The Anna Key-Value Store Now Has 355x the Performance of DynamoDB for the Dollar

New databases used to be announced seemingly every week. While database neogenesis has slowed down considerably, it has not gone necrotic.
RISELabs, those wonderfully innovative folks over at Berkeley, have uplifted their Anna datatabase—a shared-nothing, thread-per-core architecture to achieve lightning-fast speeds by avoiding all coordination mechanisms—to become cloud-aware.
What's changed?
Anna is not only incredibly fast, it’s incredibly efficient and elastic too: an autoscaling, multi-tier, selectively-replicating cloud service. All that adaptivity means that Anna ramps down resource consumption for cold things, and ramps up consumption for hot things. You get all the multicore Anna performance you want, but you don’t pay for what you don’t need.Just to throw out some numbers, we measured Anna providing 355x the performance of DynamoDB for the dollar. No, I don’t think that is because AWS is earning a 355x margin on DynamoDB! The issue is that Anna is now orders of magnitude more efficient than competing systems, in addition to being orders of magnitude faster.
They've posted about Anna's new superpowers in Going Fast and Cheap: How We Made Anna Autoscale:
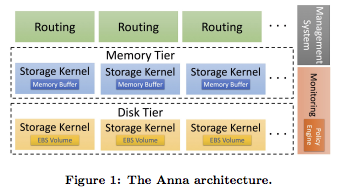
Using Anna v0 as an in-memory storage engine, we set out to address the cloud storage problems described above. We aimed to evolve the fastest KVS in the cloud into the most adaptive, cost-effective one as well. We did this by adding 3 key mechanisms to Anna: Vertical Tiering, Horizontal Elasticity, and Selective Replication.The core component in Anna v11 is a monitoring system & policy engine that together enable workload-responsiveness and adaptability. To meet user-defined goals for performance (request latency) and cost, the monitoring service tracks and adjusts resources to workload changes. Each storage server collects statistics about the requests it serves, the data it stores, etc. The monitoring system periodically scrapes and munges this data, and the policy engine uses these statistics to take action via one of three mechanisms listed above. The trigger for each action is simple:
- Elasticity: In order for a system to adapt to changing workloads, the system must be able to autoscale up and down to match the request volume it is seeing. When a tier is saturating compute or storage capacity, we add nodes to the cluster, and when resources are underutilized, they are deallocated to save cost.
- Selective Replication: In real workloads, there is often a hot set of keys, which should be replicated beyond fault-tolerance requirements to improve performance. This increases the cores and network bandwidth available to serve common requests. Anna v0 enabled multi-master replication of keys, but had a fixed replication factor for all keys. As you can imagine, that was unreasonably expensive. In Anna v1, the monitoring engine picks the most accessed keys and increases the number of replicas of those keys specifically, without paying extra to replicate cold data.
- Promotion & Demotion: Just like traditional memory hierarchies, cloud storage systems should store hot data in a high-performance, memory-speed tier for efficient access, while cold data should reside in a slower tier to save cost. Our monitoring engine automatically moves data between tiers based on access patterns.In order to implement these mechanisms, we had to make two significant changes to the design of Anna. First, we deployed the storage engine across multiple storage media — currently RAM and flash disk. Each of these resulting storage tiers represents a different cost-performance tradeoff, akin to a traditional memory hierarchy. We also implemented a routing service that sends user requests to the correct servers in the correct tiers. This gives users a single, uniform API regardless of where the data is stored. Each one of these tiers has the same rich consistency model inherited from the first version of Anna, so the developer can work off a single (widely parameterizable) consistency model.Our experiments show an impressive level of both performance and cost efficiency. Anna provides 8x the throughput of AWS ElastiCache’s and 355x the throughput of DynamoDB for a fixed price point. Anna is also able to react to workload changes by adding nodes and replicating data appropriately.
RISELab has the goal of enabling computers to make intelligent real-time decisions. You might not remember last year RISELab arose from the ashes of AMPLab. AMPLab produced such open source successes as Apache Spark and Apache Mesos, so don't make the mistake of thinking anything they do is of mere academic interest. They are about creating the future.
Related Articles
- Anna Paper: Eliminating Boundaries in Cloud Storage with Anna
- Anna Code: fluent-project/fluent



