Paper: A Provably Correct Scalable Concurrent Skip List

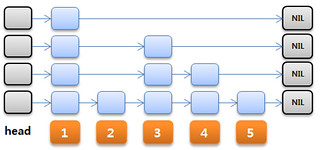
In MemSQL Architecture we learned one of the core strategies MemSQL uses to achieve their need for speed is lock-free skip lists. Skip lists are used to efficiently handle range queries. Making the skip-lists lock-free helps eliminate contention and make writes fast.
If this all sounds a little pie-in-the-sky then here's a very good paper on the subject that might help make it clearer: A Provably Correct Scalable Concurrent Skip List.
From the abstract:
We propose a new concurrent skip list algorithm distinguished by a combination of simplicity and scalability. The algorithm employs optimistic synchronization, searching without acquiring locks, followed by short lock-based validation before adding or removing nodes. It also logically removes an item before physically unlinking it. Unlike some other concurrent skip list algorithms, this algorithm preserves the skiplist properties at all times, which facilitates reasoning about its correctness. Experimental evidence shows that this algorithm performs as well as the best previously known algorithm under most circumstances.



