How UltraDNS Handles Hundreds of Thousands of Zones and Tens of Millions of Records


This is a guest post by Jeffrey Damick, Principal Software Engineer for Neustar. Jeffrey has overseen the software architecture for UltraDNS for last two and half years as it went through substantial revitalization.
UltraDNS is one the top the DNS providers, serving many top-level domains (TLDs) as well as second-level domains (SLDs). This requires handling of several hundreds of thousands of zones with many containing millions of records each. Even with all of its success UltraDNS had fallen into a rut several years ago, its release schedule had become haphazard at best and the team was struggling to keep up with feature requests in a waterfall development style.
Development
Realizing that something had to be done the team came together and identified the most important areas to attack first. We began with the code base, stabilizing our flagship proprietary C++ DNS server, instituting common best practices and automation. Testing was very manual and not easily reproducible, so we brought our QA engineers and developers closer together to create and review design, code, and automated tests. Their goal was to eliminate variability from our deliverables. We introduced the following tools:
- Unit testing: gtest
- Performance Testing: dnsperf (modified) & custom pcap tools
- Static analysis: cppcheck
- Test & Build automation: Jenkins
- Task tracking: Jira
- Code Reviews: Fisheye and Crucible
- Common Framework: based on selected parts of Boost
Environment
Our various deployment environments, including production, were another area that required immediate attention. These environments lacked any kind of homogeneity; dozens of flavors and versions of Linux were actively in use. Without any uniformity development was very complex and error prone due to the number of targets, so we standardized on 1 version of 1 distribution. In order to achieve better reproducibility of installations and associated packages we choose puppet to manage this task. We adopted the following:
- Distribution: RHEL (moving to Ubuntu)
- Configuration Management: Puppet
- Metrics graphing: graphite
- Monitoring: Nagios
Architecture
Features such as DNSSEC, enhanced directional answers, and enhanced traffic services were needed to stay competitive in the market. The current architecture was heavily based around Oracle, so much so that it directly impacted our queries per second (QPS) rate of our DNS server.
The UltraDNS DNS server needs to efficiently support both TLDs and SLDs, which have unique usage patterns. TLDs typically contain millions of records and change infrequently, usually daily, but the changes can be a large percentage of the records. Whereas the SLDs are smaller zones with records in the tens to hundreds of thousands, but with a higher change rate consisting of a smaller percentage of the records.
All types share the requirement that changes be propagated as fast as possible globally. DNSSEC adds an extra wrinkle in that the signed record sets along with the keys that signed them must be available at the edge together. This led us to build a DNSSEC zone signing service to address our speed and extended feature requirements.
But we still needed to ensure that the proper state of a zone was presented to our DNS servers and transported in an efficient way, so we created a specialized data feeder service in Java. We utilized Thrift with its compact encoding over HTTP which allowed us to easily scale using standard web caches.
Data Feeder Service:
- Data store: OrientDB embedded
- Transport: Thrift over an HTTP REST-like interface utilizing jetty & apache-cxf
- Testing: Cucumber-jvm
- Static Analysis: pmd, checkstyle
- Code Coverage: JaCoCo
- Dependency Management: ivy
As a result our DNS server was able to move to a model that keeps almost every zone in memory while serving the data out of a lock-free pipeline. This yielded significant performance improvement that resulted in a >7x QPS processing capacity on a per DNS server basis.
Rather than relying on database replication, our data propagation is now more predictable and stable since we only transported the data needed to the edge.
Both of these enhancements have allowed us to nearly double our number of nodes and improve our DDoS mitigation as we must constantly deal with tens of gigabits per second of attack traffic.
People
Technology was only one facet that was attacked, we also moved to using scrum from a waterfall model; this change has taken significant time and is still evolving today, however it has already paid great dividends. Another important change was to tighten our hiring process ensuring that the people we brought on were inline with our process and technology goals. We've taken some lessons from other great companies and refined our hiring process to address both technical as well as non-technical aspects of a candidate. As a result we've built a great team that has been able revive the product.
Conclusion
There have been many bumps in the road, but now we are in a much better place to quickly adapt and adjust. Our release schedule is now approximately every 2 weeks near the end of a sprint, however there are usually interim changes that are rolled out all the time. To track ourselves, we now aim to collect metrics on everything, including our software, hardware, network, support issues, and our deliveries so that we can constantly improve.
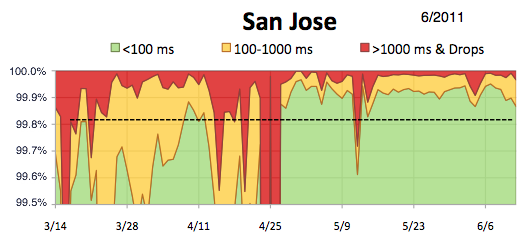
Service Availability
To illustrate our improvement below are graphs from within a single node in San Jose, CA
Stabilization:
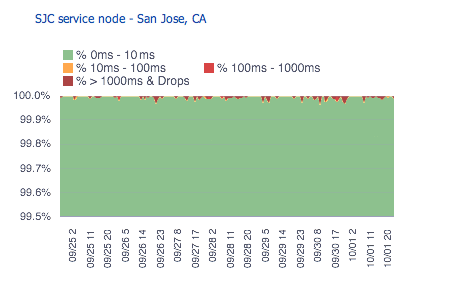
Latest release (2012):
If any of this sounds interesting, we're hiring!



