Paper: Hyder - Scaling Out without Partitioning

Partitioning is what differentiates scaling-out from scaling-up, isn't it? I thought so too until I read Pat Helland's blog post on Hyder, a research database at Microsoft, in which the database is the log, no partitioning is required, and the database is multi-versioned. Not much is available on Hyder. There's the excellent summary post from Mr. Helland and these documents: Scaling Out without Partitioning and Scaling Out without Partitioning - Hyder Update by Phil Bernstein and Colin Reid of Microsoft.
The idea behind Hyder as summarized by Pat Helland (see his blog for the full post):
In Hyder, the database is the log, no partitioning is required, and the database is multi-versioned. Hyder runs in the App process with a simple high-performance programming model and no need for client server. This avoids the expense of RPC. Hyder leverages some new hardware assumptions. I/Os are now cheap and abundant. Raw flash (not SSDs – raw flash) offers at least 10^4 more IOPS/GB than HDD. This allows for dramatic changes in usage patterns. We have cheap and high performance data center networks. Large and cheap 64-bit addressable memories are available. Also, with many-core servers, computation can be squandered and Hyder leverages that abundant computation to keep a consistent view of the data as it changes.
The Hyder system has individual nodes and a shared flash storage which holds a log. Appending a record to the log involves a send to the log controller and a response with the location in the log into which the record was appended. In this fashion, many servers can be pushing records into the log and they are allocated a location by the log controller. It turns out that this simple centralized function of assigning a log location on append will adjudicate any conflicts (as we shall see later).
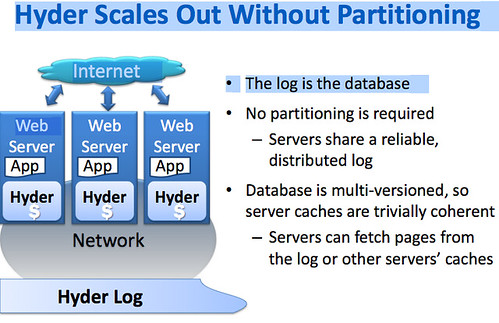
The Hyder stack comprises a persistent programming language like LING or SQL, an optimistic transaction protocol, and a multi-versioned binary search tree to represent the database state. The Hyder database is stored in a log but it IS a binary tree. So you can think of the database as a binary tree that is kept in the log and you find data by climbing the tree through the log.
The Binary Tree is multi-versioned. You do a copy-on-write creating new nodes and replace nodes up to the root. The transaction commits when the copy-on-write makes it up to the root of the tree.
For transaction execution, each server has a cache of the last committed state. That cache is going to be close to the latest and greatest state since each server is constantly replaying the log to keep the local state accurate [recall the assumption that there are lots of cores per server and it’s OK to spend cycles from the extra cores]. So, each transaction running in a single server reads a snapshot and generates an intention log record. The transaction gets a pointer to the snapshot and generates an intention log record. The server generates updates locally appending them to the log (recall that an append is sent to the log controller which returns the log-id with its placement in the log). Updates are copy-on-write climbing up the binary tree to the root.
Log updates get broadcast to all the servers – everyone sees the log. Changes to the log are only done by appending to the log. New records and their addresses are broadcast to all servers. In this fashion, each server can reconstruct the tail of the log.



