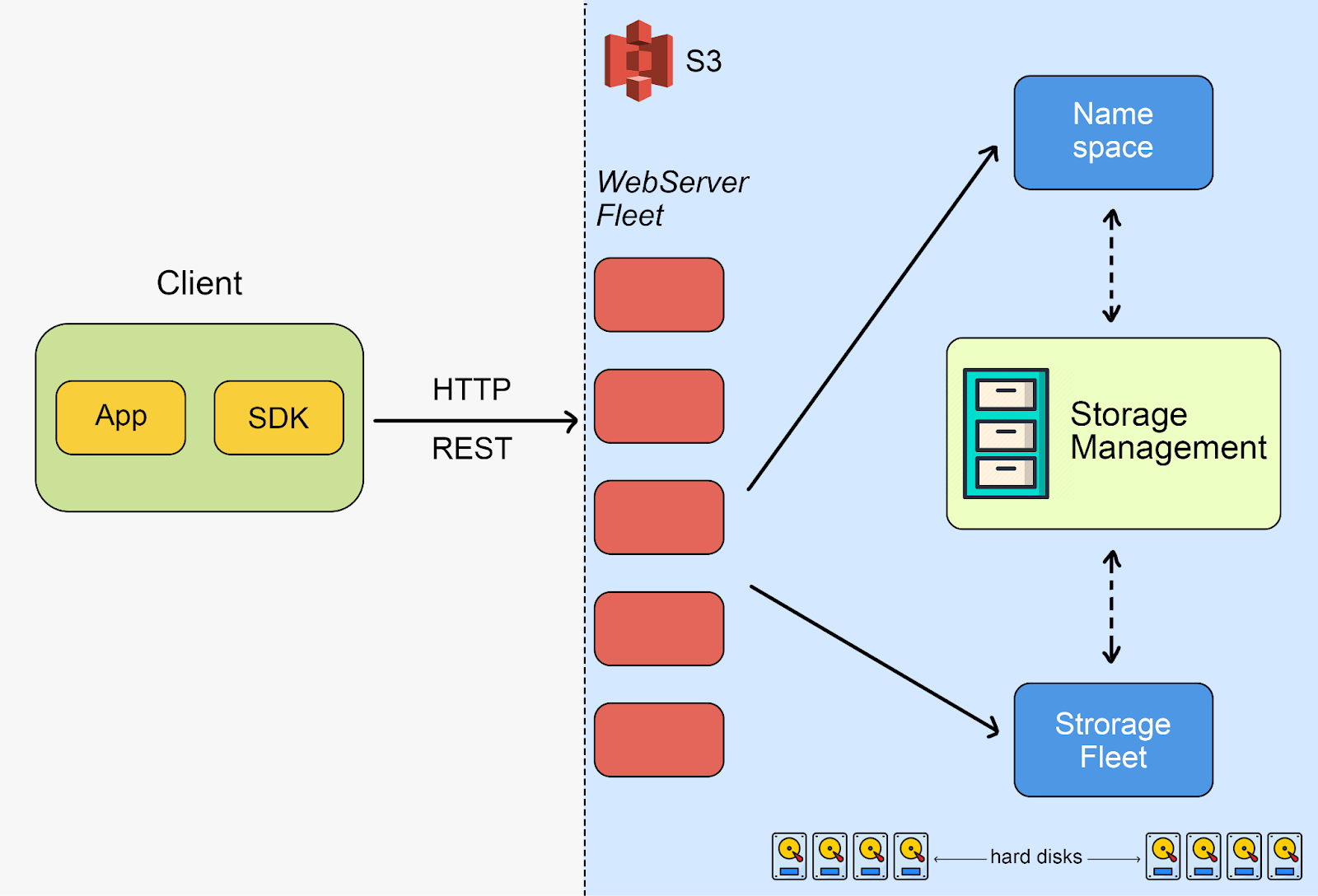
Said simply - it’s a multi tenant object storage service with an HTTP REST API.
It is said that AWS ships its organizational chart.
That is, the architecture strongly exhibits Conway’s Law: the theory that organizations will design systems that copy their communication structure.
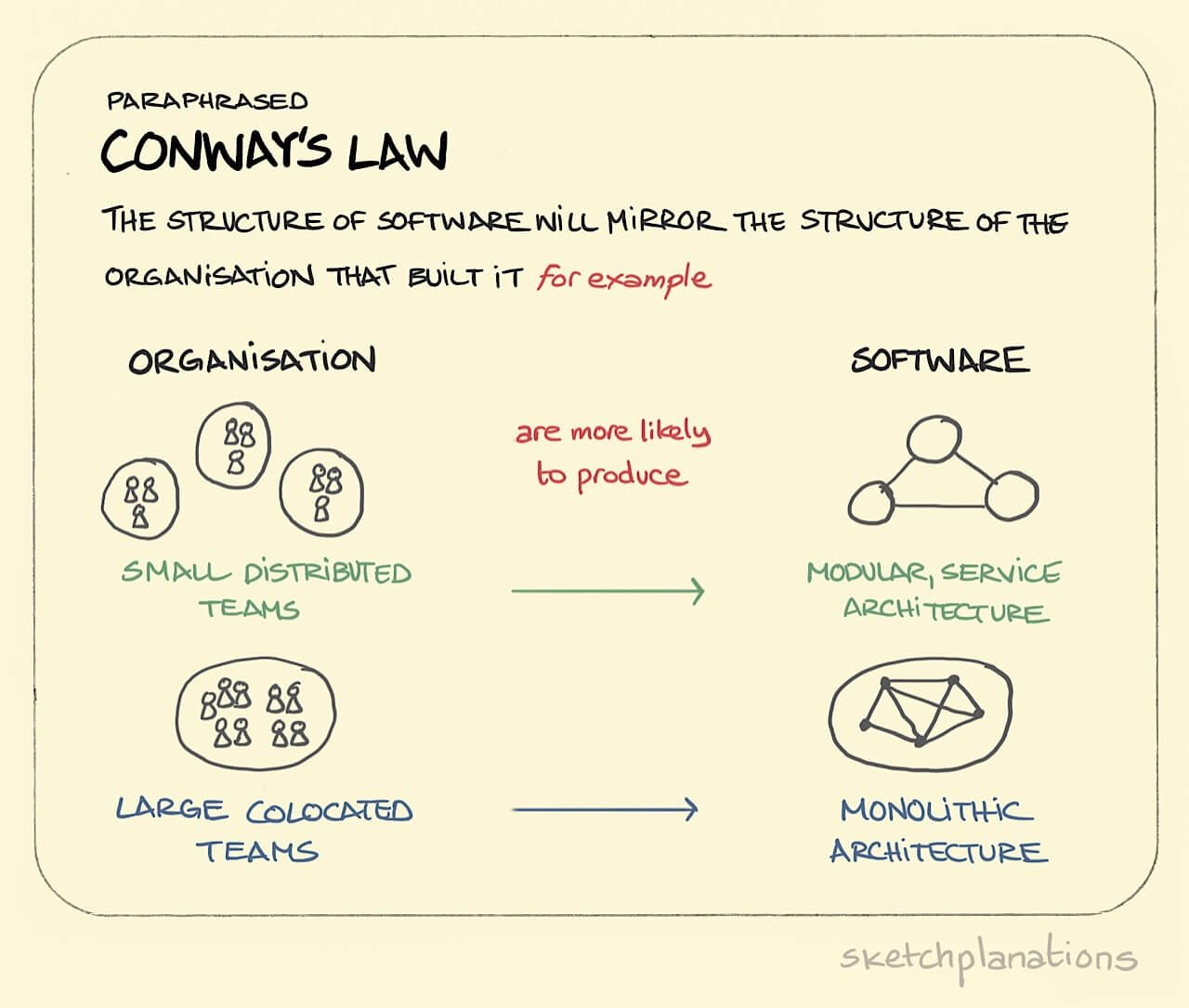
Each of the four components are part of the S3 organization, each with their own leaders and number of teams that work on it. It is said that this continues recursively - the boxes in the chart contain their own individual nested components with their own teams and fleets. In many ways, they all operate like independent businesses.
The way each team interacts with others is literal API-level contracts, for which engineers are on the hook for keeping up.
Storage Fleet
S3 is just a really big system built out of A LOT (millions) of hard disks.
At the core of all of this are the storage node servers. They are simple key-value stores that persist object data to hard disks. The node servers only shards of the overall object data, with the control plane replicating said shards across many different nodes.
AWS has written a lot about their newly-written storage backend - ShardStore. It initially started with just 40k lines of Rust.
Under the hood, it’s a simple log-structured merge tree (LSM Tree) with shard data stored outside the tree to reduce write amplification.
It uses a soft-updates-based crash consistency protocol and is designed from the ground up to support extensive concurrency. It leverages several optimizations to support efficient HDD IO usage like scheduling of operations and coalescing.
This is perhaps the most key piece of code in S3 and as such, its development process is highly invested in. AWS has written at length about the lightweight formal verification methods they’ve integrated into their developers’ workflows.
Hard Drives
Hard drives are an old technology that’s not ideal for all use cases - they’re constrained for IOPS, they have high seek latency and are physically fragile.
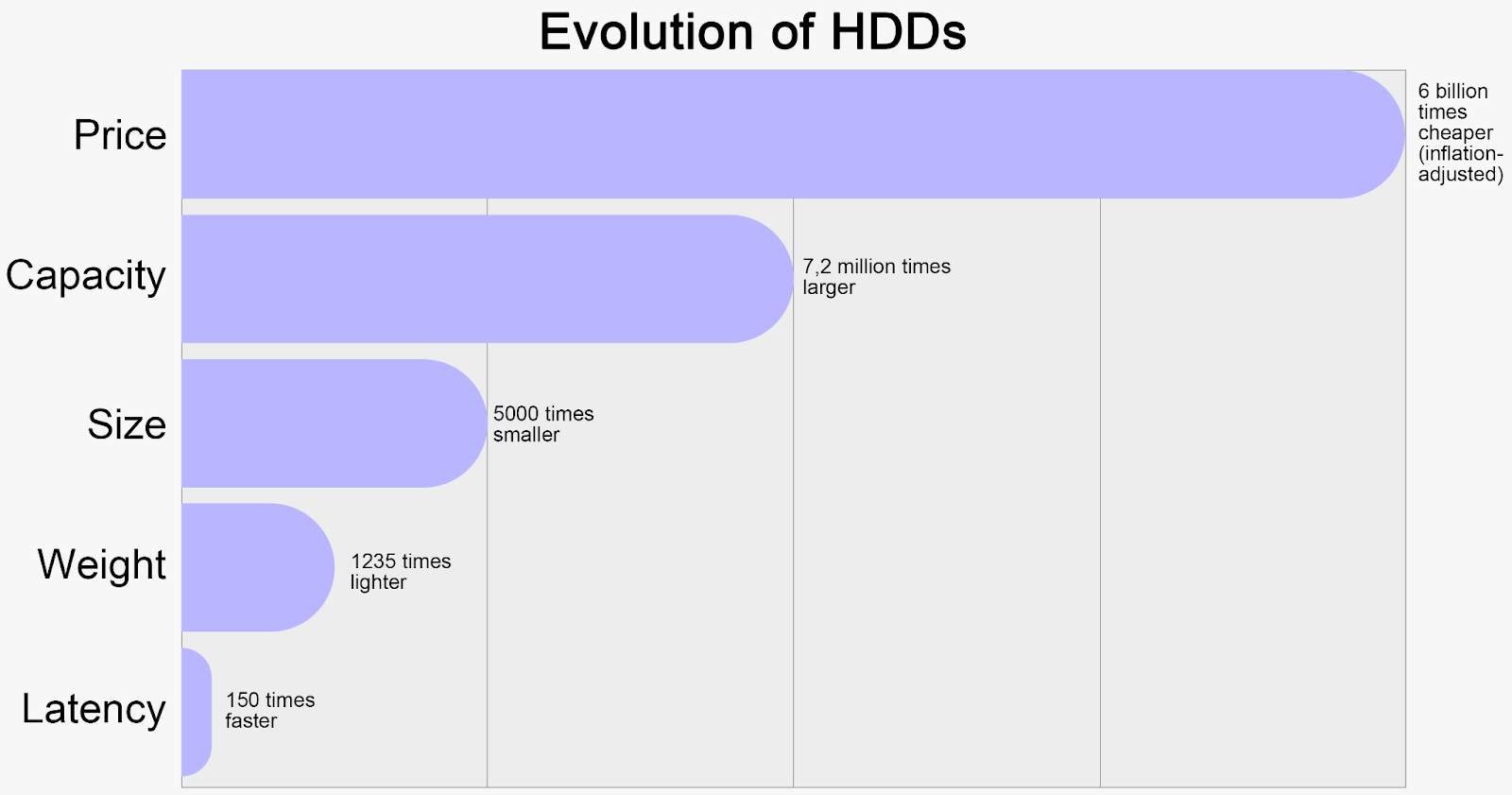
It’s worth stepping back and checking their evolution:
- 1956: a 3.75MB drive cost $9k
- 2024: 26TB drives exist, where 1TB costs $15
In their existence, they've seen exponential improvement:
- price: 6,000,000,000 times cheaper per byte (in inflation-adjusted $)
- capacity increased 7,200,000 times
- size decreased 5,000 times
- weight decreased 1,235x
But one problem persists - they’re constrained for IOPS. They have been stuck at 120 IOPS for a long time. Similarly, the latency has not kept up in the same pace as the rest.
This means that per byte, HDDs are becoming slower.
In an increasingly latency-sensitive world, it’s hard for an HDD to keep up with the demanding requirements modern systems have.
Yet, S3 found a way to deliver tolerable latency while working around this - it heavily leverages parallel IO.
Replication
In storage systems, redundancy schemes are a common practice.
They are most often associated with extra durability - helping protect data against hardware failures. If one disk fails, a copy of the data remains present in another disk, hence it isn’t lost.
An under-appreciated aspect of these redundancy schemes is managing heat. Such schemes spread the load out and give your system the flexibility to direct read traffic in a balanced way.
S3 uses Erasure Coding (EC). It’s a complex data protection method which breaks data into K shards with M redundant “parity” shards. EC allows you to recover the data from any K shards out of the total K+M total shards.
e.g. break data into 10 fragments, add 6 parity shards. You can lose up to 6 shards.
Replication is expensive from a durability perspective (a lot of extra capacity is taken), yet is efficient from an I/O perspective.Erasure Coding helps S3 find a middle balance, by not taking too much extra capacity for the durability needs (they aren’t replicating the data 3x) while still providing flexible I/O opportunity and surviving the same number of disk failures.
Sharding
S3 tries to spread these shards as broadly as they can. They’ve shared that they have tens of thousands of customers with data stored over a million physical drives.
Spreading the data around gives them the following benefits:
1. Hot Spot Aversion
When the data is well spread out, no single customer can cause a hot spot that affects the system. Hot spots are particularly troublesome and worth avoiding, as they introduce cascading delays throughout the system and in the worst case can result in unpleasant domino effects.
2. Burst Demand
Similarly, the extra parallelism afforded by each drive the shards are on can allow for greater burst IO compared to what a naive solution may bring. (e.g the data replicated on 3 drives)
3. Greater Durability
The more the shards are spread, the greater the durability. You can sustain more individual machine failures.
4. No Read Amplification
Read amplification denotes how many disk seeks a single read causes.Assuming homogeneous hardware, a single read will still cause roughly the same amount of disk seeks. But since the data is spread around, those seeks will not be on the same drive.
The less disk seeks one HDD needs to do, the better. This reduces the likelihood of high latency.
Heat Management at Scale
Given the scale, one of S3’s biggest technical problems is managing and balancing this I/O demand across the large set of hard drives.
The overall goal is to minimize the number of requests that hit the same disk at any point in time. Otherwise, as we mentioned - you garner hot spots and accumulate tail latency that eventually grows to impact the overall request latency.
In the worst case, a disproportionate number of requests on the same drive can cause stalling as the limited I/O the disk provides becomes exhausted. This results in overall poor performance on requests that depend on the drive(s). As you stall the requests, the delay gets amplified up through layers of the software stack - like Erasure Coding write requests for new data or metadata lookups.
The initial placement of data is key, yet also tricky to get right because S3 doesn’t know when or how the data is going to be accessed at the time of writing.
The S3 team shares that due to the sheer scale of the system and its multi tenancy, this otherwise hard problem becomes fundamentally easier.
S3 experiences so-called workload decorrelation. That is the phenomenon of seeing a smoothening of load once it’s aggregated on a large enough scale.
The team shares that most storage workloads remain completely idle for most of the time. They only experience a sudden load peak when the data is accessed, and that peak demand is much higher than the mean.
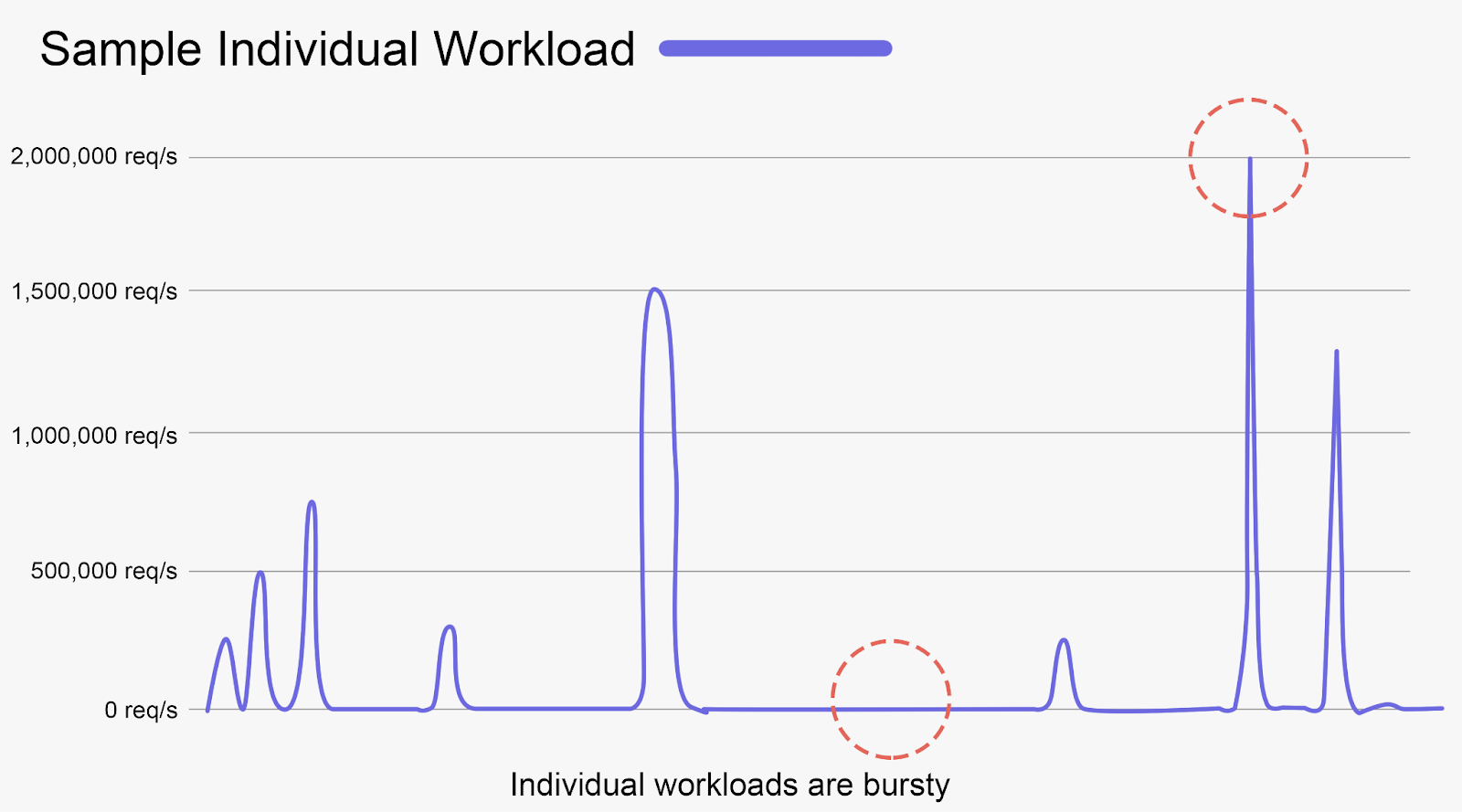
But as the system aggregates millions of workloads, the underlying traffic to the storage flattens out remarkably. The aggregate demand results in a smoothened out, more predictable throughput.
When you aggregate on a large enough scale, a single workload cannot influence the aggregate peak.
The problem then becomes much easier to solve - you simply need to balance out a smooth demand rate across many disks.
Parallelism
Parallelism has aligned incentives for both AWS and its customers - it unlocks better performance for the customers and allows S3 to optimize for workload decorrelation.
Let us take some numbers as examples:
Two Opposite Examples
Imagine a 3.7 Petabyte S3 bucket. Say it takes in 2.3 million IOs a second.
With 26 TB disks, you’d only need 143 drives to support the 3.7PB capacity.
But with the low 120 IOPS per disk, you’d need 19,166 drives for the 2.3m IO demand! That’s 13,302% more drives.
Now imagine the opposite - a 28PB S3 bucket with just 8,500 IOs a second.
With 120 IOPS per disk, you’d need 71 drives for the IOs.
With 26TB disks, you’d need 1076 drives for the capacity. That’s 1,415% more drives.
A 134x imbalance in one case, 15x in another.
S3 likely has both types of workloads, but the large drive requirement proves the need of parallelism to achieve the necessary read throughput.
Parallelism in Practice
S3 leverages parallelism in two ways:
Across Servers
Parallelism begins at the clients!
Instead of requesting all the files through one client with one connection to one S3 endpoint, users are encouraged to create as many powers as possible with as many parallel connections as possible. This utilizes many different endpoints of the distributed system, ensuring no single point in the infrastructure becomes too hot (e.g caches)
Intra-Operation
Within a single operation inside a connection, S3 also leverages parallelism.
- PUT requests support multipart upload, which AWS recommends in order to maximize throughput by leveraging multiple threads.
- GET requests similarly support an HTTP header denoting you read only a particular range of the object. AWS again recommends this for achieving higher aggregate throughput instead of the single object read request.
Metadata and the Move to Strong Consistency
In 2020, S3 introduced strong read-after-write consistency. Meaning that once you write a new object or overwrite an existing one, any subsequent read will receive the latest version of the object.
This was a massive change given the scale S3 was operating on, especially considering it came with zero impact to performance, availability or cost.
S3 has a discrete subsystem for storing per-object metadata. Because the metadata write/read is part of the critical data path for most requests, the system’s persistence tier was designed to use a highly resilient caching technology ensuring that even if it was impaired, S3 requests would succeed.
This meant that writes might flow through one part of the cache infrastructure while reads might query another part, resulting in a stale read. It is said this was the main source of S3’s eventual consistency.
As part of other features, S3 introduced new replication logic into its persistence tier that allowed them to reason about the per-object order of operations. As a core piece of their cache coherency protocol, this allowed them to understand if a cache’s view of an object is stale.
A new component was introduced that would track this. Said component acts as a witness to S3 writes and a read barrier during S3 reads. When the component recognizes that a value may be stale, it is invalidated from the cache and read from the persistence layer.
Durability
S3 offers 11 nines of durability - 99,999999999. The expected average annual loss is therefore 0.000000001% of objects stored.
Said simply, if you store 10,000 objects in S3, you can expect to lose a single object once every 10,000,000 years.
Hardware Failure
Achieving 11 nines of durability is a difficult feat. Hard drives frequently fail and at S3’s scale, it’s likely an hourly occurrence.
In theory - durability is simple. As hard drives fail, you repair them. As long as the repair rate matches the failure rate, your data is safe.
In practice - to ensure this process is reliable in the face of unpredictable failures, you need to build a system around it.
AWS shared a simple real-world example where failures accumulate - imagine the data center is in a hot climate and a power outage occurs. Its cooling system stops working. Disks begin to overheat and the failure rate goes up significantly.
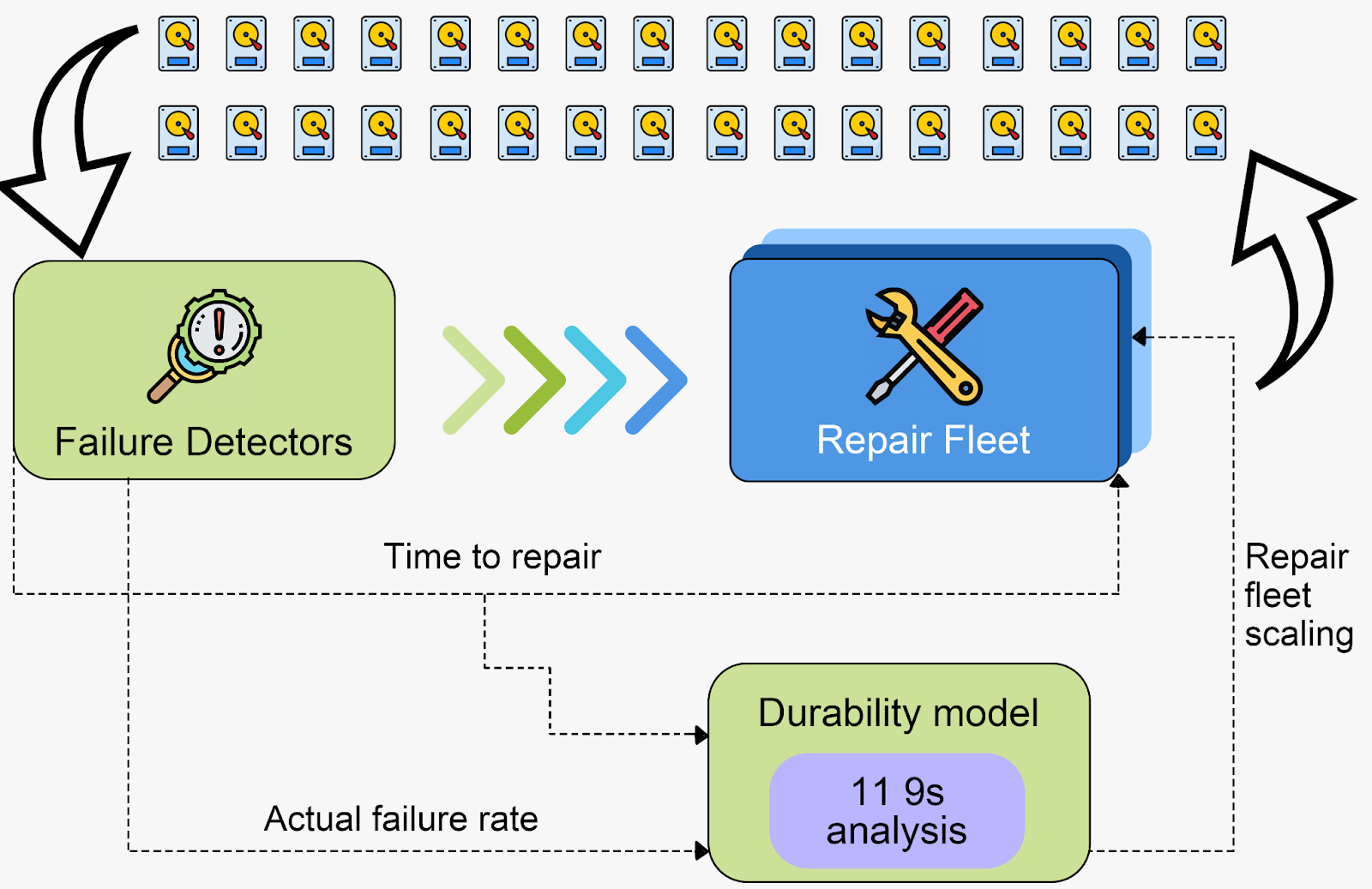
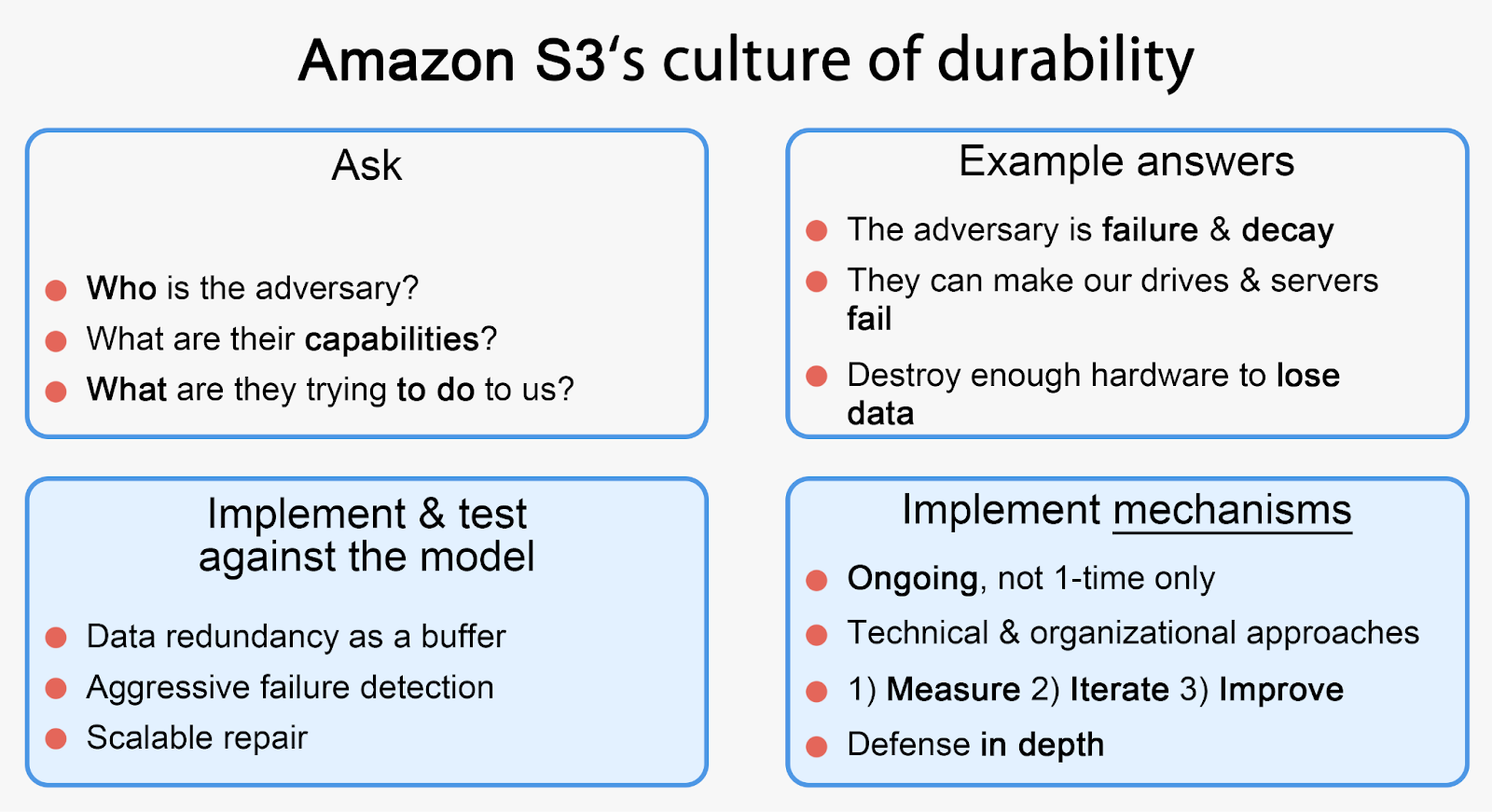
AWS built a continuous self-healing system with detectors that track the failures and scale their repair fleet accordingly.
In the background, a durability model runs analysis to track whether the desired durability is actually met.
The lesson here is that durability cannot be a single snapshot of the system - it is a continuous evaluation.
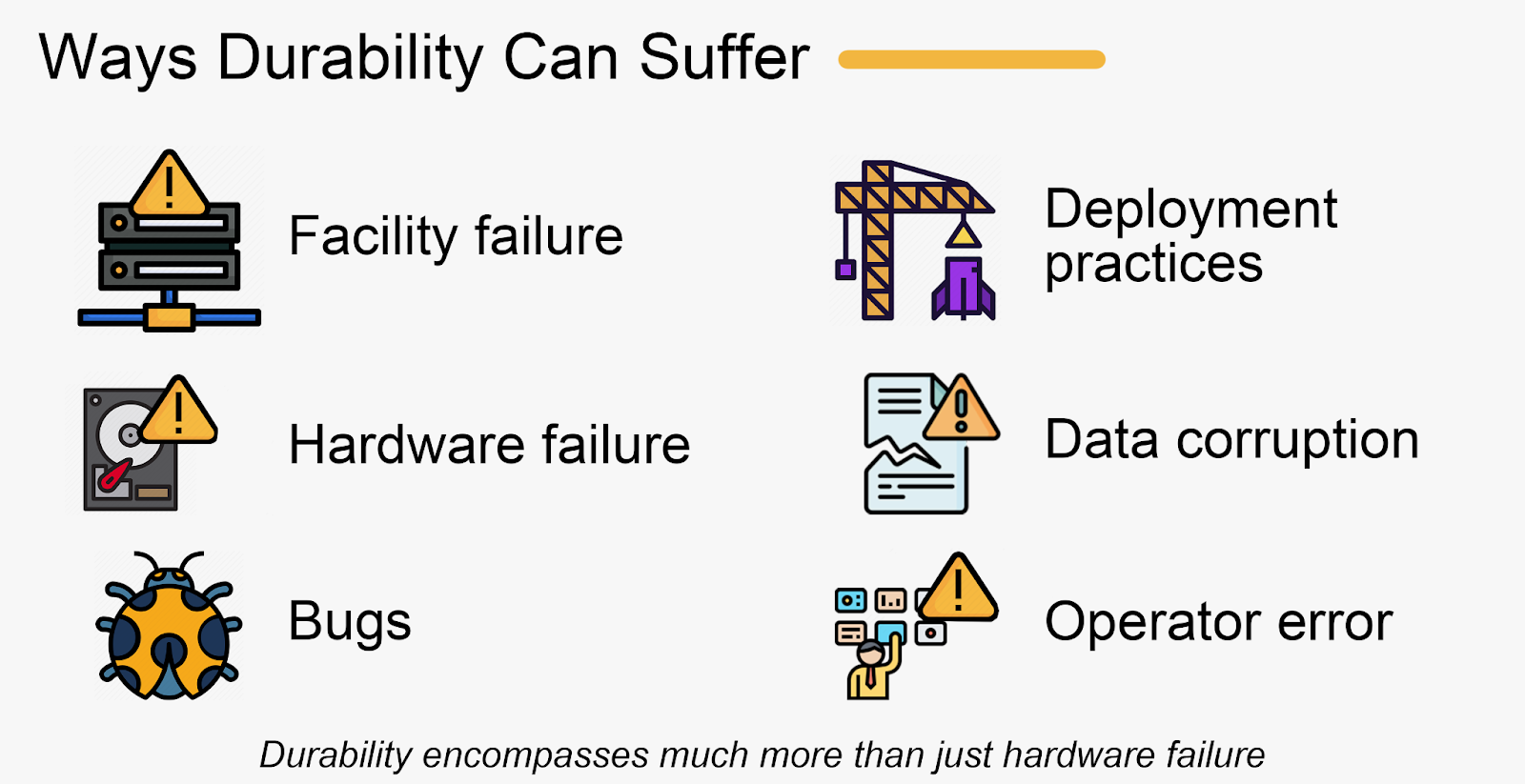
Other Failures
Durability is a large umbrella. Your hardware may work fine but data can still be lost through other means, like deploying a bug that corrupts data, a human operator error deleting data, problematic deployments, or having the network corrupt the bits uploaded by the customer before it reaches your data center.
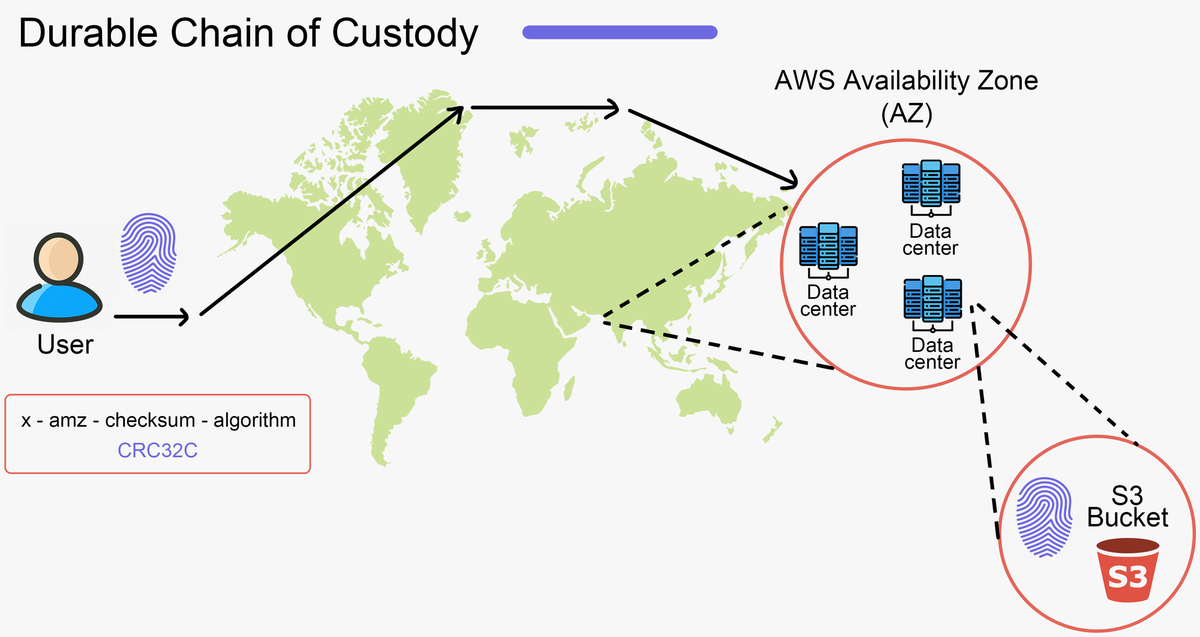
As one example - S3 has implemented what they call a durable chain of custody. To solve the edge case where data can become corrupted before it reaches S3, AWS implemented a checksum in the SDK that’s added as an HTTP Trailer (preventing the need of scanning the data twice) to the request.
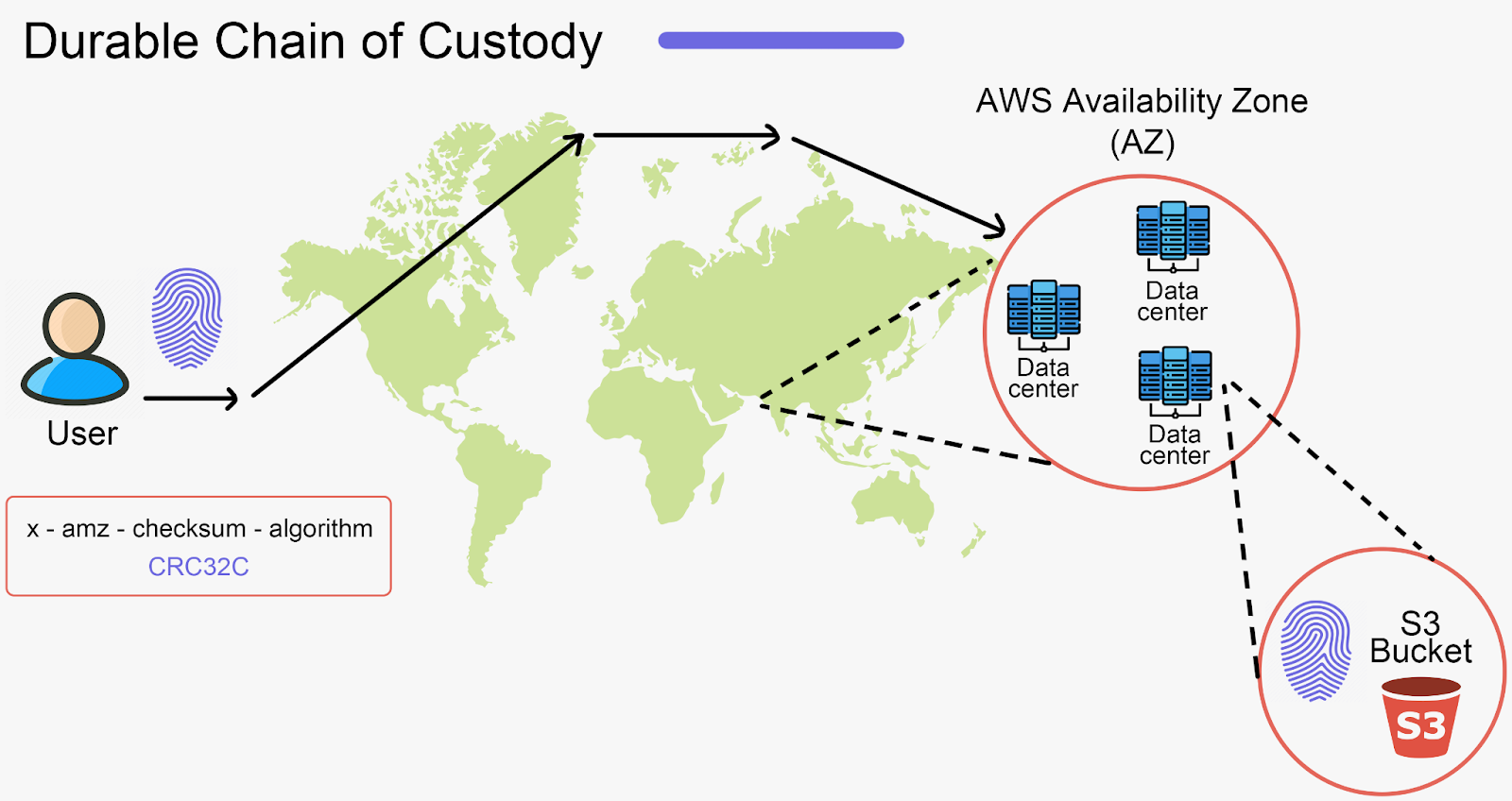
The sheer size of S3 means that any theoretical failure that could be experienced has probably been seen, or will soon be.
Culture
Achieving such a feat of engineers like S3 is as much about social organization as it is about technological innovation.
With new engineers joining and experienced ones leaving, maintaining the same velocity at a growing scale & stakes can be difficult.
AWS aims to automate as much as possible. They have integrated extensive property-based tests iterating through large sets of request patterns as well as lightweight formal verification in their CI/CD pipeline. Both features automated giving engineers confidence in the
AWS have shared that they internally follow a “Durability Threat Model” design approach, borrowed from the popular security threat model. When designing features, they take into account any potential threats to durability and ensure they think critically about mitigations for all of them.
They stress the need to ingrain durability into the organization’s culture and ensure continuous processes that maintain it.
Conclusion
S3 is essentially a massively multi-tenant storage service. It’s a gigantic distributed system consisting of many individually slow nodes that on aggregate allow you to get heaps of data fast.
Through economies of scale, its design makes certain use cases that were previously cost-prohibitive - affordable. Bursty workloads that store a lot of data, stay idle for months and then read everything in a short burst, like genomics, machine learning and self-driving cars, can use S3 without the need to pay the full price of all the drives they need if they had to deploy it themselves. It’s an interesting case study of how scale unlocks cost-effectiveness and makes management easier.
Resources
This blog post was formed by a collection of public resources AWS have shared regarding S3. Here is a short list if you are interested in reading more:


