Dremel: Interactive Analysis of Web-Scale Datasets - Data as a Programming Paradigm


If Google was a boxer then MapReduce would be a probing right hand that sets up the massive left hook that is Dremel, Google's—scalable (thousands of CPUs, petabytes of data, trillions of rows), SQL based, columnar, interactive (results returned in seconds), ad-hoc—analytics system. If Google was a magician then MapReduce would be the shiny thing that distracts the mind while the trick goes unnoticed. I say that because even though Dremel has been around internally at Google since 2006, we have not heard a whisper about it. All we've heard about is MapReduce, clones of which have inspired entire new industries. Tricky.
Dremel, according to Brian Bershad, Director of Engineering at Google, is targeted at solving BigData class problems:
While we all know that systems are huge and will get even huger, the implications of this size on programmability, manageability, power, etc. is hard to comprehend. Alfred noted that the Internet is predicted to be carrying a zetta-byte (1021 bytes) per year in just a few years. And growth in the number of processing elements per chip may give rise to warehouse computers of having 1010 or more processing elements. To use systems at this scale, we need new solutions for storage and computation.
How Dremel deals with BigData is describe in this paper, Dremel: Interactive Analysis of Web-Scale Datasets, which is the usual high quality technical paper from Google on the architecture and ideas behind Dremel. To learn more about the motivation behind Dremel you might want to take a look at The Frontiers of Data Programmability, a slide deck from a Key Note speech given by Dremel paper co-author, Sergey Melnik.
Why is a paper about Dremel out now? I assume it's because Google has released BigQuery, a web service that enables you to do interactive analysis of massively large datasets, which is based on Dremel. To learn more about what Dremel can do from an analytics perspective, taking a look at BigQuery would be a good start.
You may be asking: Why use Dremel when you have MapReduce? I think Kevin McCurley, a Google Research Scientist, answers this nicely:
The first step in research is to form a speculative hypothesis. The real power of Dremel is that you can refine these hypotheses in an interactive mode, constantly poking at massive amounts of data. Once you come up with a plausible hypothesis, you might want to run a more complicated computation on the data, and this is where the power of MapReduce comes in. These tools are complementary, and together they make a toolkit for rapid exploratory data intensive research.
So, Dremel is a higher level of abstraction than MapReduce and it fits as part of an entire data slice and dice stack. Another pancake in the stack is Pregel, a distributed graph processing engine. Dremel can be used against raw data, like log data, or together with MapReduce, where MapReduce is used to select a view of the data for deeper exploration.
Dremel occupies the interactivity niche because MapReduce, at least for Google, isn't tuned to return results in seconds. Compared to MapReduce, Dremel's query latency is two orders of magnitude faster. MapReduce is "slow" because it operates on records spread across a distributed file system comprised of many thousands of nodes. To see why, take an example of search clicks. Whenever you search and click on a link from the results, Google will store all the information it can about your interaction: placement on the page, content around the link, browser type, time stamp, geolocation, cookie info, your ID, query terms, and anything else they can make use of. Think about the hundreds of millions of people clicking on links all day every day. Trillions of records must be stored. This data is stored, in one form or another, in a distributed file system. Since that data is spread across thousands of machines, to run a query requires something like MapReduce, which sends little programs out to the data and aggregates the results through intermediary machines. It's a relatively slow process that requires writing a computer program to process the data. Not the most accessible or interactive of tools.
Instead, with Dremel, you get to write a declarative SQL-like query against data stored in a very efficient for analysis read-only columnar format. It's possible to write queries that analyze billions of rows, terabytes of data, trillions of records—in seconds.
Others think MapReduce is not inherently slow, that's just Google's implementation. The difference is Google has to worry about the entire lifecycle of data, namely handling incredibly high write rates, not just how to query already extracted and loaded data. In the era of BigData, data is partitioned and computation is distributed, bridges must be built to cross that gap.
It's interesting to see how the Google tool-chain seems to realize many of the ideas found in Frontiers of Data Programmability, which talks about a new paradigm where data management is not considered just as a storage service, but as a broadly applicable programming paradigm. In that speech the point is made that the world is full of potential data-driven applications, but it's still too difficult to develop them. So we must:
- Focus on developer productivity
- Broaden the notion of a “database developer” to target the long tail of developers
Productivity can be increased and broadened by using something called Mapping-Driven Data Access:
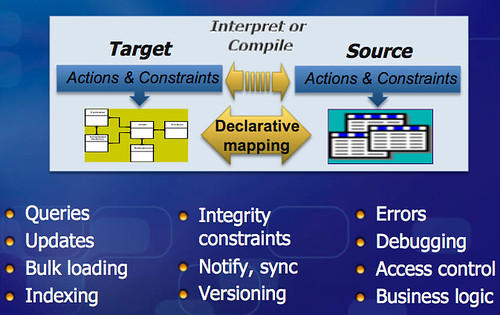
Unsurprisingly Google has created a data as a programming paradigm for their internal use. Some of their stack is also openish. The datastore layer is available through Google App Engine, as is the mapper part of MapReduce. BigQuery opens up the Dremel functionality. The open source version of the data stack is described in Meet the Big Data Equivalent of the LAMP Stack, but there doesn't appear to be a low latency, interactive data analysis equivalent to Dremel...yet. The key insight for me has been to consider data as a programming paradigm and where a tool like Dremel fits in that model.
Related Articles
- Dremel: Interactive Analysis of Web-Scale Datasets on Google Research
- Google’s Dremel – Or, Can MapReduce Itself Handle Fast, Interactive Querying? by Tasso Argyros from Aster Data
- MapReduce Online by lots of people from University of California, Berkeley.
- The Frontiers of Data Programmability by Sergey Melnik
- Product: SciDB - A Science-Oriented DBMS At 100 Petabytes
- Compiling Mappings to Bridge Applications and Databases
- Google I/O 2010 - BigQuery and Prediction APIs
- Running Large Graph Algorithms - Evaluation Of Current State-Of-The-Art And Lessons Learned



