The Eternal Cost Savings of Netflix's Internal Spot Market


Netflix used their internal spot market to save 92% on video encoding costs. The story of how is told by Dave Hahn in his now annual A Day in the Life of a Netflix Engineer. Netflix first talked about their spot market in a pair of articles published in 2015: Creating Your Own EC2 Spot Market Part 1 and Part 2.
The idea is simple:
Netflix runs out of three AWS regions and uses hundreds of thousands of EC2 instances; many are underutilized at various parts in the day.
Video encoding is 70% of Netflix’s computing needs, running on 300,000 CPUs in over 1000 different autoscaling groups.
So why not create a spot market out of their own underutilized reserved instances to process video encoding?
Before proceeding let's define what a spot market is:
Spot Instances enable you to request unused EC2 instances, which can lower your Amazon EC2 costs significantly. The hourly price for a Spot Instance (of each instance type in each Availability Zone) is set by Amazon EC2, and adjusted gradually based on the long-term supply of and demand for Spot Instances. Your Spot Instance runs whenever capacity is available and the maximum price per hour for your request exceeds the Spot price.
At any point in time AWS has a lot of underutilized instances. It turns out so does Netflix. To understand why creating an internal spot market helped Netflix so much, we'll first need to understand how they encode video.
How Netflix Encodes Video
Dave explained the video encoding process:
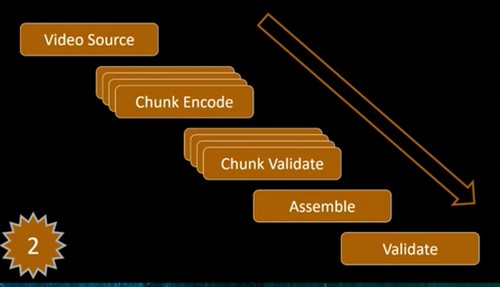
Netflix gets video from production houses and studios. First, Netflix validates the source file, looking for missing frames, digital artifacts, color changes, and any other problems. If problems are found, the video is rejected.
Video files are huge. Many many terabytes in size. Processing a single multi-terabyte sized video file is not reasonable, so it’s broken up into chunks so it can be operated on in parallel.
Chunks are sent through the media pipeline. There’s lots of encoding work to do. Netflix supports 2200 devices and lots of different codecs, so video is needed in many different file formats.
Once the chunks are encoded, they’re validated again to make sure new problems haven’t been introduced. The chunks are assembled back into a file and validated again.
Over 70 different pieces of software are involved with the pipeline.
Netflix believes static encoding produces a higher quality video viewing experience than dynamic encoding. The result is a lot of files.
Stranger Things season 2 is shot in 8K and has nine episodes. The source files are terabytes and terabytes of data. Each season required 190,000 CPU hours to encode. That’s the equivalent of running 2,965 m4.16xlarge instances for an hour. The static encoding process creates 9,570 different video, audio, and text files.
How do you encode video? There are two possible approaches.
The most obvious approach is setting up a static farm of instances reserved only for media encoding. The win of this approach is you always have the resources you need available.
But if you look, encoding has a bursty workload pattern. That means the farm would be underutilized a lot of the time.
Whenever you see bursty workloads the idea of leveraging a spot market should burst immediately to mind.
AWS already has a spot market, why not use that? Why build your own spot market from your own reserved instances?
Netflix has a huge baseline capacity of reserved instances. They autoscale in and out 10,000s of instances a day from this pool. When Netflix autoscales down they have unused capacity. Unused capacity is a waste of money and spot markets are great way of soaking up all that unused capacity while also getting important work done.
So Netflix did a genius thing, they built their own internal spot market to process the chunked encoding jobs. The Engineering Tools team built an API exposing real time unused reservations at the minute level.
What were the cost savings of using an internal spot market versus a static encoding farm? 92%!
It's All About the Economics
Netflix started their own internal spot market for the same reason Amazon did; cloud economics are all about driving higher machine utilization. Reserving instances saves a lot of money in AWS, it makes sense to extract the most value as possible out of those instances. Every microsecond CPUs are not working is a waste of money.
Back in the day, like many people, before it became clear AWS would become the eater of all infrastructure, I was brainstorming AWS startup ideas. I was pursuing some of the ideas I later detailed in Building Super Scalable Systems: Blade Runner Meets Autonomic Computing In The Ambient Cloud.
My favorite was creating a secondary market so developers could resell the unused capacity on their instances. Utilization of VMs is still abysmally low. There’s lots of unused CPU, network, and memory capacity on instances. So it seemed like a good idea. A cloud within a cloud.
The kicker was security. Who would run code and put their data on an a random machine without a security guarantee? This was before containers. Though I had used Jails on FreeBSD to good effect, the idea of containers never occurred to me.
My idea was something like lambda, which was why in What Google App Engine Price Changes Say About The Future Of Web Architecture, I was disappointed when GAE pivoted towards a higher granularity system:
I thought GAE would completely lose the instance image concept all together in favor of applications being written on one giant task queue container.
The basis of this conjecture/vision is the development and evolution of one of GAE's most innovative and far reaching features: task queues. It's a great feature that allows applications to be decomposed into asynchronous flows. Work is queued and executed at some later time. Instead the monolithic and synchronous model used originally by GAE, an application can be completely asynchronous and can be run on any set of machines. For a while now it has been clear the monolithic front-end instances have become redundant with the fruition of task queues.
The problem is task queues are still image based. Operation are specified by a URL that terminate inside a run time instance whose code template is read from an image. An image contains all the code an application can execute. It's monolithic.
When a web client URL is invoked it executes code inside a monolithic image. It's these large images that must be managed by GAE and why Google needs to charge you more. They take resources to manage, time to initialize, and while running take memory even if your app isn't doing anything.
A different idea is to ask why can't a request terminate at a task queue work item instead? Then the monolithic image could be dropped infavor of an asynchronous coding model. Yes, GAE would have to still manage and distribute these code libraries in some fantastical way, no simple task, but this would solve the matching work to resources granularity problem that they instead solved by going the other direction, that is making images the unit of distribution and instances the unit of execution. We'll talk more about the granularity problem next.
So with this super cool task queue framework and programming model being developed I felt sure they were ready to announce that the monolithic images would disappear, instances would disappear, and there would be an even finer pay for what you use billing model as a replacement. I was wrong. Again.
It's A Problem Of Quanta Mechanics
Driving this upheaval is that programs run on an abstract machine that uses resources that are quantized differently than the underlying physical machines. A server comes with only so much memory and CPU. Running programs use memory even when a program is idle. Google must pay for the machine resources used by an instance. Charging only for the resources used by a program instead of all the resources used to host a program creates an unsustainable and unprofitable pricing friction between the two models.
In other words, programs are deployed in big quanta, but run in small quanta. A smaller work granularity would allow work to be schedule in idle times, which is why I think the task queue model is superior.
It’s nice to see those ideas eventually worked out.
Related Articles
- On HackerNews
- twosigma/Cook - Fair job scheduler on Mesos for batch workloads and Spark
- jedberg: I was a former [Netflix] insider so I can't get into details, but if you look you'll see that almost the entirety of their cost is content acquisition. The next biggest cost is salary. Servers barely even register as far as costs go, and also, it's a 92% savings over what the cost would have been without the system, not an absolute 92%. The farm keeps growing all the time as movies become higher resolution and more encodings are supported.



