Moving HPC to the Cloud: A Guide for 2020


This is a guest post by Limor Maayan-Wainstein, a senior technical writer with 10 years of experience writing about cybersecurity, big data, cloud computing, web development, and more.
High performance computing (HPC) enables you to solve complex problems which cannot be solved by regular computing. Traditionally, HPC solutions provided mainly supercomputers. Today, HPC is typically a mix of resources, including supercomputing and virtualized and bare metal servers, platforms for management, sharing and integration capabilities, and more. When coupled with the cloud, HPC is made more affordable, accessible, efficient and shareable.
What Is HPC?
HPC is a collection of computing resources that provides solutions to complex problems, which personal computers cannot solve. Supercomputers provide some HPC services, making supercomputing a special case of HPC systems.
The Cray supercomputer is a classic example of this phenomenon. Twenty or thirty years ago, the first Cray computers were supercomputers. Today, Cray Computer launched HPC and it is a family of supercomputers that provide high-performance computing using distributed processing technology.
Supercomputers are highly specialized, and cost millions of dollars to deploy and run. However, HPC is a low-cost system that uses legacy hardware, putting it within reach of many more businesses.
Benefits of HPC in the Cloud
The adoption of cloud computing by HPC users is due to several factors. Today's public cloud hardware dramatically improves on legacy on-premises infrastructure, especially for use cases requiring graphical processing units (GPUs). Cloud HPC users can take advantage of auto-scaling and orchestration, development tools, big data analytics, management software and other advanced features of the public cloud.
Here are several key benefits of using HPC in the cloud.
Easily share HPC data with your existing cloud workflows
Unlike on-premises HPC systems, cloud-based HPC systems make data and metadata easy to share. This enables collaboration and supports automated workflows. For example, users can search for previous jobs with similar properties to avoid re-analysis, or easily feed HPC data into analytics and AI systems.
End-to-end management and traceability
Cloud-based HPC provides a well-designed environment that can be integrated across the entire business stack. Traceability is important for companies to measure profits and eliminate uncertainty. The HPC application and related hardware environments are highly distributed. This makes it difficult for engineers and IT teams to perform continuous end-to-end monitoring. Modeling, analysis, data regression, and post-processing visualization are all considered complex tasks.
In cloud-based HPC, each part of the process is performed on a specific, isolated hardware and software stack. Tiered cloud storage aligns storage and optimizes performance based on process performance. This approach enables organizations to dramatically reduce the number of manual scripts required and increase the level of abstraction, to align HPC workloads with their hardware capabilities.
Increased efficiency of HPC services
HPC provides a strong ecosystem that promotes collaboration. HPC enables networks of value across social, transportation, media and supply networks. Today companies have customers and engineering centers around the world, complicating their supply chain. HPC must promote cross-site collaboration, bring IT resources closer to each user, and address issues of relevance and data fragmentation.
Legacy HPC architectures were not designed to efficiently exchange information between remote systems. By contrast, cloud-based systems easily allow data sharing and collaboration across corporate boundaries. Cloud computing infrastructure opens up new opportunities to use HPC that local systems cannot solve.
HPC in the Cloud: A Comparison
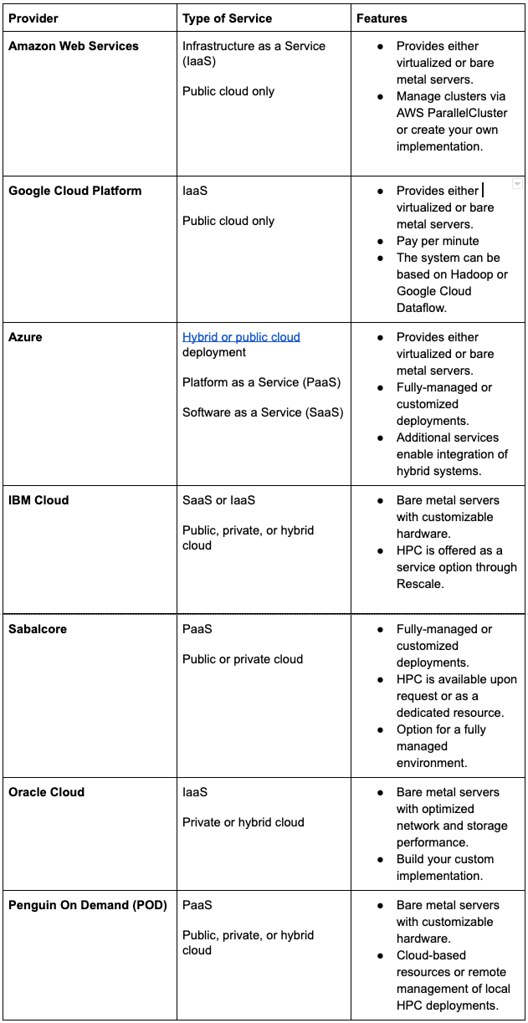
HPC on the Big Three Clouds: Deployment Considerations
As you plan to move your HPC workloads to one of the public clouds, you should consider the different architectural requirements imposed by each environment, and how to leverage the different options and services they offer.
Considerations for HPC on AWS
Choose the required storage space
Amazon Elastic Block Store (EBS) offers continuous block storage, which can temporarily store your reads. You can leverage EBS for HPC workloads that require memory workloads and genomics workloads. EBS provides high IOPS optimization, enabled by default on C5 and M5 instances, which helps reduce network contention, improve application performance, and improve stability.
For workloads with high I/O requirements, AWS has developed a parallel file system optimized for HPC, called Amazon FSx for Lustre. FSX for Lustre provides scalable performance and a fixed latency of less than 1 millisecond. Each TB provides speeds of 200MB/s and can be expanded to hundreds of GB/s and millions of IOPS. AWS provides HPC storage volumes for object storage (S3), file system storage (EFS), and file storage (Amazon Glacier).
Automation and orchestration
Typically, both schedulers and batch management are required to run an AWS HPC instance. Users can use their existing systems, or develop scheduling and batch management using AWS services, for example, using SQS and CloudWatch, or the spot instance market.
Another alternative is using AWS Batch, a managed task scheduler that dynamically organizes IT resources, which can plan, schedule and run batch jobs on HPC cloud resources.
AWS also provides ParallelClusters, which allows you to run virtual HPC clusters in minutes. You can automate your entire HPC workload by creating CloudFormation templates. Considerations for HPC on Azure
Considerations for HPC on Azure
Spread Out Your Deployments
When planning HPC deployments, limit their size. There are no hard limits, but Azure recommends more than 500 virtual machines or 1000 cores per deployment. Exceeding this number can result in loss of active instances, implementation delays, and IP swapping issues.
Using the HPC Client Utility Remote Connection
When users connect to the root node on a remote desktop, performance can be slow. This often occurs when the root node is already too busy. To avoid this situation, log your user into the system using the HPC Pack Client Utility, instead of Remote Desktop Service (RDS).
Continuous monitoring for high productivity
Azure Monitor enables you to not only monitor deployments, but you can also take advantage of SQL Server and HPC managed services. This is especially true for large deployments. Instead of regularly checking your performance and monitoring it frequently, you can disable the collection of performance indicators.
Considerations for HPC on Google Cloud
Parallel or NFS file system option
Google cloud provides two primary storage options:
- NFS-based solutions are the easiest shared storage option to implement and are ideal for applications that do not have high I/O requirements, and do not need to share much data between computing nodes.
- Parallel file systems based on the POSIX standard, commonly used in message passing interface (MPI) applications. Parallel file systems, such as open source Luster, can transfer data to large supercomputers and serve thousands of nodes. Lustre enables parallel I/O for many applications. You can use Lustre for I/O and data libraries like HDF5 and NetCDF.
Compact placement policy
Location policies can help you determine where virtual machines (VMs) are located in your data center. The compact deployment strategy provides a low latency topology for hosting virtual machines in the same Availability Zone. Use the API to create a maximum of twenty two custom virtual machines (C2), but they need to be physically adjacent. For more than twenty two instances (over 660 physical cores), set up several deployments.
Disable Hyper-Threading
MPI applications can potentially improve performance, if you disable hyperthreading on guest operating systems. Google Cloud hyper-threading provides two virtual cores (VCPUs) for each physical core. In many I/O-intensive computing tasks, over-processing can dramatically improve application performance. For computing tasks in which two virtual cores are computationally connected, overprocessing affects the overall performance of the application.
Conclusion
Moving HPC to the cloud has proven highly successful. For one, as a shared solution, HPC becomes affordable, enabling more organizations and startups to leverage these resources and advance their research and development programs. In addition, the integration with cloud resources makes it easy to use additional resources, such as automation and orchestration. The user-friendly interface and managed services offered by cloud vendors also make cloud HPC accessible to a wide range of users.



