Efficient storage: how we went down from 50 PB to 32 PB

As the Russian rouble exchange rate slumped two years ago, it drove us to think of cutting hardware and hosting costs for the Mail.Ru email service. To find ways of saving money, let’s first take a look at what emails consist of.

Indexes and bodies account for only 15% of the storage size, whereas 85% is taken up by files. So, files (that is attachments) are worth exploring in more detail in terms of optimization. At that time, we didn’t have file deduplication in place, but we estimated that it could shrink the total storage size by 36% since many users receive the same messages, such as price lists from online stores or newsletters from social networks containing images and so on. In this article, I’m going to describe how we implemented a deduplication system under the supervision of Albert Galimov.
Metadata storage
We’re dealing with a stream of files, and we need to quickly recognize a duplicate. An easy solution would be to name files based on their contents. We’re using SHA-1 for this purpose. The initial name of the file is stored in the email itself, so we don’t need to worry about it.
Once a new email arrives, we retrieve the files, compute their hashes and add the result to the email. It’s a necessary step to be able to easily locate the files belonging to a particular email in our future storage when this email is being sent.
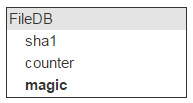
Now, let’s upload a file to our storage and find out if another file with the same hash already exists there. It means we’ll need to store all hashes in memory. Let’s call this storage for hashes FileDB.
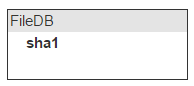
One and the same file can be attached to different emails, so we’ll need a counter that keeps track of all emails containing this file.
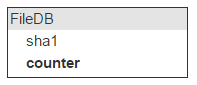
The counter gets incremented with every new uploaded file. About 40% of all files are deleted, so if a user deletes an email that contains files uploaded to the cloud, the counter must be decremented. If it reaches zero, the file can be deleted.
Here we face the first issue: information about an email (indexes) is stored in one system, whereas information about a file is stored in another one. This may lead to an error — for example, consider the following workflow:
- The system receives a request to delete an email.
- The system checks the email indexes.
- The system can see there’s an attachment (SHA-1).
- The system sends a request to delete a file.
- A crash occurs, so the email doesn’t get deleted.
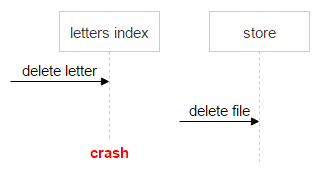
In this case, the email stays in the system, but the counter gets decremented by one. When the system receives a second request to delete this email, the counter gets decremented again — and we may encounter the following situation: the file is still attached to an email, but the counter is already at zero.
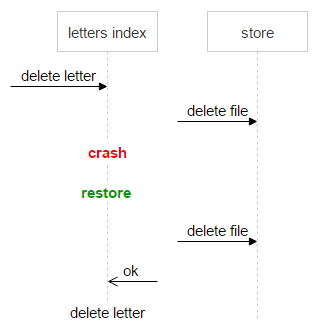
It’s essential not to lose data. We can’t have a situation where a user opens an email and discovers there’s no attachment there. That said, storing some redundant files on disks is no big deal. All we need is a mechanism that unambiguously decides if the counter was correctly set to zero. That’s why we have one more field — magic.
The algorithm is simple. Along with the hash of a file, we store a randomly generated number in an email. All requests to upload or delete a file take this random number into account: in case of an upload request, this number is added to the current value of the magic number; if it’s a delete request, this random number is subtracted from the current value of the magic number.
Thus, if all the emails have incremented and decremented the counter the correct number of times, the magic number will also equal zero. Otherwise, the file must not be deleted.
Let’s consider an example. We have a file named sha1. It’s uploaded once, and the email generates a random (magic) number for it, which is equal to 345.

Then a new email arrives with the same file. It generates its own magic number (123) and uploads the file. The new magic number is added to the current value of the magic number (345), and the counter gets incremented by one. As a result, what we have now in FileDB is the magic number with the value of 468 and the counter set to 2.
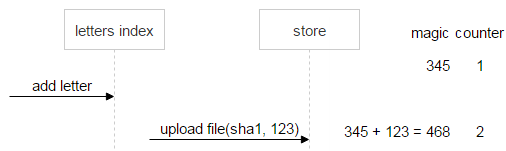
After the user deletes the second email, the magic number generated for this email is subtracted from the current value of the magic number (468), and the counter gets decremented by one.
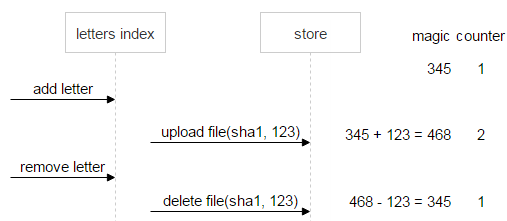
Let’s first take a look at the normal course of events. The user deletes the first email, and the magic number and the counter both become zero. It means the data is consistent, and the file can be deleted.

Now, suppose something goes wrong: the second email sends two delete requests. The counter being equal to zero means there are no more links to the file, but the magic number, which equals 222, signals a problem: the file can’t be deleted until the data is consistent.
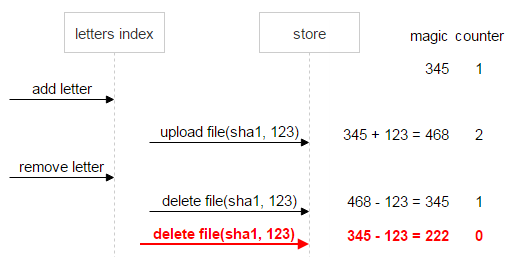
Let’s develop the situation a little more. Suppose the first email also gets deleted. In this case, the magic number (-123) still signals inconsistency.
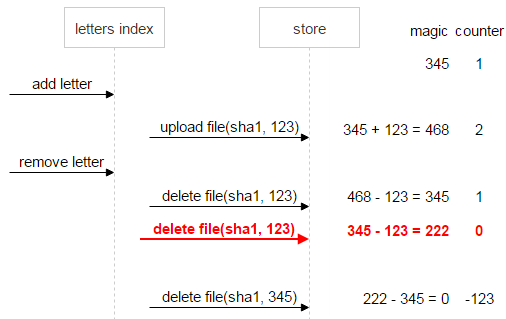
As a safety measure, once the counter becomes zero but the magic number doesn’t (in our case, the magic number is 222, and the counter is zero), the file is assigned the do not delete flag. This way, even if — after a series of deletes and uploads — both the magic number and the counter somehow become zero, we’ll still know that this file is problematic and must not be deleted.
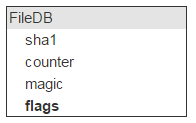
Now back to FileDB. Every entity has a set of flags. Whether you plan to use them or not, you’re going to need them (if, say, a file needs to be marked as undeletable).
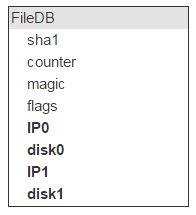
We have all the file attributes, except for where it’s physically located. This place is identified by a server (IP) and a disk. There should be two such servers and two such disks.
But one disk stores lots of files (in our case, about 1,000,000), which means these records will be identified by the same disk pair in FileDB, so it would be wasteful to store this information in FileDB. Let’s put it into a separate table, PairDB, linked to FileDB via a disk pair ID.
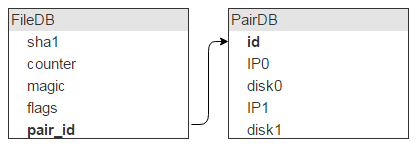
I guess it goes without saying that, apart from a disk pair ID, we’ll also need a flags field. I’ll jump ahead a bit and mention that this field signals whether the disks are locked (say, one disk crashed and the other’s being copied, so no new data can be written to either of them).
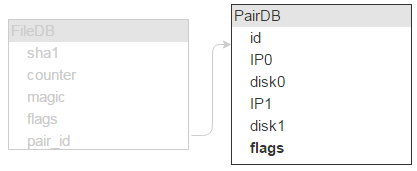
Also, we need to know how much free space each disk has — hence the corresponding fields.
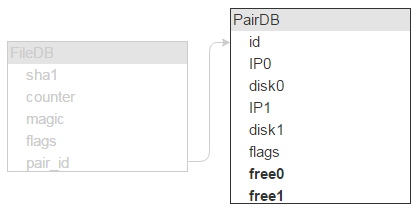
To make sure everything works fast, both FileDB and PairDB must be RAM-resident. We were using Tarantool 1.5, but now the latest version should be used. FileDB has five fields (20, 4, 4, 4 and 4 bytes long), which sums up to 36 bytes. Also, each record has a 16-byte header plus one-byte length pointer per field, which brings the total record size to 57 bytes.

Tarantool allows specifying the minimum allocation size, so memory-associated overheads can be kept close to zero. We’ll be allocating the exact amount of memory needed for one record. We have 12,000,000,000 files.
(57 * 12 * 10⁹) / (1024³) = 637 GB
But that’s not all, we’ll also need an index on the sha1 field, which adds 12 more bytes to the total record size.
(12 * 12 * 10⁹) / (1024³) = 179 GB
All in all, 800 GB of RAM is needed. But let’s not forget about replication, which doubles the amount of RAM required.

If we buy machines with 256 GB of RAM on board, we’ll need eight of them.
We can assess the size of PairDB. The average file size is 1 MB and disk capacity is 1 TB, which allows storing about 1,000,000 files on a single disk, so we need some 28,000 disks. One PairDB record describes two disks. Therefore, PairDB contains 14,000 records — it’s negligible compared to FileDB.
File upload
Now that we got the database structure out of the way, let’s turn to the API for interacting with the system. At first glance, we need the upload and deletemethods. But don’t forget about deduplication: chances are, the file we’re trying to upload is already in the storage, and it doesn’t make sense to upload it a second time. So, the following methods are necessary:
- inc(sha1, magic) — increments the counter. If a file doesn’t exist, returns an error. Let’s recall we also need a magic number that helps prevent incorrect file deletions.
- upload(sha1, magic) — should be called if inc has returned an error, which means this file doesn’t exist and must be uploaded.
- dec(sha1, magic) — called if a user deletes an email. The counter is decremented first.
- GET /sha1 — downloads a file via HTTP.
Let’s take a closer look at what happens during upload. For the daemon that implements this interface, we chose the IProto protocol. Daemons must scale well to any number of machines, so they don’t store states. Suppose we receive a request via a socket:

The command name tells us the header length, so we read the header first. Now, we need to know the length of the origin-len file. It’s necessary to choose a couple of servers to upload it. We just retrieve all the records (a few thousands) from PairDB and use the standard algorithm for finding a needed pair: take a segment with the length equal to the sum of free spaces on all pairs, randomly pick a point on this segment and choose whatever pair this point belongs to.

However, choosing a pair this way is risky. Suppose all our disks are 90% full — and then we add a new empty disk. It’s highly likely that all new files will be uploaded to this disk. To avoid this problem, we should sum not the free space of a disk pair, but the nth root of this free space.
So, we’ve chosen a pair, but our daemon is a streaming one, and if we start uploading a file to the storage, there’s no turning back. That said, before uploading a real file, we upload a small test file first. If the test upload is successful, we read filecontent from the socket and upload it to the storage; otherwise, another pair is chosen. SHA-1 hash can be read on the fly, so it is also checked during upload.
Let’s now examine a file upload from a loader to a chosen disk pair. On machines that contain the disks, we set up Nginx and use the WebDAV protocol. An email arrives. FileDB doesn’t have this file yet, so it needs to be uploaded to a disk pair via a loader.
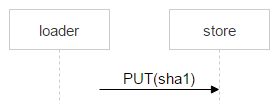
But nothing prevents another user from receiving the same email: suppose two recipients are specified. Remember, FileDB doesn’t have this file yet, so one more loader will be uploading this very file and may pick the same disk pair for upload.
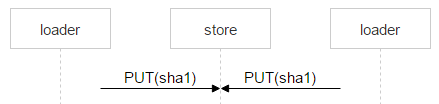
Nginx will likely resolve this situation correctly, but we need to control the whole process, so we’re saving the file with a complex name.
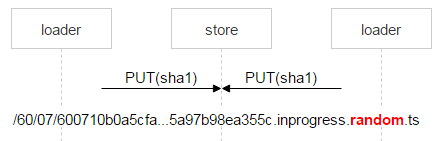
The part of the name in red is where each loader puts a random number. Thus, the two PUT methods don’t overlap and upload two different files. Once Nginx responds with 201 (OK), the first loader performs an atomic MOVE operation, which specifies the final name of the file.
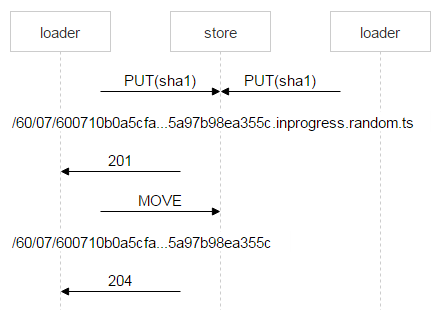
When the second loader is done uploading the file and also performs MOVE, the file will get overwritten, but it’s no big deal since the file is one and the same. Once the file is on the disks, a new record needs to be added to FileDB. Our version of Tarantool is divided into two spaces. We’ve only been using space0 so far.
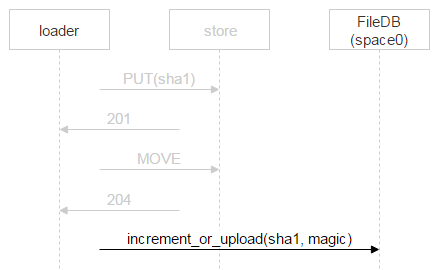
However, instead of simply adding a new record to FileDB, we’re using a stored procedure that either increments the file counter or adds a new record to FileDB. Why so? In the time that has passed since the loader made sure the file doesn’t exist in FileDB, uploaded it and proceeded to add a new record to FileDB, someone else could have already uploaded this file and added the corresponding record. We’ve considered this very case above: two recipients are specified for one email, so two loaders start uploading the file; once the second loader finishes the upload, it’ll also proceed to add a new record to FileDB.
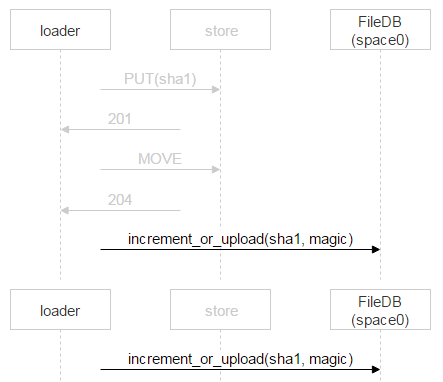
In this case, the second loader just increments the file counter.
Let’s now take a look at the dec method. Our system has two high-priority tasks: reliably write a file to disk and quickly give it back to a client from this disk. Physically deleting a file generates a certain workload and slows down these two tasks. That’s why we perform deletions offline. The dec method itself decrements the counter. If the latter becomes zero, just like the magic number, it means nobody needs the file anymore, so we move the corresponding record from space0 to space1 in Tarantool.
decrement (sha1, magic){
counter--
current_magic –= magic
if (counter == 0 && current_magic == 0){
move(sha1, space1)
}
}
Valkyrie
Each storage has a Valkyrie daemon that monitors data integrity and consistency — and it works with space1. There’s one daemon instance per disk. The daemon iterates over all the files on a disk and checks if space1 contains a record corresponding to a particular file, which would mean this file should be deleted.
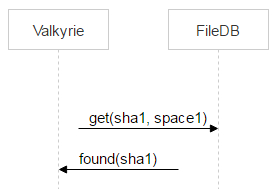
But after the dec method is called and a file is moved to space1, it may take Valkyrie a while to find this file. It means that in the time span between these two events the file may be re-uploaded and thus moved to space0 again.
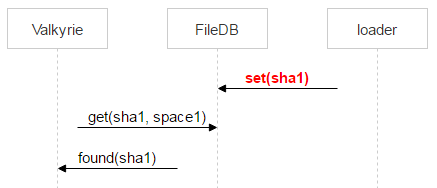
That’s why Valkyrie also checks if a file exists in space0. If this is the case and pair_id of the corresponding record points to a pair of disks this Valkyrie instance is running on, the record is deleted from space1.
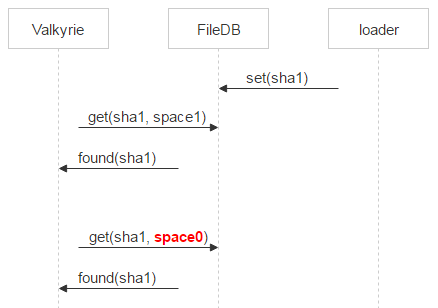
If no record is found in space0, then a file is a potential candidate for deletion. However, between a request to space0 and the physical deletion of a file there’s still a certain time window in which a new record corresponding to this file may appear in space0. To deal with it, we put the file in quarantine.
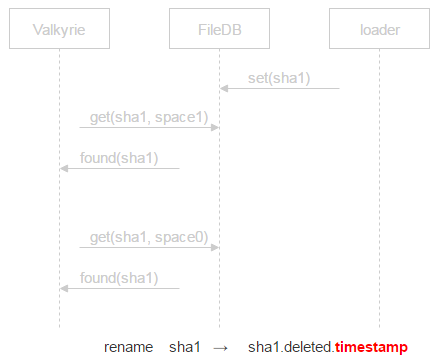
Instead of deleting the file, we append deleted and a timestamp to its name. It means we’ll physically delete the file at timestamp + some time specified in the config file. If a crash occurs and the file is deleted by mistake, the user will come to reclaim it. We’ll be able to restore it and resolve the issue without losing any data.
Now, recall there are two disks, with a Valkyrie instance running on each. The two instances are not synched. Hence the question: when should the record be deleted from space1?
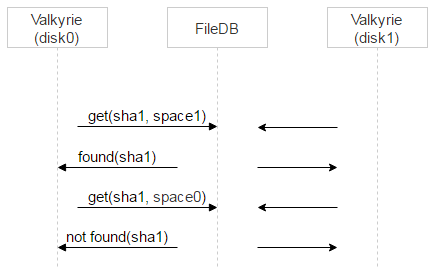
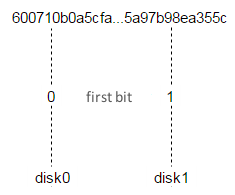
We’ll do two things. First, for the file in question let’s make one of the Valkyrie instances the master. It’s easily done by using the first bit of the file name: if it equals zero, disk0 is the master; otherwise, disk1 is the master.
Now, let’s introduce a processing delay. Recall that when a record sits in space0, it contains the magic field for checking consistency. When the record is moved to space1, this field is not used, so we’ll put there a timestamp corresponding to the time this record appeared in space1. This way, the master Valkyrie instance will be processing records in space1 at once, whereas the slave will be adding some delay to the timestamp and will be processing and deleting records from space1 a little later.
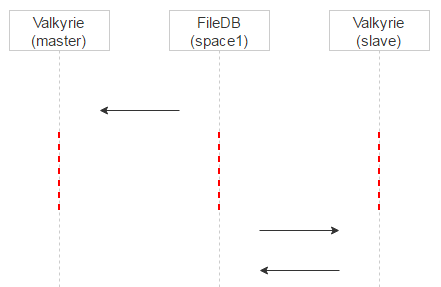
There’s one more advantage to this approach. If a file was mistakenly put in quarantine on the master, it’ll be evident from the log once we query the master. Meanwhile, the client that requested the file will fall back to the slave — and the user will receive the needed file.
So, we have considered the situation where the Valkyrie daemon locates a file named sha1, and this file (being a potential candidate for deletion) has a corresponding record in space1. What other variants are possible?
Suppose a file’s on a disk, but FileDB doesn’t have any corresponding record. If, in the case considered above, the master Valkyrie instance, for some reason, hasn’t been working for some time, it would mean the slave’s had enough time to put the file in quarantine and delete the corresponding record from space1. In this case, we also put the file in quarantine by using sha1.deleted.timestamp.
Another situation: a record exists but points to a different disk pair. This may happen during upload if two recipients are specified for one email. Recall the scheme.
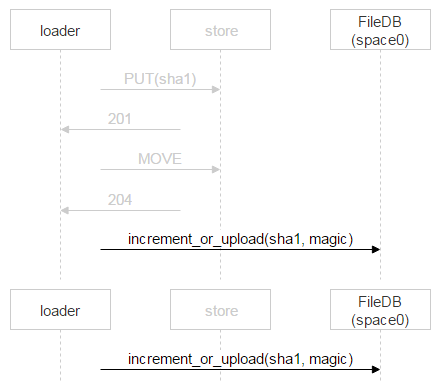
What happens if the second loader uploads the file to a different pair than the first one? It will increment the counter in space0, but the disk pair where the file was uploaded will contain some junk files. What we need to do is make sure these files can be read and they match sha1. If everything’s fine, such files can be deleted at once.
Also, Valkyrie may encounter a file that has been put in quarantine. If the quarantine is over, this file will get deleted.
Now, imagine Valkyrie encounters a good file. It needs to be read from disk, checked for integrity and compared to sha1. Then Valkyrie needs to query the second disk to see if it has this same file. A simple HEAD method is enough here: the daemon running on the second disk will itself check the file integrity. If the file is corrupt on the first disk, it’s immediately copied over from the second disk. If the second disk doesn’t have the file, its copy is uploaded from the first disk.
We’re left with the last situation, which has to do with disk problems. If any problems with a disk are identified in the course of system monitoring, the problematic disk is put in service (read-only) mode, while on the second disk, the UNMOVE operation is run. It effectively distributes all the files on disk two among other disk pairs.
Result
Let’s get back to where we started. Our email storage used to look like this:

We managed to reduce the total size by 18 PB after implementing the new system:

Emails now occupy 32 PB (25% — indexes, 75% — files). Thanks to the 18-petabyte cut, we didn’t have to buy new hardware for quite some time.
P.S. About SHA-1
As of now, there are no known examples of SHA-1 collisions. There exist collision examples for its internal compression function (SHA-1 freestart collision), though. Given 12 billion files, the probability of a hash collision is less than 10^-38.
But let’s assume it’s possible. In this case, when a file is requested by its hash value, we check if it has the correct size and CRC32 checksum that were saved in the indexes of the corresponding email during upload. That is to say, the requested file will be provided if and only if it was uploaded along with this email.



