Evolution of search engines architecture - Algolia New Search Architecture Part 1


What would a totally new search engine architecture look like? Who better than Julien Lemoine, Co-founder & CTO of Algolia, to describe what the future of search will look like. This is the first article in a series.
Search engines, and more generally, information retrieval systems, play a central role in almost all of today’s technical stacks. Information retrieval started in the beginning of computer science. Research accelerated in the early 90s with the introduction of the Text REtrieval Conference (TREC). After more than 30 years of evolution since TREC, search engines continue to grow and evolve, leading to new challenges.
In this article, we look at some key milestones in the evolution of search engine architecture. We also describe the challenges those architectures face today. As you’ll see, we grouped the engines into four architecture categories. This is a simplification, as there are in reality a lot of different engines with various mix of architectures. We did this to focus our attention on the most important characteristics of those architectures.
1. The Inverted Index — the early days of search
In the early days of search engines, the first big revolution was the use of inverted indexes. The word “index” comes from the index that you find at the end of books, which associates a word with the different pages that contain information about the word.
Essentially, a search engine builds a dictionary of every word, where, for each word, it stores and sorts the list of documents that contain the word. Thus, when an end user performs a query with multiple words, the search engine can scan all the words, compute the intersection (documents that contain all the words), and rank them.
All search engines follow this general concept of indexing. Indexing opened a new area of research on how to represent inverted indexes (composed of several inverted lists) in an efficient way. This research led to multiple sets of compression algorithms to efficiently compress and scan those inverted lists containing more and more information.
If you’re interested in the way inverted lists are represented, and the different algorithms that can be used, I recommend reading the book Introduction to Information Retrieval by Christopher D. Manning.
In terms of software architecture, search engines in the early days could be summarized as:
One “indexing process” taking the list of records to compute and producing a binary file representing the inverted index
One “query processing” search process interpreting the binary file to compute the intersection of inverted lists for a particular query
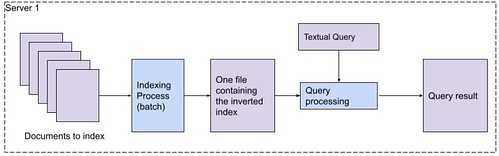
Schema 1: Simple representation of a search architecture (software in blue)
There was no concept of scaling at this stage. This architecture worked well for small amounts of data. The web expansion in the early 90s, where the volume of data increased rapidly, required a scaling of this architecture.
2. Introduction of sharding - parallelization
In the early days of the internet, websites were listed manually in a directory. It became obvious after a few years that a manual list could not continue to deal with the increasing number of websites (according to internet live stats, the number of websites evolved from 130 websites in 1993, to 23,500 in 1995). Thus began the most popular use case for search engines: web search engines.
In 1993, the first web search engines were introduced. They all had to handle a massive increase in the volume of data in the early 90s. In 1995, when Alta Vista was introduced by Digital Equipment Corporation (DEC), it was to illustrate the power of their multi-processor 64-bit Alpha servers. It was one of the first, if not the first, fully parallelized search engine able to index the 10M websites that were listed at the time.
Parallelization is fairly straightforward to apply to search engines :
Instead of having one inverted index with all the documents, you can split the documents in N smaller sets of documents. Each set is called a shard and contains a subset of the initial document set.
Now you can run the indexing of all those shards in parallel, producing N smaller inverted indices instead of one big inverted index.
Finally, you can search in each shard in parallel, producing N queries and aggregating the results to produce the unified result set.

Schema 2: Architecture of a sharded search engine
The introduction of sharding enabled search engines to treat large volumes of data. In the early days of sharding, the number of shards, and by extension the number of servers, were fixed in advance. Many implementations used a mathematical hashing function to allocate one document to one of the N shards. A document was always allocated to the same shard and therefore will never lead to a duplication of records between the shards.
This shard-based search engine architecture can be summarized as:
A fixed number of shards distributed across different servers
A distributed computation of the inverted index (indexing, one thread per shard)
A distributed computation of the search results across the different shards (searching, one thread per shard), finalized by a fast merge of the N results
Some additional comments:
Indexing and searching need to be on the same machine for a given shard (inverted indexes are on local storage).
There are no mechanisms like a distributed commit allowing an indexing operation to be visible on all shards at the same time. For example, if you want to change the list of attributes that you index, or if you want to change your record structure, you will need to create another index, as you cannot do those operations atomically.
New types of problems crop up when the merge function has to deal with non-algebraic aggregation. An example is collapsing results based on field values (for example, a job board where you want to collapse jobs per company name, and then display the top 10 jobs for each category).
This type of architecture was used during the 90s and even early 2000s. Of course, a lot of refinements and improvements were applied to those architectures to make sure they were able to support the load. For example, batch indexing was quickly replaced by incremental builds of data structures to avoid rebuilding the whole inverted list at each pass (similar to databases). Sharding is a key component of search engines to make them scale. Today, it’s part of all search engine architectures in addition to other principles to reach high availability, which we describe in the next section.
3. High Availability and scaling of search - the age of maturity
Search engines need to scale, to manage large volumes of data and numbers of queries. According to Internet World Stats, there were only 16M internet users in 1995, but it grew quickly to reach more than 5B in 2020.
The previous section discussed how to manage large volumes of data with sharding. The next problem is how to manage the large volume of queries, and the associated high-availability of search (that is, supporting hardware failures).
Solving this problem requires introducing replicas of the inverted shards to be able to answer a query from multiple sets of machines. The general principle is straightforward: we use the same architecture as before, but we have N groups of machines able to answer any query instead of having only one group of machines. Each group of machines contains all the shards to answer any query and the number of replicas can grow or shrink depending on the volume of queries.
The complexity of such architecture is mainly in the replication logic and has the same properties and drawbacks as the previous architecture. The complexity of the replication of inverted indices depends on the format of the data structure on disk. Generational data structures are often optimized to minimize the amount of data transferred. If you’re interested in learning more about the different types of data structure on disk, I recommend reading the description of the LevelDB key value store internals; the same concept is often applied to search engines.
When the architecture is hosted in a public cloud environment, the different groups of machines must be hosted on different availability zones to target a better service level objective (SLO). A load balancer component is required to distribute the queries to the different sets of machines, and to retry on error.
This replica-based search engine architecture has exactly the same characteristics as the previous one, with the addition of:
Capacity to handle an infinite amount of queries via replications of the data (increasing capacity takes time, usually hours as it requires copying the inverted indices from the existing machines. This is a good solution only when the increase of traffic can be anticipated.).
In a multi-provider deployment, the copy of the on-disk data-structure is often replaced by a primary/replicas setup where the indexing operations are transfered. The primary shard receives indexing operations, stores them in a LOG. The LOG is consumed locally by the indexing process and the LOG is replicated to one or several locations. The reason for this setup is that it’s usually faster to replicate the indexing operations instead of the binary files, as the inter-provider bandwidth can be the bottleneck when transferring large binary files.
4. High Availability of indexing and elasticity - the business critical area
Given the importance of high-availability of search for all online businesses, it’s crucial to tolerate hardware failure without any business impact. Architectures must manage hardware failure so that it remains transparent to the end user.
The previously discussed architecture introduced the possibility to accept hardware failure without impacting the ability to search. New use cases like Snapshat make indexing a critical piece of the system: Snapshot’s information is ephemeral and needs to be searchable quickly, so the indexing also requires high availability. High availability of indexing was introduced to search engines via different architectures that all have in common that at least two machines can build one shard. The most famous architecture is Elasticsearch, introduced in 2010 with high availability of search and indexing. The most significant innovation Elasticsearch introduced was not the high availability of indexing; it was the elasticity. Elasticity is the ability to add machines to an existing instance and move shards between machines. It was a significant evolution of search engine architectures!
The introduction of high availability of indexing is an evolution of the primary/replicas architecture described in the previous section. Each shard has one primary, thus ensuring a unique ordering of indexing jobs and N replicas. It’s important to ensure that each replica will process the jobs in the same order to converge on the exact same state.
Suppose the machine hosting the primary shard is down. In that case, one replica is elected as the new primary via a leader election algorithm to ensure a globally consistent state.
To illustrate this, let's take the following example:
One index containing four shards.
Factor-three replication (three copies of each shard: one primary shard and two replica shards).
Distributed over four machines. Each machine contains one primary shard and two replicas.
When an indexing operation comes to the system, a routing phase routes the operation to the correct primary shard. This routing process can be performed by any one of the three machines (so you can target any machine to perform the indexing operation). The indexing process of the primary shard will then replicate the indexing operation on every shard, resulting in the application of the indexing operation on three machines in parallel (schema 3)
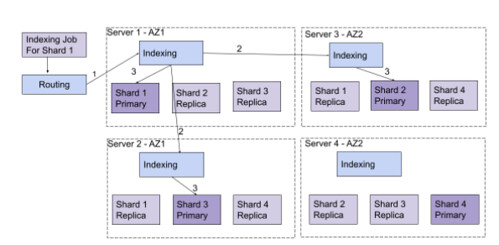
Schema 3: Example of an indexing operation for the shard 1 in the case of one index with four shards, a replication factor of three.
A load balancer selects one of the three copies of each shard to perform the query. The three copies allow three times more queries per second than with a single copy of the shard. In this setup, the machines are spread over two availability zones (AZ). Each AZ runs on as many different physical infrastructures as possible inside a cloud-provider region. The three copies are stored in a way where the first copy is 100% hosted on the first AZ, the second copy is 100% hosted on the second AZ, and the third copy is split between the two AZ. Schema 4 illustrates one query sent to the copy that is 100% hosted on the first AZ.
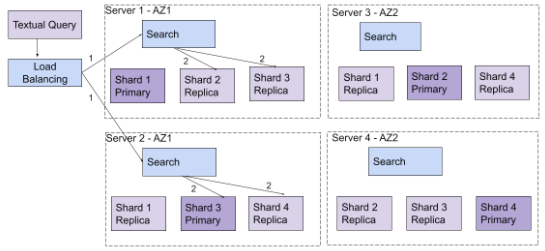
Schema 4: Example of a query processed by the replica, hosted fully on the first AZ
On each machine, the indexing and the search processes can access all the shards stored locally. The elasticity comes from adding and removing machines to an existing setup. For example, it’s possible to add a new machine to the previous example. The shards would then automatically be moved to the new machine to ensure you have an even-loaded spread on each machine. Depending on the allocation algorithm of your search engine, you can end up with a result similar to schema 5.
The number of shards is static in this architecture. Defining the number of shards is a critical element of your configuration, as it defines the ability to scale and your underlying performance. In this example, the number of shards is not big enough to use all the CPU resources on all machines. Still, you can increase the number of replicas to support more queries per second and use all resources, which is the standard way to scale.
It’s also important not to have too many shards. The goal is to process all of them in parallel. If you do not have enough CPU threads for all shards at the same time, it will negatively impact your response time.
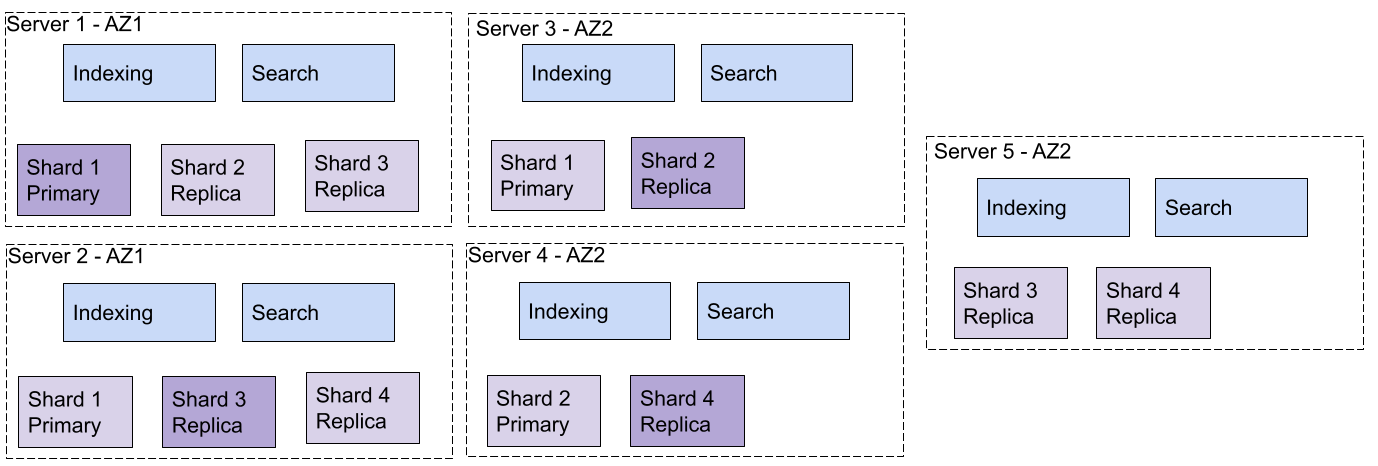
Schema 5: Example after the addition of a new machine in the second availability zone
There are two types of failures that this architecture can support while keeping all shards available:
One machine is down. This would have no impact on the ability to index and search. There are enough replicas to ensure we can still perform a search query. The leader election will elect one of the two replicas as master. The only impact would be to reduce the search capacity because fewer CPU threads are available for search.
One AZ is down. In this case, the search would still be available with less capacity to scale. Indexing would be unavailable for two shards as only one of the three copies remains, which prevents a leader election.
This type of architecture is today’s state of the art in search architecture, with the following characteristics:
Ability to scale in terms of data depending on the number of shards you configured
Ability to scale in terms of volume of queries by adding new replicas
Ability to tolerate hardware failure and availability zone (AZ) failure to some extent
5. Next steps — the current challenges of search engines
The latest generation of architecture is now more than ten years old! Since then, fast-growing marketplaces and SaaS applications have put many constraints on those architectures. It’s now time to design the next generation of architecture for the next ten years, solving the following challenges:
Sub-minute addition/removal of machines. We already know how to add/remove machines from an existing instance. However, we need to go one step further to support dynamic scalability: the ability to add or remove machines in under a minute and the ability to temporarily handle the increased traffic before the new machine is available! Search engines today are more than ever required to anticipate growth, and scale their infrastructure for spikes of traffic. Total dynamic scalability will allow everyone to be more cost efficient while unlocking new creative usage of search engines. For example, one big marketplace presented the idea of a flash sale on their store leveraging the search engine: customers have to find a cheap product hidden in their large catalogue. You can imagine the flood of queries their search engine received just after they sent an email to millions of users, their last event generated 160 times more traffic than their average daily traffic. But the same happens every time some search event goes viral, which is usually impossible to plan for in advance.
A dynamic number of shards. The number of shards is a critical factor of performance and ability to scale. To be optimum, this number would need to change often. The next generation of search engine architectures will allow you to change this number dynamically. It will also need to go further, where the engine tunes this number automatically to ensure you always have the optimum performance and ability to scale.
Separation of search and indexing. Scaling both in terms of volume of queries and volume of data is the most demanding situation for a search engine. It’s a problem for many use cases like marketplaces. In such a situation, the cost of infrastructure can quickly become prohibitive if you perform the indexing for each replica. Increasing the search or indexing capacity impacts the resource consumption of the existing machines. For example, when the system is already loaded, scaling one of the subsystems can make the whole system collapse. The next generation will have high availability of search and indexing while doing only a one-time indexing job for each shard. It will scale indexing and search separately, avoiding any negative impact of indexing on search.
Leveraging the evolution of network bandwidth. Having a 1Gbps link between machines was the norm ten years ago. Today, you have access to up to 100 Gbps network links in a public cloud provider, and it will become more and more the norm. The CPU and storage improvements were much more limited in the same period than the 100X factor on the bandwidth! Leveraging such network architecture requires a very different data transfer usage with more parallelization. It’s an essential factor that needs to be the core of the search engine architecture to scale efficiently.
Native multi-tenant optimization. It’s widespread for SaaS applications to host multiple users inside a single index. It would be way too expensive to have a dedicated index for each customer. While this is a great strategy, it’s today pretty much impossible to deliver guaranteed performance for the biggest users. The new search architecture needs to evolve to make sure it can still appear to be one index from a logical perspective. Still, the most significant customers have dedicated shards and resources to ensure guaranteed performance and avoid any impacts from other customers.
We identified those five unique challenges in 2019 when we started the work on our next-generation architecture. We've developed a unique architecture aimed at solving those five challenges, and we have our first customers testing it. The following articles will give more details about how this architecture works and how we solve those five unique challenges of search.



