Stuff The Internet Says On Scalability For March 9th, 2018

Hey, it's HighScalability time:
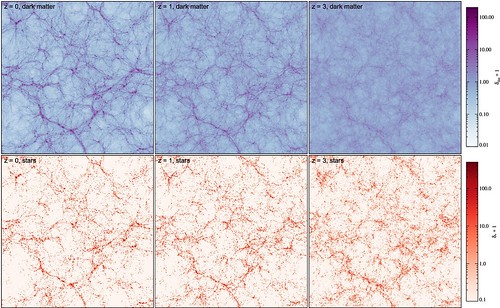
The largest simulation of the cosmos ever run finally produces a universe similar to our own. All it required was 24,000 processors, more than two months, and it produced 500 terabytes of data.
If you like this sort of Stuff then please support me on Patreon. And I'd appreciate if you would recommend my new book—Explain the Cloud Like I'm 10—to anyone who needs to understand the cloud (who doesn't?). I think they'll learn a lot, even if they're already familiar with the basics.
- 72 bits: Google's new quantum computer; 50,000: sites infected with cryptocurrency mining malware; $40 billion: purchases via talking tubes by 2022; $12,000: value of 1 million YouTube views a month; $15 billion: Netflix 2018 revenue;
- Quotable Quotes:
- @ValaAfshar: Jeff Bezos, CEO @amazon: I very frequently get the question: "what's going to change in he next 10 years?" I almost never get the question: "what's not going to change in the next 10 years?" I submit to you that the second question is actually the more important of the two.
- @svscarpino: Sharing and consuming fake news is highly concentrated. 0.1% of Twitter accounts share 80% of the fake news and 1% share 100%!!! Incredible results by @davidlazer and collaborators. #complenet18
- Tim Wu: An unwelcome consequence of living in a world where everything is “easy” is that the only skill that matters is the ability to multitask. At the extreme, we don’t actually do anything; we only arrange what will be done, which is a flimsy basis for a life.
- pauldjohnston: if the CGI execution model was horizontally scalable, fault tolerant, spread across availability zones, stable and with a managed infrastructure and a secure and certified API Gateway in front of it with DDoS protection built in... and someone else was looking after it for me... (Not to mention all the other stuff AWS provides) then yes it's exactly like cgi-bin was back in the day.
- Abu Sebastian: Computational memory: A memory unit that performs certain computational tasks in place.
- @MIT_CSAIL: The world's first online transaction happened over 45 years ago between MIT & Stanford students - and it was for weed
- @cloud_opinion: don't forget "good enough" often wins. Fargate will be seen by many as good enough. Will k8s continue to be adopted?. yes. But, Fargate will reduce TAM for k8s distro companies.
- @kylewillett: After finally getting hands-on with #akka streams to implement a solution to what would normally be a tricky async problem, I can now agree with the praise I've heard - an awesome api and great tool to have in the toolbox.
- @awscloud: Amazon Redshift uses machine learning to automatically hop short queries to an express queue for fast processing.
- @postwait: Look, I'm gonna be the last one to defend InfluxDB... but for f*ck's sake don't use units per day in computing. Please, please, please.... use per second numbers so you don't mislead or attempt to look large.
- @hypervisible: Researchers build AI to identify gang members. When asked about potential misuses, presenter (a computer scientist at Harvard) says "I'm just an engineer."
- @Jason: 4/We should also allow folks to build apartments and homes with NO PARKING spaces BUT with carports capable of getting ridesharing cars and people off streets during drop off and pickup. Right now we force folks to build X spots per Y residents, which is dated.
- antiviral: OK... so they [Facebook] are saying they don't use your microphone to target ads. But how about precisely enumerating how FB uses your microphone?
- @KentonVarda: Google doesn't let its employees look at your private data, but it definitely lets its AI look at your data. As AI gets closer to human intelligence, at what point will Google need to apply the same restrictions to AI as it applies to human employees?
- @arshia__: DEVS: documentation isn't important! also it's easy! MANAGERS: documentation won't get you promoted! INSTRUCTORS: documentation won't get you marks! when in reality the past 3 technical problems I've had to deal with have been because of bad or no documentation 😐
- whalesalad: A lot of folks here in the comments are confusing a channel system with actors. Channels can help with actor communication, but they are not the same thing. If you want to succeed with actors, they need to really be a thing and you ideally want to abstract away the communication mechanism. This is what Erlang/Elixir have done and it’s beautiful. You don’t really spend a lot of time thinking about channels and buffers... you just talk to processes that are living things.
- @cloudera: How does @jeffdean see the role of #DataScientists evolving? Collaboration between humans and automated #MachineLearning tools will continue to be foundational and complimentary. #AutoML will apply, scale and give insight into human ideas. #StrataData #GoogleAI
- Krish: Kubernetes could become Xen
- cik: We use Collins as a Configuration Management Database, Ansible for automation, Terraform + a bunch of homebrew for orchestration, Packet for multi-cloud (and hypervisor) image creation and maintenance, powered by Ansible. Every since thing is committed to a series of bitbucket repositories. We connect Ansible and Collins through ansible-cmdb, then tie the entire thing to our ticketing systems ServiceNOW and Jira Service Desk, and finally, ensure we have history tracking with Slack. Whether it's bare-metal, virtualized, para-virtualized, dockerized, mixed-mode, or cloud - we 100% do this all the time. There is not a single change across any environment, that isn't fully tracked, fully reproducible, fully auditable, and fully automated.
- @tim: At #netflixlabs press event today. Product chief Greg Peters says Netflix's 117m account members watched on 450m devices (TV/phone etc) & with 300m user profiles. "Essentially we create 300m different versions of Netflix... No two of those experiences are exactly the same."
- @danluu: A creator of the C++ STL says they might've used more cache-friendly data structures if HP Labs had the budget to buy HP PA-RISC machines?
- 21: Mr Taleb argues convincingly that the spectacular collapse in 1998 of Long-Term Capital Management was caused by the inability of the hedge fund's managers to see a world that lay outside their flawed models. And yet those models are still widely used today.
- Daniel Lemire: if you have dense bitstreams, the SIMD code is about twice as fast. The gains are higher when the bitmaps are very dense. However, the gains disappear when the bit stream is sparse…
- faitswulff: TL;DR - tried Firebase for a mobile app recently, it was equal parts "wow, this is cool" and "wow, this is stupid"
- eitally: The scaling isn't the problem that requires large engineering teams. It's partner integrations, compliance work, and all sorts of things that are extremely non-core.
- @RogerSuffling: Monitor tells you if the system is working: Observability informs you what's wrong @PierreVincent @qconlondon #QConLondon
- cryptonector: My take is and has been for a long time that the right solution is something like a key/value store on the backend + a SQLite4-style frontend, with a Lustre-style lock manage co-located with the k/v backend, and key/value pairs distributed by key ranges. This is... a lot like Spanner I think, though I don't know if Spanner uses a DLM like Lustre or if it does something else for synchronization.
- This way you get the scalability benefits of a key/value store with all the benefits of a SQL, and you get always-consistent, and even ACID semantics (depending on how many failures there are at once and how many you design to).
- zie: In other words, put your documentation tools right alongside your normal workflow, so you have a decent chance of actually using it, keeping it up to date, and having others on your team(s) also use it. We put our docs in the repo's right alongside the code that manages the infrastructure.. in plain text. It's versioned. We don't publish it anywhere, it's just in the repo, but then we spend most of our time in editors messing in that repo.
- @GovInslee: Today we make history: Washington will be the first state in the nation to preserve the open internet with our own #NetNeutrality law. The open internet lives on for Washingtonians.
- teh_klev: I've said this before, and I'll say it again. AirBNB is a blight on rural areas (I can speak to this because I reside in rural Scotland) where affordable rental properties are simply disappearing from the market. These properties are barely fully booked during the summer months or holiday/peak seasons, and are empty for weeks at a time in the winter and off-seasons. This is such a waste and hugely frustrating for folks who live and work in these communities trying to find accomodation.
- Picnic: looking to the future and our move towards a microservices architecture, we turn towards technologies and methodologies that can aid us in the composition of reactive services and streaming pipelines, to form a truly reactive technology platform.
- guiambros: Additionally, adding support for advertising at scale is a massively complex effort, and usually invisible to outsiders. It's one thing to build a WhatsApp-type app, focusing 100% of your energy on the core messaging functionality itself, and little else. It's a completely different thing to build a revenue-generating business that needs to connect with an entire ecosystem of advertisers, ad servers, video servers, programmatic ad exchanges, analytics, brand safety, reporting, billing systems, and a lot more. And we're not even talking about services. There's another big layer of complexity to keep those services running 24x7 (well beyond just SREs), ensuring ads are running properly, campaigns are fully optimized, advertisers are happy with what they're getting, etc.
- GitHub: Over the past year we have deployed additional transit to our facilities. We’ve more than doubled our transit capacity during that time, which has allowed us to withstand certain volumetric attacks without impact to users. We’re continuing to deploy additional transit capacity and develop robust peering relationships across a diverse set of exchanges. Even still, attacks like this sometimes require the help of partners with larger transit networks to provide blocking and filtering.
- agar: Even at its simplest level, a VR headset with 6 degrees of freedom is two monitors that must remain in absolute synchronization while also returning positional information to the CPU. Oculus (and Steam, via SteamVR) engineers a plethora of low-level code to reduce latency and add features. It's not just a monitor, but a whole set of SDKs, APIs, devices, and drivers. For the Rift, the hand controllers are wireless input devices refreshing at 1,000Hz; the sensors (to know where you are in the room) are USB devices with tight 60 fps synchronization to LEDs on the headset; there is a custom audio stack with spacialized audio and ambisonic sound; video needs specialized warping to correct lens distortion, interpolate frames, and maintain a 90 fps image, etc. All this needs to work across AMD and Nvidia, in Unity, Unreal, or any custom game engine. It's not off-the-shelf driver stuff.
- srazzaque: A while into the project, my team and I were responsible for delivering a subcomponent within the system. We did so with extreme prejudice to only using actors at the very edges and entry points where a bit of asynchronicity was required. But everything within the service boundary was just plain old Java. This was the easiest to understand and maintain part of the system, as attested by another team who we handed over the entire codebase to. Guess which part had the least bugs? Most extensible?
- Errata Security: Like many servers, memcached listens to local IP address 127.0.0.1 for local administration. By listening only on the local IP address, remote people cannot talk to the server. However, this process is often buggy, and you end up listening on either 0.0.0.0 (all interfaces) or on one of the external interfaces. There's a common Linux network stack issue where this keeps happening, like trying to get VMs connected to the network. I forget the exact details, but the point is that lots of servers that intend to listen only on 127.0.0.1 end up listening on external interfaces instead. It's not a good security barrier. Thus, there are lots of memcached servers listening on their control port (11211) on external interfaces.
- An interesting architecture. Keep a runnable version of every version of your website ever. How Netlify’s deploying and routing infrastructure works.
- We’ve built Netlify’s core around Merkle trees, the same structures used in Git, ZFS file systems, and blockchain technology. A Merkle tree is a structure where each node is labeled with the cryptographic hash of the labels of all the nodes under it
- We use cloud file storage to persist content. But, we use content addressable references rather than file names as identifiers. We don’t store files with the name jquery-3–31.js , we hash its content and we use it as the file name. This gives strong guarantees to we serve the same content regardless the file name.
- Each deploy calculates those hashes and generates a new tree based in the content that changed, and content that we already have stored. If you only change one file, we will only upload one file.
- Each deploy is immutable. We always serve the contents of the same tree under a domain. When we finish processing new deploys, we only swap the tree to serve. Having immutable trees also prevents us from showing mixed content.
- These immutable guarantees are also the base for many other features. The first one is atomic and instant rollbacks. Immutability doesn’t prevent us from publishing content with broken markup, and content that you publish on accident. Since your previous deploy was never modified, we can revert to that state at any time. We only need to change the tree reference where your domain point to again.
- We can serve different content in beta.example.com and www.example.com by pointing each domain to a different tree.
- Still amazing how much you can do with so little these days. How we built Hamiltix.net for less than $1 a month on AWS. The objective was to search for tickets across multiple sites so you can compare all tickets regardless of date.
- Based on Lambda.
- Cloudwatch event rules kick off any Lambdas that need to run on intervals (getting and ranking tickets), and API Gateway fires any "dynamic" content for the website like advanced search, or the actual ticket purchasing.
- The site it stored on S3 and distributed by Cloudfront. Ajax calls in the site's javascript are sent to the API Gateway which in turn calls the correct lambda function to handle whatever task is requested.
- A staging environment uses our ticket broker's sandbox API to test all functions on each commit to master. For this to work, you need two separate environments in API Gateway, and the corresponding aliases for your lambda function
- Uses Gitlab and its built in CI/CD. The hamiltix repo is set up with each lambda as a submodule.
- Getting a push alert any time there is an error helps respond to issues as soon as they come up.
- After the free-tier expires costs should remain under $5.
- Zero to 12 Million. Here's a success story of moving from a legacy enterprise architecture (monolith, Tibco, etc) to a microservices architecture using Cloud Foundry. T-Mobile's old software release process took 72 steps and 7 months. For T-Mobile big traffic periods revolve around new phone releases. They'd have to gear up months in advance. In practice they only scaled up. Scaling down took the same 7 months, so it never happened and a lot of useless servers hung around consuming money. T-Mobile has many different environments and it was difficult to keep these in sync from dev, test, to prod. The was so much drift it was hard to deploy accurately. Chose Cloud Foundry as part of the process of moving to microservices, containers, and the general shift to DevOps. They want consistent deploys, they want to be able to rollback on failure, they want to scale up and scale down on demand. They wanted all the new cloud native goodness. On the iPhone launch they want to autoscale as necessary. Wanted an enterprise proven platform with a standard process and architecture baked in. Made it easy to adopt and train people. Now running over 11,000 containers. Running in multiple datacenters witout problems. Saw a 43% reduction in application response time; 40% in increased planned change velocity; 83% fewer incidents resolved 67% faster (microservices FTW).
- Lots of different opinions on graph databases. Sentiment seems to be more negative, though RDF gets a few shout outs for both its power and complexity. Ask HN: If you've used a graph database, would you use it again?
- marknadal: I liked Neo4j quite a bit, it could handle all the sensor/IoT data we could throw at it. Back then it had (and I'm sure still does) a beautiful interactive data visualization dashboard, great Cypher tutorials, and more. Neo4j is a good database. At the same time really cool tools like Firebase were becoming popular, and Multi-Master database architecture with Cassandra and Riak were showcasing what high availability could do. Graph databases, to me, are so compelling, I have not only "used them again" but spent the last 3.5+ years of my life dedicated to building, improving, and making them more awesome. I certainly hope others try them, even if it isn't GUN. They're worth a shot, but aren't a silver bullet, so use them where it makes sense.
- nsedlet: We had a production Rails app running with postgres, and we decided to implement some of our models with Neo4j. Graphs felt like the right way to represent the data, and all of the models were new, so we felt more free to choose the approach that seemed best. A month later we rewrote everything in SQL - the main drivers were: - as we refined our model, we realized that a relational DB with a bunch of join tables was good enough - our developers were more comfortable working with SQL - it wasn't possible to run complicated queries involving both databases simultaneously - the Rails ORM felt easier to use than the Neo4j Ruby APIs (though this was certainly a function of our own familiarity with Rails and relational databases in general) - having the extra database complicated our codebase and complicated our deployment
- Comparing AWS Lambda performance of Node.js, Python, Java, C# and Go. C# on .Net Core 2.0 is the overall winner. Surprised? 3x faster than Go. The runtime performance of Go is very similar to Java . Dynamic languages and compiled languages perform about the same these days.
- Slack goes the way of all things proprietary. Slack decides to close down IRC and XMPP gateways. There's the usual Slack sucks commentary, but the accessibility for the blind thread was an interesting twist. bramd: Not just that, but it took them months to implement some (mind you, still not all) features that are useful for blind users that someone already did in a userscript in a few days. So yeah, I take this promise with some skepticism. So either this is a lack of priority and disrespect to a part of their users or some level of incompetence. I might sound harsh about this, but imagine being a blind software dev that's supposed to work with Slack to participate in teams. Every day you sign on to your team it's possible that the Slack devs break something and you can't function. And now they closed the escape hatch.
- If your business model is Assets-as-a-Service (AaaS) then Ben Thompson has some good advice for you. Lessons from Spotify: AaaS companies can’t assume that operational expenses are “free”, because gross marginal costs are going to eat up a huge portion of gross revenue growth. AaaS companies should focus Sales & Marketing spending on increasing demand, and allow demand to draw supply. AaaS companies that can’t lower their operational costs or grow revenue relatively faster than Sales & Marketing will be left rolling the dice on eliminating marginal costs entirely. Also, a more nuanced discussion in EPISODE 144 — 90S ALT FOREVER. Instead of trying to squeeze Spotify for every penny, labels blew it by not enlisting Spotify as an ally.
- It's always the memory. Instagram is Open-sourcing a 10x reduction in Apache Cassandra tail latency.
- Apache Cassandra is a distributed database with it’s own LSM tree-based storage engine written in Java. We found that the components in the storage engine, like memtable, compaction, read/write path, etc., created a lot of objects in the Java heap and generated a lot of overhead to JVM. To reduce the GC impact from the storage engine, we considered different approaches and ultimately decided to develop a C++ storage engine to replace existing ones. We did not want to build a new storage engine from scratch, so we decided to build the new storage engine on top of RocksDB.
- gfosco: RocksDB is used all over Facebook, powers the entire social graph. Great storage engine that pairs well with multiple DBMS: MySQL, Mongo, Cassandra.
- jjirsa: Cassandra does a bunch of stuff off-heap - we keep things like Bloom Filters, our compression offsets (to seek into compressed data files), and even some of the memtable (the in-memory buffer before flushing) in direct memory, primary for the reasons you describe.
- We still have "other" things on-heap. The biggest contributor to GC pain tends to be the number of objects allocated on the read path, so this patch works around that by pushing much of that logic to rocksdb.
- Travelexp moved from containers to Lambda functions for some of their services. They've learned a few things moving one of their services from Kotlin to Go. Blazing Fast Microservice with Go and Lambda: Higher memory allocation doesn’t automatically mean a higher cost. Copying values all over the place can end up being pretty expensive in terms of memory consumption. The Kotlin function shows decent results once warm, it’s clearly not the case when cold. Go end up being blazing fast and extremely cheap when warmed. Kotlin consumes 3 times more memory. The Go function shows far better results in every circumstance. Because of VPC throttling and how the Elastic Network Interfaces (ENI’s) are assigned to Lambda function containers lowering the memory consumption of your function is crucial. Make sure your database connection is in the global state of the function and not inside the handler. Lambda allows you to configure a concurrency limit per function. This come in handy if your VPC subnet’s capacity isn’t big enough to keep it up with the account level limit (default). Additionally, it can help avoid smashing your database.
- What happens when Netflix optimizes video encoding around domain entities like shots instead of dumb chunks of bits? Dynamic optimizer — a perceptual video encoding optimization framework: The result was an average bitrate savings of 17.1% over the best possible fixed-QP encoding of the entire video sequence when using HVMAF as quality metric. The improvement when using PSNR is even higher: 22.5% bitrate savings on average. In this comparison, computational complexity remained constant between the baseline and dynamic optimizer results.
- The pod architecture has a long history in scalable system design. Shopfy explains how they use pods. A Pods Architecture To Allow Shopify To Scale: Simply sharding the databases wasn't enough, we needed to fully isolate each shard so a failure couldn't spiral out into a platform outage. We introduced pods (not to be confused with Kubernetes pods) to solve this problem. A pod consists of a set of shops that live on a fully isolated set of datastores. Outside of the isolated datastores, pods also have shared resources such as job workers, app servers, and load balancers. However, all shared resources can only ever communicate to a single pod at a time—we don’t allow any actions to reach across pods. Using pods buys us horizontal scalability, we can consider each pod in total independence, and since there no cross-pod communication, adding a new pod won’t cause unexpected interference with other, pre-existing pods.
- Jepsen takes on Aerospike 3.99.0.3 (a long time advertiser on HS). How did they do against the guantlet? Not bad: SC [strong consistency] mode in 3.99.2.1 provides linearizable single-key operations so long as processes and clocks are reasonably well-behaved, and can tolerate total network partitions while retaining partial availability...Foundational work to enable SC mode has also improved AP [totally-available mode] performance and stability. But: Users should also take care to run Aerospike on semi-realtime networks and computers. For instance, some virtualized environments may pause VMs for multiple minutes to migrate them to other physical nodes; this could cause the loss of data in Aerospike.
- This seems kind of funny: All of Oculus’s Rift headsets have stopped working due to an expired certificate; until you read: mattnewport: Our VR surgical training startup has been working for the last few months towards a big medical conference this week where we're showing multiple training procedures for multiple customers on Oculus Rift, as well as having our own booth. The headsets all stopped working the morning of the conference. Fortunately one of our engineers figured out we could get our demo rigs working by setting the clock back a few days. This could have been a huge disaster for our company if we hadn't found that workaround though. Pretty annoyed with Oculus about this.
- Sematext made changes you might find useful too. Top 10 Engineering Changes in 2017: 1. From static infra to containers orchestrated with Kubernetes. 2. From Subversion to GitHub. 3. From releases to GitHub flow, Sprints, and CI/CD. 4. From Java to Go: Agent. 5. From Java to Go & Kotlin: Backend. 6. From JSP & JSTL to ReactJS and Redux. 7. From HBase to ClickHouse. 8. From Rsyslog to Logagent. 9. From Confluence to MkDocs. 10. From Maven to Gradle.
- Analog or digital? Surprisingly even your vinyl is probably digital because it has been digitally mastered before being pressed. And if you think your record player is a pure experience only the first song on a record has the correct frequency response because of the angle of the arm is wrong on later tracks. Listen to My Bloody Valentine's Kevin Shields Gets Deep Into 'Loveless' for a deep dive on the differences between analog and digital and what horrible things digital recording equipment can do to your recordings.
- This is why we can't have nice distributed and federated things: they are too slow to change. Reflections: The ecosystem is moving: XMPP is an example of a federated protocol that advertises itself as a “living standard.” Despite its capacity for protocol “extensions,” however, it’s undeniable that XMPP still largely resembles a synchronous protocol with limited support for rich media, which can’t realistically be deployed on mobile devices. If XMPP is so extensible, why haven’t those extensions quickly brought it up to speed with the modern world? Like any federated protocol, extensions don’t mean much unless everyone applies them, and that’s an almost impossible task in a truly federated landscape. What we have instead is a complicated morass of XEPs that aren’t consistently applied anywhere. The implications of that are severe, because someone’s choice to use an XMPP client or server that doesn’t support video or some other arbitrary feature doesn’t only affect them, it affects everyone who tries to communicate with them. It creates a climate of uncertainty, never knowing whether things will work or not. In the consumer space, fractured client support is often worse than no client support at all, because consistency is incredibly important for creating a compelling user experience.
- 6 things I wish I had known before going Serverless: Use SSM and Environment Variables; Lambda@Edge can replace your SPA’s .htaccess file; ou can’t delete Lambda@Edge functions; You can use WAF [web application firewall] to White/Blacklist your serverless site…and more; You can build your own CloudFormation Resources.
- SuddsMcDuff: We've taken a very similar approach when migrating data from one DB to another (MySql to Redis in our case, but the principle should apply to any databases). We split it into 4 phases: * Off - Data written only to MySql (starting state) * Secondary - Data written to both MySql and Redis, and MySql shall be the source of truth. * Primary - Data written to both MySql and Redis, and Redis shall be the source of truth. * Exclusive - Data written exclusively to Redis. Also, Large Scale NoSQL Database Migration Under Fire.
- After reading so much over the years on how the world could magically change if only we used a smarter algorithms for this or that, here's an actual case of someone actually using a different voting algorithm in the US. Santa Fe's 1st RCV election: clear outcomes, effective new ballot use. I know zip about the candidates or issues, but voters seemed happy with the process. It's almost like algorithms matter.
- Next time you get a datastructure from someone who doesn't believe in documentation keep this article in mind. Awesome explanation and analysis. Progressive Locks : fast, upgradable read/write locks: On a core i7-6700K running at 4.4 GHz, a lookup in a tree containing 1 million nodes over a depth of 20 levels takes 40 ns when all the traversed nodes are hot in the L1 cache, and up to 600 ns when looking up non-existing random values causing mostly cache misses...For a workload consisting in 1% writes in the worst case conditions above, a single core would spend 87% of its time in reads, and 13% in writes, for a total of 22 million lookups per second. This means that even if all reads could be parallelized on an infinite number of cores, the maximum performance that could be achieved would be around 160 million lookups per second, or less than 8 times the capacity of a single core...It is obviously not a surprise that the difference between locking mechanisms fades away when the miss cost increases and the hit ratio diminishes since more time is proportionally spent computing a value than competing for a lock. But the difference at high hit ratios for large numbers of threads is stunning : at 24 threads, the plock can be respectively 5.5 and 8 times faster than R/W locks and spinlocks! And even at low hit ratios and high miss cost, the plocks are never below the pthread locks and become better past 8-10 threads.
- Need to choose a datacenter? There's a lot to consider. Backblaze on The Challenges of Opening a Data Center Part1 and Part2.
- When designing or selecting a data center, an organization needs to decide what level of availability is required for its services. The type of business or service it provides likely will dictate this.
- Data center brokers can be employed to find a data center, just as one might use a broker for home or other commercial real estate.
- Risk mitigation also plays a strong role in pricing. The extent to which providers must implement special building techniques and operating technologies to protect the facility will affect price.
-
Good explanation of Message Passing and the Actor Model. It's just one chapter from Programming Models for Distributed Computing.
-
Proxies are the embodiment of every problem can be solved with another layer of direction. Looks like Dropbox has built themselves the very capable indirection layer every larger service needs. Meet Bandaid, the Dropbox service proxy. Bandaid supports: a rich set of load balancing methods (round-robin, least N random choices, absolute least connection, pinning peer); SSL termination; HTTP2 for downstream and upstream connections; metro rerouting; buffering of both requests and responses; logical isolation of endpoints running on the same or different hosts; dynamic reconfiguration without a restart; service discovery; rich per route stats; gRPC proxying; HTTP/gRPC health checking.
-
Fun debugging story. Spooky action at a distance, how an AWS outage ate our load balancer: After putting all these pieces together, a clear picture emerged. AWS hosts from the affected regions were experiencing connectivity issues that significantly slowed down their connections to our load balancers (but not bad enough to break the connection). As a result, these hosts were hogging all the available connections until we hit a connection limit in our load balancers, causing hosts in other locations to be unable to create a new connection. Confirming this was the first step towards making changes to prevent it from happening again, which in our case included enforcing stricter client timeouts and raising our connection limits.
-
Good experience report. Elm, Elixir, and Phoenix: Reflecting on a Functional Full-Stack Project. Working a full functional stack is nice, but wishes it was easier to change the UI.
-
Lessons learned writing data pipelines: If you’re building a new dataset, first define your initial schema and work towards making it available as soon as possible; Use compression everywhere; Use some kind of distributed storage.
-
dgryski/awesome-consensus: A "curated" list of consensus algorithms and distributed lock services.
-
REANNZ/ruru: 'Ruru' is a TCP latency monitoring application that helps understanding wide area TCP traffic in real time. It utilises Intel DPDK for high speed packet processing (up to 40Gbit/s) and a Node.JS web frontend to present results.
-
VeritasDB: High Throughput Key-Value Store with Integrity: We present VeritasDB, a key-value store that guarantees data integrity to the client in the presence of exploits or implementation bugs in the database server. VeritasDB is implemented as a network proxy that mediates communication between the unmodified client(s) and the unmodified database server, which can be any off-the-shelf database engine (e.g., Redis, RocksDB, Apache Cassandra). The proxy transforms each client request before forwarding it to the server and checks the correctness of the server's response before forwarding it to the client.
-
Automatic Machine Knitting of 3D Meshes: We present the first computational approach that can transform 3D meshes, created by traditional modeling programs, directly into instructions for a computer-controlled knitting machine. Knitting machines are able to robustly and repeatably form knitted 3D surfaces from yarn, but have many constraints on what they can fabricate.
-
45-year CPU evolution: one law and two equations: Moore’s law and two equations allow to explain the main trends of CPU evolution since MOS technologies have been used to implement microprocessors.
-
Seven Concurrency Models in Seven Weeks: This is a book about concurrency, so why are we talking about parallelism? Although they’re often used interchangeably, concurrent and parallel refer to related but different things



