BigData using Erlang, C and Lisp to Fight the Tsunami of Mobile Data


This is a guest post by Jon Vlachogiannis. Jon is the founder and CTO of BugSense.
BugSense, is an error-reporting and quality metrics service that tracks thousand of apps every day. When mobile apps crash, BugSense helps developers pinpoint and fix the problem. The startup delivers first-class service to its customers, which include VMWare, Samsung, Skype and thousands of independent app developers. Tracking more than 200M devices requires fast, fault tolerant and cheap infrastructure.
The last six months, we’ve decided to use our BigData infrastructure, to provide the users with metrics about their apps performance and stability and let them know how the errors affect their user base and revenues.
We knew that our solution should be scalable from day one, because more than 4% of the smartphones out there, will start DDOSing us with data.
We wanted to be able to:
- Abstract the application logic and feed browsers with JSON
- Run complex algorithms on the fly
- Experiment with data, without the need of a dedicated Hadoop cluster
- Pre-process data and then store them (cutting down storage)
- Be able to handle more than 1000 concurrent request on every node
- Make “joins” in more than 125M rows per app
- Do this without spending a fortune in servers
The solution uses:
- Less than 20 large instances running on Azure
- An in-memory database
- A full blown custom LISP language written in C to implement queries, which is many times faster that having a VM (with a garbage collector) online all the time
- Erlang for communication between nodes
- Modified TCP_TIMEWAIT_LEN for an astonishing drop of 40K connections, saving on CPU, memory and TCP buffers
Long Live In-Memory Databases
We knew that the only way we could handle all of this traffic was by using an In-Memory database.
To answer ad-hoc questions fast on a huge dataset (e.g., “How many unique users with Samsung devices have this specific error for more than a week”) not only do you have to deal with memory limitations but also with the data serialization and deserialization before and after the data processing. That’s the reason, we started the LDB Project.
LDB Project
Would you believe it that you can feed data coming from various sources (even thousand different resources - like mobile devices) into a system, describe what information you want to extract in a few lines of code and then have all this information in your finger tips? In real time. While the system keeps running?
LDB is more of an application server than just a database. And even though it is In-Memory, data is actually stored in the hard-drive and replicated across other nodes.
With LDB we don’t run queries. We run algorithms because we have a full blown custom LISP language written in C that has access to the same address space with the database. That means that you can search extremely fast for data, increase counters, get/put etc.
The advantage of having a LISP is that you can easily create an SQL-like language like Hive and query your data, in realtime like this:
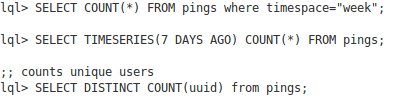
LDB works like this:
Every app has it’s own LDB. That means its own memory space. In this way we can easily move bigger apps (in terms of traffic) to different machines.
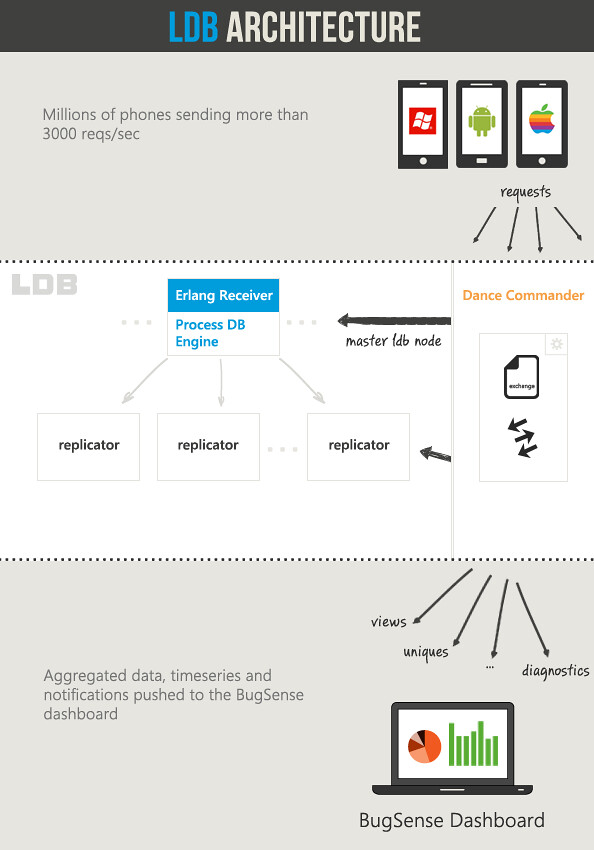
When a request comes from a mobile device, the main LDB node, accepts the connection (using a pool of erlang threads) and forwards the data to a specific DB. This request handling mechanism is implemented with fewer than 20 lines of Erlang code. Another reason we chose Erlang for communication between nodes.
When the request is “streamed” to LDB, a file called “process.lql” is responsible for analyzing, tokenizing the data and creating any counters. All this is done on the fly and for every request.
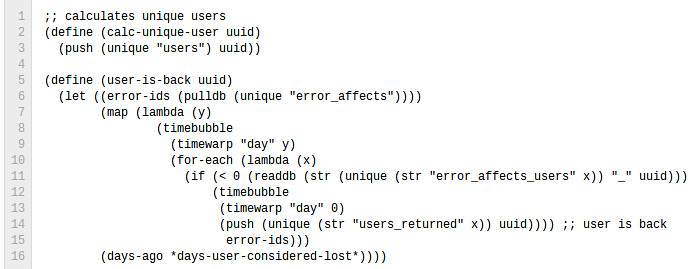
We are able to do this, because starting our LISP-VM and doing all these processes on every request, is still many times faster that having a VM (with a garbage collector) online all the time.
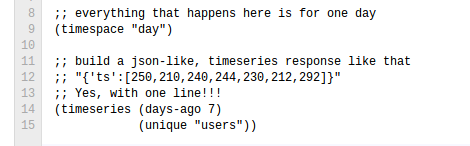
With LDB we can create time series and aggregated data with no more than 3 lines of code.
For example. this creates a timeseries for unique users for 7 days:
Alternatives
During our tests, we saw that SQL databases weren’t a good fit due to the fact that our data were unstructured and we needed a lot of complex “joins” (and many indexes). One the other hand for NoSQL databases, we couldn’t run our algorithms on the data (while the system was running) and having mappers/reducers made the whole thing complicated and slow. We needed a high concurrent system with no big locks or DB locks that can track millions of unique events in just a few KBs and be very easy to extend.
A very good alternative was using a Stream database (like Storm). Our main issue was having a lot of moving parts and performance of single nodes. With LDB, we have the advantage of being able to process data extremely fast (they reside in the same memory space), store them as aggregated counters or symbols (thus fitting gigabytes of data in KBs) and then having a DSL to do whatever correlations we want on the fly. No serialization/deserialization, no network calls and no garbage collectors. It is like having assembly code mapped onto your data.
On top of that with LDB we have receivers that can scale and handle incoming data, a stream component where everything is defined in a couple of lines of code, a Storage Engine and a Replication engine.
Optimizing kernel - UDP behavior with TCP
What is unique when doing analytics in contrast to other services that come in massive requests/sec, is that the dialog between the mobile device and the server is extremely small (3 TCP handshake packets, 1 payload packet and 3 TCP termination packets).
However, TCP was not designed with something like that in mind (that is, small dialogs between devices) and implements a state called TIME_WAIT (which lasts about 1 minute in 2.6 Linux kernels) where after the last FIN packet is sent, the TCP state for that specific connection tuple remains open for sometime in order to receive any stray packets that may have gotten delayed (that is, before the connection close). In our case this is a bit useless though (we want something resembling UDP behavior but with TCP guarantees), since the payload is only 1 packet (and up to 4 or 5 for view requests) so we decided to modify the kernel source and reduce the constant for this down to 20". The result was an astonishing drop of 40K connections, saving on CPU, memory and TCP buffers.
The patch we applied was in file:
linux-kernel-source/include/net/tcp.h
#define TCP_TIMEWAIT_LEN (60*HZ)
to
#define TCP_TIMEWAIT_LEN (20*HZ)
Using this architecture, we can provide real time analytics and insights about your mobile apps, to all of our paying customers with having less than 20 large instances running on Azure, including fallback and backup servers.



