How To Make an Infinitely Scalable Relational Database Management System (RDBMS)


This is a guest post by Mark Travis, Founder of InfiniSQL.
InfiniSQL is the specific "Infinitely Scalable RDBMS" to which the title refers. It is free software, and instructions for getting, building, running and testing it are available in the guide. Benchmarking shows that an InfiniSQL cluster can handle over 500,000 complex transactions per second with over 100,000 simultaneous connections, all on twelve small servers. The methods used to test are documented, and the code is all available so that any practitioner can achieve similar results. There are two main characteristics which make InfiniSQL extraordinary:
- It performs transactions with records on multiple nodes better than any clustered/distributed RDBMS
- It is free, open source. Not just a teaser "community" version with the good stuff proprietary. The community version of InfiniSQL will also be the enterprise version, when it is ready.
InfiniSQL is still in early stages of development--it already has many capabilities, but many more are necessary for it to be useful in a production environment.
Who Would Do This Sort of Thing?
My career background is available on LinkedIn. I've done capacity planning, systems engineering, performance engineering, and so forth for some pretty big transaction processing environments, where a few seconds of downtime costs tens of thousands of customer dollars. Baby-sitting that kind of environment taught me that traditional enterprise database infrastructure is a terrible match for modern environments that need to be up 24x7, grow continuously, and rapidly respond to new business needs. This is really a typical story--we all know that systems designed in the 70's are no match for today's needs. So I decided to build something that is suitable for modern transaction processing environments.
Intended Users/Use Cases
I'm sure that most readers of High Scalability understand why new database architectures are so necessary, and many of us are also of the mind that faster and bigger are self-justifying values. We are like drag-racers. But it's important to know the use cases to help others learn how to take advantage of the great stuff we're building. In the case of InfiniSQL, there are a couple primary customer types, each with a variety of specific use cases. I'll just touch briefly on the customer types and how I see InfiniSQL solving business problems for them.
- Look no further than the example application cited in Design Decisions For Scaling Your High Traffic Feeds, which is a very recent entry on this site. Imagine there's no Part Two and Part Three, meaning that their original RDBMS of choice was able to perform "
select * from love where user_id in (...)" well beyond 100M rows and 1M users. There'd be no need to design a new framework from scratch, or to rip and replace two back ends before settling on one that seems fine for the time being. InfiniSQL is capable of performing that kind of query. I haven't benchmarked that specific workload--but it's the type of thing that I designed InfiniSQL for: transactions with records distributed across multiple nodes.
Successful Internet applications nearly inevitably grow out of the infrastructures with which they launched. An RDBMS is very often the initial database of choice--but workarounds are implemented, and entirely different architectures are implemented--all because the original database can't handle success. That is a very disruptive process. InfiniSQL is intended for any company that has RDBMS workloads, but who has been forced to implement workarounds because their original RDBMS didn't grow with the business. These workarounds include sharding of SQL databases and migrating some workloads to various NoSQL point solutions. In fact, InfiniSQL ought to be the database that companies start with--to avoid migration costs down the road.
- The other category of intended user for InfiniSQL includes those who have applications on monolithic platforms responsible for tens to hundreds of thousands of complex transactions per second. That kind of workload is difficult to move off of big box architectures. Companies of this type include credit card associations, travel reservation systems, and exchanges. These are not new business models. Their infrastructures have been chugging away for decades. Every operation that they perform represents a transfer of funds between (at least) two parties--they move people's money. Stability and data integrity are paramount values. InfiniSQL is capable of performing this type of workload at intended volumes and beyond, but on x86_64 servers running Linux instead of big, super-expensive platforms. InfiniSQL will scale further, in fact--because these big monolithic platforms run out of gas when the boxes they're in run out of expansion slots.
The Problem and its Cause (and a couple related issues)
(I'll redact taking credit for that blaring statement of the obvious if I can find somebody else who said it before me. Otherwise, I'll take it--everybody needs a quote, right? I'll take this one.)
The Problem is getting multiple nodes to all comprise a single database. This problem is easily illustrated by comparing static web servers with databases. It's trivial to scale web servers by simply mirroring their content on different boxes, and then spraying traffic at them in round-robin or some other fashion. Easy. But the same isn't so simple for databases. Take two boxes, and put your favorite database on them. Give each the same schemata. Then, connect to box A and insert a record--any old record. Then connect to box B and look for that record. Of course it's not there! That's the problem with scaling databases horizontally: the logic and data are all in the same box!
Locking Is Mostly Bad
Another problem with traditional database design when it comes to performance is locking. For the sake of data integrity, each worker (thread or process) locks regions of memory or storage associated with records that they operate upon. These are not high level data locks, such as row or table locks (though those can be problematic as well). No, these are implemented as mutexes or semaphores. Mutexes and semaphores are the way that multi-thread/process applications keep other threads/processes from stomping all over shared data. As lock contention for shared memory regions increase, performance degrades. A very likely indicator of lock contention is when the database is slow, but there's plenty of CPU available, and no I/O bottlenecks.
I/O Is Slow, No Matter How Fast It Is
Another big performance problem of traditional databases is the transaction log bottleneck. For the sake of Durability, traditional databases write all transactions that contain written records to the equivalent of a log file, in real time, before finishing a transaction. When the power goes out the data will still be there when the lights come back on. The trouble is that this slows down writes. Take any well-tuned database on the fastest solid-state storage and massive I/O busses. It will bottleneck on writing the transaction log.
InfiniSQL Solutions To These Problems
InfiniSQL is not the only project that has solved some or all of these problems and which has successfully implemented a clustered RDBMS. I'm sure that most readers of this blog are aware of various systems like this, if not already users of them. I'm describing how I've solved these problems--and how they contribute to InfiniSQL's unique strengths. Others have solved these problems in their own ways.
Actors
InfiniSQL implements a variation on the actor model of concurrent programming. C++ is the main language used to create InfiniSQL, and the actor model isn't natively supported in that language. Much of the work of implementing InfiniSQL has involved getting actors to work in C++. The actor model solves the first two problems described above by uncoupling transaction processing logic from storage and by not locking memory regions. Read the overview for specifics. This is a radical departure from legacy RDBMS architectures.
The actor model solves The Problem because processing logic is handled by one set of actors, and data storage is handled by another set. Their functions are loosely coupled in InfiniSQL. Messaging happens between actors regardless of the node that they reside upon: the actor which governs a particular transaction doesn't know or care whether the data resides locally or remotely. And the actor that manages a particular data partition responds to messages regardless of origin. In theory, the actor model allows InfiniSQL to scale without limit. Each record is assigned to a specific data region based on hash value of its first field, and each index record is assigned to a region based on a hashing of the index value.
Another beneficial effect of the actor model is that it solves the problem of low level locking. Since each data region only has a single actor associated, there is no need for mutexes or semaphores to restrict access. The partition's actor handles requests for data manipulation based on messages from transaction actors. The sending actor isn't held up (blocked) waiting for a response but instead is free to work on other tasks. When the partition's actor responds with data, the requesting transaction actor resumes where it left off. It either finishes the transaction and sends a reply to the client, or keeps interacting with other actors.
Here's an example that attempts to graphically illustrate the difference between the traditional shared memory model of database design and InfiniSQL's actor model:
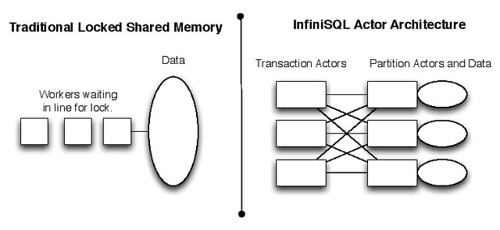
With actors, there's no locking. As more processing is necessary, more actors are added, with each actor roughly optimally corresponding to a single CPU thread or core. As cores are added, actor-based architectures keep up very well. However, the traditional locked shared memory model suffers the more that cores are added--because lock contention only increases. Large monolithic databases have very complex lock management methods to minimize this problem.
Another benefit of the actor model is that it supports massive concurrency. InfiniSQL implements actors slightly differently than the traditional actor model, but it still achieves a very high connection rate while maintaining high throughput. Most traditional databases have a connection threshold beyond which aggregate system performance degrades significantly. This has to do mainly with contention already described, and also because per connection costs are high--if each client requires a dedicated process (or thread) on the server side, then that consumes a lot of memory. Further, highly multi-threaded applications suffer from excessive context switching. The kernel scheduler always has to put threads to sleep, copy their state, and then copy in and activate another thread. With InfiniSQL, the cost to maintain each connection is relatively low-- there must be an open socket that the kernel manages. Plus, an object to manage the connection is created. A couple of maps have entries added to allow the relevant actors to identify the connection. That is a much lower per-connection overhead than having to spin up a whole new thread (let alone process). And to minimize context switching, each actor roughly corresponds to a single CPU thread, so there are fewer threads waiting for CPU.
And to solve the problem of slow I/O, InfiniSQL avoids this currently by being an in-memory database. In memory is simpler to implement, especially with actors, than block-backed storage. But this obviously poses some problems. Namely, durability and cost. If electricity goes out, a single copy of a database in memory vanishes. And the cost of RAM is higher than that of disk. The overview describes plans to overcome these issues given time for development efforts.
The key to InfiniSQL's planned in-memory durability bears emphasizing--it is borrowed from the world of high end storage. High end storage systems perform so well because they write changes to memory--and only later write those changes to disk. They can get away with this because they have redundant battery backup systems and each write is distributed across multiple cache regions. No power loss or single point of failure can cause data loss in high end storage systems--and that's really what matters. The world's biggest transaction processing platforms rely upon this kind of storage array. InfiniSQL intends to implement the same model, except that redundancy and power management will protect database server nodes themselves. This has not been fully implemented yet, but when available, will mean that InfiniSQL will provide in memory performance with durability.
Transaction Processing
Transaction processing details are described in the overview. What I discovered implementing ACID capabilities using actors is that other techniques needed to be implemented as well. Namely, inter-actor remote procedure calls (RPC), a home-grown protocol stack inspired loosely on the OSI model, and continuations. This introduces a certain amount of implementation complexity--I'm on the lookout for ways to refactor and decrease complexity. But all of the ACID characteristics (except for Durability, as described above) are functional.
Row Based, Tables, Indices and Stuff Like That
The actor-based core and transaction processing capabilities could work with any number of different types of databases. Column-based, simple keystores, xml doc stores, graphdb's. Anything that needs to scale and benefits from parallelism. But I chose to implement a row-based RDBMS as the first underlying storage scheme for InfiniSQL. In spite of the other types, this model still support a huge variety of applications. Most of the alternate data organization types are optimized for a particular type of workload--and abysmal at others. Column data stores aren't suited for transaction processing, for instance. Keystores can't really do anything other than get/set simple objects. There's nothing earth-shatteringly innovative about the way that InfiniSQL organizes and manipulates data, but the underlying architecture overcomes many of the limitations that drove adoption of many alternate database types.
PostgreSQL clients are used to perform SQL queries, so really any platform and language should be able to use InfiniSQL. They've documented the Frontend/Backend Protocol very well, so implementing it for InfiniSQL has been pretty simple. (InfiniSQL and PostgreSQL are completely separate projects.)
Summary
That's pretty much it as far as an introduction to InfiniSQL and how it was designed to be an infinitely scalable RDBMS. It's so far literally the work of a guy in his living room banging out code at all hours. Please enjoy InfiniSQL, and learn from it, and find me on the links described above if you want to talk about it! Also, please consider participating--it's still in an early state, and contributions are actively sought. It's free, open source, and has a lot of room for development efforts. People willing to alpha test this project are also really sought--if you think that InfiniSQL could solve some of your problems, please talk to me about it!
Home page: http://www.infinisql.org
Blog: http://www.infinisql.org/blog/
IRC: irc.freenode.net #infinisql
Twitter: @infinisql
Forum: https://groups.google.com/forum/#!forum/infinisql



