Homegrown master-master replication for a NoSQL database
Many of you may have already heard about the high performance of the Tarantool DBMS, about its rich toolset and certain features. Say, it has a really cool on-disk storage engine called Vinyl, and it knows how to work with JSON documents. However, most articles out there tend to overlook one crucial thing: usually, Tarantool is regarded simply as storage, whereas its killer feature is the possibility of writing code inside it, which makes working with your data extremely effective. If you’d like to know how igorcoding and I built a system almost entirely inside Tarantool, read on.
If you’ve ever used the Mail.Ru email service, you probably know that it allows collecting emails from other accounts. If the OAuth protocol is supported, we don’t need to ask a user for third-party service credentials to do that — we can use OAuth tokens instead. Besides, Mail.Ru Group has lots of projects that require authorization via third-party services and need users’ OAuth tokens to work with certain applications. That’s why we decided to build a service for storing and updating tokens.
I guess everybody knows what an OAuth token looks like. To refresh your memory, it’s a structure consisting of 3–4 fields:
{
“token_type” : “bearer”,
“access_token” : “XXXXXX”,
“refresh_token” : “YYYYYY”,
“expires_in” : 3600
}
- access_token — allows you to perform an action, obtain user data, download a user’s friend list and so on;
- refresh_token — lets you get a new access_token unlimited number of times;
- expires_in — token expiration timestamp or any other predefined date. If your access_token expires, you won’t be able to access the required resource.
Now let’s take a look at the approximate architecture of our service. Imagine there are some frontends that can write tokens to our service and read them from there. There’s also a separate entity called a refresher. Its main purpose is to obtain new access tokens from an OAuth provider once they expire.
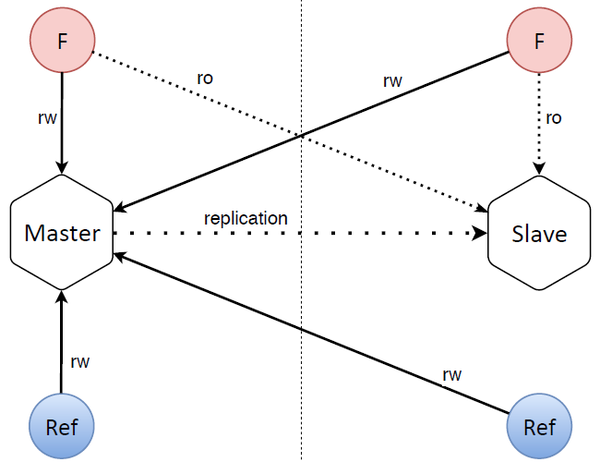
The database is structured quite simply as well. There are two database nodes (master and slave) separated by a vertical dotted line in the image above, which is meant to signify they’re situated in two data centers: one containing the master with its frontend and refresher, the other containing the slave with its frontend and refresher that accesses the master.
What difficulties we faced
The main problem had to do with the token lifetime (one hour). After taking a closer look at the project, one might think: “10 million records that need to be refreshed within an hour — is it really a high-load service? If we divide one by the other, we’ll get about 3,000 RPS.” However, the going gets tough once something stops being refreshed due to database maintenance or failure, or even server failure (anything can happen!). The thing is, if our service (that is master database) stays down for 15 minutes for some reason, it results in 25% outage (a quarter of our tokens becomes invalid and can’t be used anymore). In case of a 30-minute downtime, half the data isn’t refreshed. In an hour, there won’t be a single valid token. Imagine the database has been down for one hour, we got it up and running again — and now all the 10 million tokens need to be updated really fast. How’s that for a high-load service!
I must say that at first everything was working quite smoothly, but two years later we extended the logic, added extra indices and started implementing some auxiliary logic… long story short, Tarantool’s run out of CPU resources. Although every resource is depletable, it did take us aback.
Luckily, system administrators helped us out by installing the most powerful CPU they had in stock, which allowed us to grow over the next 6 months. In the meantime, we had to come up with a solution to this problem. At that time, we learned about a new version of Tarantool (our system was written with Tarantool 1.5, which is hardly used outside Mail.Ru Group). Tarantool 1.6 boasted master-master replication, so this gave us the following idea: why not have a database copy in each of the three data centers connected with master-master replication? That sounded like a great plan.
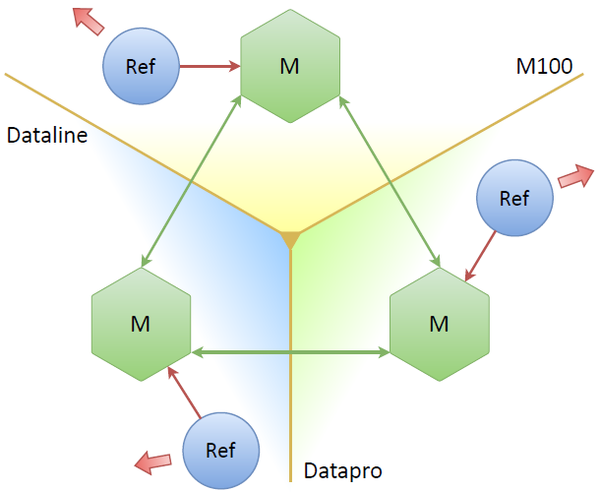
Three masters, three data centers, three refreshers, each interacting with its own master. If one or even two masters are down, everything should still work, right? What pitfalls does this scheme have? The main issue is that we’re effectively tripling the number of requests to an OAuth provider: we refresh almost the same tokens as many times as there are replicas. That won’t do. The most straightforward workaround is to somehow make the nodes decide themselves who a leader is, meaning that tokens stored only on that node get refreshed.
Electing a leader
There exist numerous consensus-solving algorithms. One of them is called Paxos. Quite complicated stuff. We were unable to figure out how to make something simple out of it, so we decided to use Raft instead. Raft is a very easy-to-understand algorithm, in which a leader is elected based on whether it’s possible to communicate with it and remains a leader until a new one is elected due to connection failure or some other reason. Here’s how we implemented it:
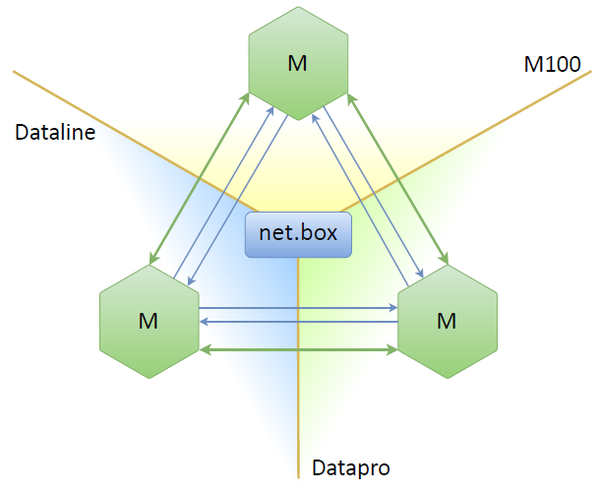
Tarantool doesn’t have either Raft or Paxos out of the box. But we can take a built-in net.box module, which allows connecting nodes into a full mesh (that is each node is connected to all other nodes), and simply implement Raft’s leader election process over these connections. Each node will consequently be either a leader or a follower, or it won’t be seeing both the leader and the follower.
If you think implementing Raft is difficult, here’s Lua code that does exactly that:
local r = self.pool.call(self.FUNC.request_vote,
self.term, self.uuid)
self._vote_count = self:count_votes(r)if self._vote_count > self._nodes_count / 2 then
log.info(“[raft-srv] node %d won elections”, self.id)
self:_set_state(self.S.LEADER)
self:_set_leader({ id=self.id, uuid=self.uuid })
self._vote_count = 0
self:stop_election_timer()
self:start_heartbeater()
else
log.info(“[raft-srv] node %d lost elections”, self.id)
self:_set_state(self.S.IDLE)
self:_set_leader(msgpack.NULL)
self._vote_count = 0
self:start_election_timer()
end
Here we’re sending requests to remote servers (other Tarantool replicas) and counting the number of votes received from each node. If we have a quorum, we’re elected a leader and start sending heartbeats — notifications to other nodes that we’re still alive. If we lose the election, we initiate another one, and after some time we’ll be able to vote or get elected.
Once we have a quorum and elect a leader, we can direct our refreshers to all the nodes but instruct them to work only with the leader.
This way we normalize the traffic: since tasks are given out by a single node, each refresher gets approximately a third. This setup allows us to lose any of the masters, which would result in another election and the refreshers switching to another node. However, as in any distributed system, there are certain issues associated with a quorum.
“Abandoned” node
If connectivity between data centers is lost, it’s necessary to have some mechanism in place that can keep the whole system functioning properly, as well as a mechanism for restoring system integrity. Raft successfully does that.
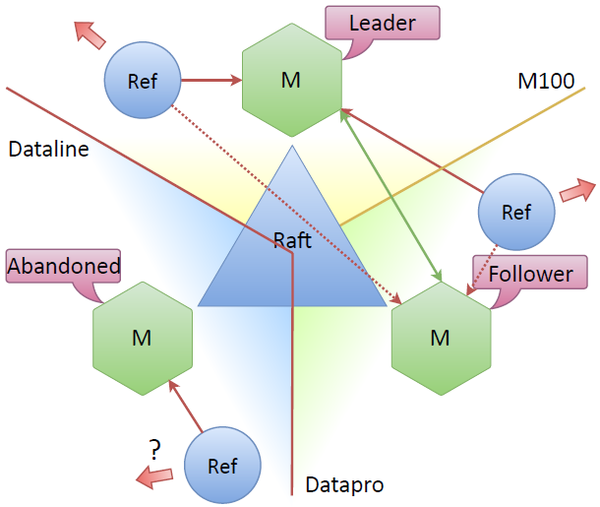
Suppose the Dataline data center connection is down. Then the node located there becomes “abandoned”, that is it can’t see the other nodes. The remaining nodes in the cluster can see that the node is lost, which causes another election, and a new cluster node — say the upper one — is elected a leader. The system remains functional, since there’s still a consensus between the nodes (that is more than half of them can still see each other).
The main question is what happens to the refresher associated with the disconnected data center. The Raft specification doesn’t have a separate name for such a node. Normally, a node without a quorum and not communicating with a leader remains idle. However, it can establish a network connection and update tokens on its own. Tokens are usually updated in connectivity mode, but maybe it’s possible to update them with a refresher connected to an “abandoned” node? At first we weren’t sure it makes much sense to do it. Wouldn’t it result in superfluous updates?
We needed to figure it out in the process of implementing our system. The first thought was not to make updates: we have a consensus, a quorum, and if we lose any member, updates shouldn’t take place. But then we had another idea. Let’s take a look at master-master replication in Tarantool. Suppose there exist two master nodes and a variable (key) X with a value of 1. We simultaneously assign new values to this variable on each node: 2 on one, and 3 on the other. Then the nodes exchange their replication logs (that is values of the X variable). Consistency-wise, such an implementation of master-master replication is terrible (no offence to Tarantool developers).
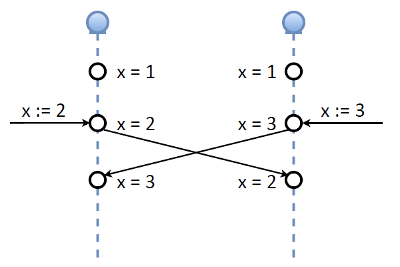
If we need strict consistency, this won’t work. However, recall our OAuth token that consists of two important elements:
- refresh token, with essentially an unlimited lifetime;
- access token, which is valid for 1 hour.
Our refresher has a refresh function that can obtain any number of access tokens from a refresh token. Once issued, they will all remain valid for 1 hour.
Let’s consider the following scenario: two follower nodes are interacting with a leader; they refresh their tokens and receive the first access token. This access token gets replicated, so now everybody has it. But then the connection is lost, so one of the followers becomes an “abandoned” node: it doesn’t have a quorum and can’t see both the leader and other followers. However, we allow our refresher to update the tokens sitting on the “abandoned” node. If that node doesn’t have a network connection, the whole scheme won’t work. In case of a simple network split, though, the refresher will be able to do its job.
Once the network split is over and the “abandoned” node rejoins the cluster, either another election or data exchange takes place. Note that the second and the third tokens are equally “good.”
After the original cluster membership is restored, the next update will occur only on one node, and it’ll get replicated. In other words, when the cluster is split, its parts perform updates independently, but once it’s complete again, data consistency is restored. Normally, it takes N / 2 + 1 active nodes (for a 3-node cluster, this number is 2) to keep a cluster functional. In our case, though, even one active cluster is enough: it’ll send as many external requests as necessary.
To reiterate, we’ve discussed the issue of a growing number of requests. During a network split or node downtime, we can afford to have a single active node, which we’ll be updating it as usual. In case of an absolute split (that is when a cluster is divided into the maximum number of nodes, each with a network connection), we’re tripling the number of requests to an OAuth provider, as mentioned above. But since this event is relatively short-lived, it’s not that bad: we don’t expect to work in split mode all the time. Normally, the system is in a quorum and has connectivity, with all the nodes up and running.
Sharding
One issue still remains: we’ve hit the CPU limit. An obvious solution is sharding.
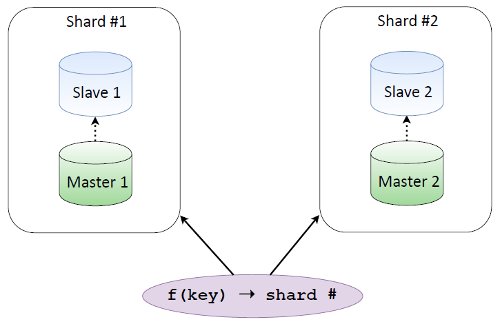
Let’s say we have two database shards, each being replicated, and there’s a function that, given some key, helps us figure out which shard has the required data. If we shard by email, addresses are stored partly on one shard and partly on the other, and we always know where our data is.
There are two approaches to sharding. The first is client sharding. We pick a consistent sharding function that returns a shard number, for example, CRC32, Guava, Sumbur. This function is implemented in the same way on all the clients. One clear advantage of this approach is that the database doesn’t know anything about sharding: you have your database that works as usual, and then there’s sharding somewhere around the corner.
However, there’s a serious drawback to this approach as well. To begin with, clients are pretty thick. If you want to make a new one, you need to add the sharding logic to it. But the gravest issue here is that some clients may be using one schema, while others are using a totally different one. And the database itself isn’t aware that sharding is performed differently.
We chose another approach — intra-database sharding. In this case, the database code grows more complex, but we can use simple clients as a trade-off. Each client connecting to the database is routed to any node, where a special function calculates which node should be contacted and which one should be yielded control. As mentioned, clients become simpler at the expense of the increased database complexity, but the database is fully responsible for its data in this case. Besides, the most difficult thing out there is resharding, which is much easier to do when the database is responsible for its data, as compared to when you have a bunch of clients that you can’t even update.
How did we implement it?
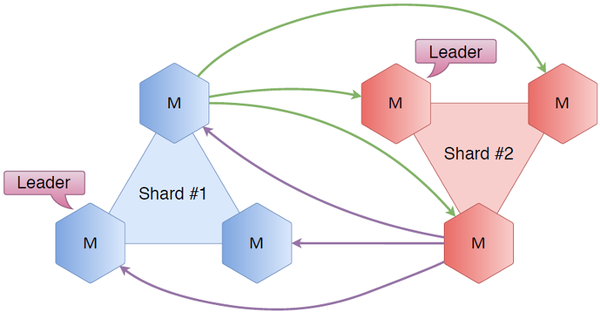
Hexagons represent Tarantool instances. Let’s take three nodes and call them shard 1, and another three-node cluster shard 2. If we connect all the nodes to each other, what does it give us? We have Raft in place, so for each cluster we know its status and which server is a leader or a follower. Given the inter-cluster connection, we also know the state of the other shard (for example, its leader and followers). Generally speaking, we always know where to direct a user accessing the first shard if the first shard’s not what they need.
Let’s consider a couple of simple examples.
Suppose a user requests a key residing on the first shard. Their request is received by one of the nodes in the first shard, and since this node knows who the leader is, it reroutes the request to the shard leader that, in its turn, obtains or writes the key and returns a response to the user.
Another scenario: a user’s request arrives to the same node in the first shard, but the requested key sits on the second shard. This situation is handled the same: the first shard knows who the leader is in the second shard, so the request is forwarded and processed there, and a response is returned to the user.
It’s a pretty straightforward scheme, but it has its downsides. The greatest issue is the number of connections. In our two-shard case, where each node is connected to all the other nodes, there are 6 * 5 = 30 connections. Add one more three-node shard — and this number soars to 72 connections. Isn’t that too many?
Here’s how we solved this problem: we just added a couple of Tarantool instances — but we called them proxies instead of shards or databases — to handle all the sharding: they calculate keys and locate shard leaders. Raft clusters, on the other hand, remain self-contained and work only within a shard. When a user comes to a proxy, it calculates which shard they need, and if they need a leader, redirects the user accordingly; if not, the user is redirected to any node within this shard.
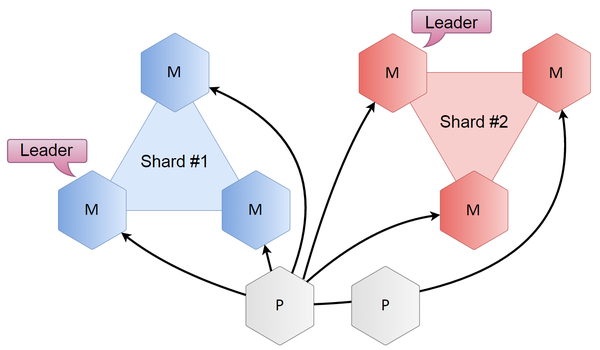
The resulting complexity is linear and depends on the number of nodes. Given three shards of three nodes each, the number of connections is several times smaller.
The proxy scheme was designed with further scaling (when the number of shards is greater than 2) in mind. With just two shards, the number of connections is the same, but as the number of shards grows, the decrease in the number of connections becomes significant. The list of shards is stored in a Lua configuration file, so to obtain a new list, we just need to reload the code — and everything’s OK.
To sum up, we started with master-master replication, implemented Raft, then added sharding and proxies. And we got is a single block, a cluster, so our scheme now looks quite simple.
What’s left is our frontends that only write or read tokens. There are refreshers that update tokens, get the refresh token and pass it to an OAuth provider, and then write a new access token.
We mentioned that we have some auxiliary logic that depleted our CPU resources. Let’s move it to another cluster.
This auxiliary logic has mainly to do with address books. If there exists a user’s token, there exists this user’s corresponding address book that has the same amount of data as there are tokens. Not to run out of the CPU resources on one machine, we obviously need the same cluster with replication. We just added a bunch of refreshers that update address books (this is a rarer task, so address books aren’t updated along with tokens)
As a result, by combining two such clusters we got this relatively simple overall structure:
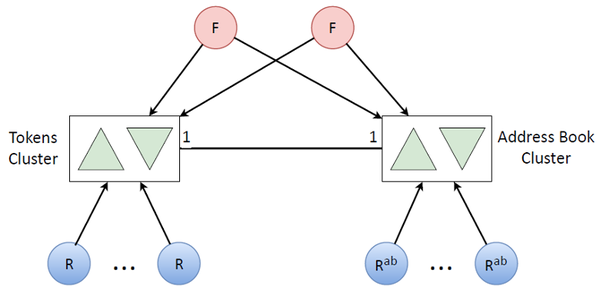
Token refresh queue
Why did we need to implement our own queue when we could’ve used something standard? It’s all about our token update model. Once issued, a token is valid for one hour. When the expiration date is near, the token needs to be updated, and it must be done before a certain point in time.
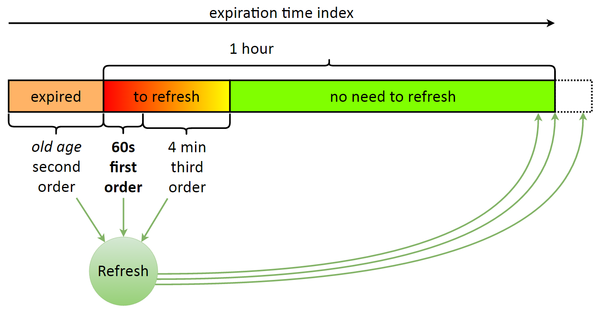
Suppose an outage occurs, but we have a bunch of expired tokens. While we’re updating them, some more tokens will expire. Sure enough, we’ll catch up eventually, but wouldn’t it be better to first update the ones about to expire (in 60 seconds) and then use the remaining resources to update the expired ones? The lowest priority is assigned to tokens with a longer remaining lifetime (4–5 minutes until expiration).
Implementing this logic with some third-party software wouldn’t be easy. Tarantool makes it a breeze, though. Let’s take a look at a simple scheme: we have a tuple that stores data in Tarantool, and it has some ID with a primary key set on it. To make a queue that we need, we’re just adding two fields: status (state of a queued token) and time (expiration time or some other predefined one).
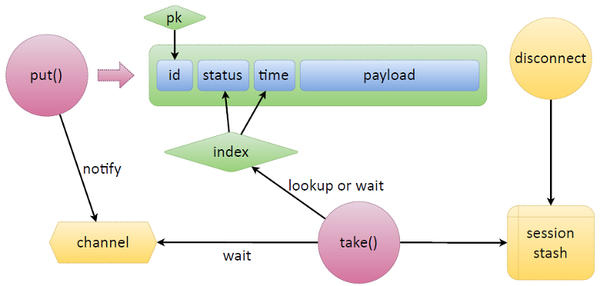
Now let’s consider two main functions of a queue — put and take. What put does is writes new data. We’re given some payload, and put sets the status and time itself and then writes the data, that is creates a new tuple.
As for take, it creates an index-based iterator and starts picking those tasks that await resolution (those with the ready status) and checking if it’s time to take them or if they’ve already expired. If there are no tasks, take switches to wait mode. Apart from the built-in Lua stuff, Tarantool has so-called channels, which are essentially inter-fiber synchronization primitives. Any fiber can create a channel and say, “I’m waiting over here.” Any other fiber can wake up this channel and send messages to it.
The function waiting for something — for tasks to be released, for appointed time or for something else — creates a channel, labels it appropriately, puts it someplace and listens on it afterward. If we’re given a token that urgently needs to be updated, put will send a notification to this channel, and take will pick up the task.
Tarantool has one special feature: if a token gets accidentally released or is picked up by take for refresh or if somebody just takes a task, it’s possible to keep track of client disconnects. We associate each connection with tasks assigned to it and keep these mappings in the session stash. Suppose the refresh process fails due to a network split, and we don’t know whether it will update the token and write it back to the database. So a disconnect event is triggered, searches the session stash for all the tasks associated with the failed process, and automatically releases them. After that any released task can use the same channel to send a message to another put that will quickly pick and process this task.
In fact, implementing this scheme doesn’t require too much code:
function put(data)
local t = box.space.queue:auto_increment({
‘r’, -- [[ status ]]
util.time(), -- [[ time ]]
data -- [[ any payload ]]
}) return t
endfunction take(timeout)
local start_time = util.time()
local q_ind = box.space.tokens.index.queue
local _,t while true do
local it = util.iter(q_ind, {‘r’}, {iterator = box.index.GE})
_,t = it()
if t and t[F.tokens.status] ~= ‘t’ then
break
end local left = (start_time + timeout) — util.time()
if left <= 0 then return end
t = q:wait(left)
if t then break end
end
t = q:taken(t)
return t
endfunction queue:taken(task)
local sid = box.session.id()
if self._consumers[sid] == nil then
self._consumers[sid] = {}
end
local k = task[self.f_id]
local t = self:set_status(k, ‘t’) self._consumers[sid][k] = {util.time(), box.session.peer(sid), t}
self._taken[k] = sid
return t
endfunction on_disconnect()
local sid = box.session.id
local now = util.time() if self._consumers[sid] then
local consumers = self._consumers[sid]
for k, rec in pairs(consumers) do
time, peer, task = unpack(rec) local v = box.space[self.space].index[self.index_primary]:get({k}) if v and v[self.f_status] == ‘t’ then
v = self:release(v[self.f_id])
end
end
self._consumers[sid] = nil
end
end
Put simply takes all the data a user wants to enqueue and writes it to a space, sets the status and the current time if it’s a simple indexed FIFO queue, and returns the task.
Things get a little bit more involved with take, but it’s still quite straightforward: we’re creating an iterator and waiting for new tasks to pick up. The taken function simply marks a task as taken, but more importantly, it also remembers what tasks are taken by what processes. The on_disconnect function allows releasing a certain connection or all the tasks taken by a certain user.
Are there any alternatives?
Of course, there are. We could’ve used any database. But, regardless of our choice, we would’ve had to create a queue for working with an external system, with updates and so on. We can’t simply update tokens on demand, as it would generate unpredictable workload. We need to keep our system alive anyway, but then we would’ve had to enqueue postponed tasks and needed to ensure consistency between the database and the queue. We would’ve been forced to implement a fault-tolerant queue with a quorum anyway. Besides, if we put our data both in RAM and in a queue that, given our workload, would likely need to be in-memory, we’d be consuming more resources.
In our case, the database stores tokens, and we’re paying only 7 bytes for the queue logic — extra 7 bytes per tuple, and we have the queue logic! We would’ve paid much more for any other queue implementation, up to double the memory capacity.
Wrapping it up
First we solved the issue of outage, which came up pretty often. Deploying the system described above rid us of this nuisance.
Sharding enabled us to scale horizontally. Then we lowered the number of connections from quadratic to linear and improved the queue logic for our business task: update all we still can update in case of delays. These delays aren’t always our fault: Google, Microsoft or other services may make changes to their OAuth providers, which results in lots of unupdated tokens on our side.
Perform computations inside the database, close to data — it’s very convenient, efficient, scalable and flexible. Tarantool’s really cool!
Thanks for reading this article.



