How the AOL.com Architecture Evolved to 99.999% Availability, 8 Million Visitors Per Day, and 200,000 Requests Per Second


This is a guest post by Dave Hagler Systems Architect at AOL.
The AOL homepages receive more than 8 million visitors per day. That’s more daily viewers than Good Morning America or the Today Show on television. Over a billion page views are served each month. AOL.com has been a major internet destination since 1996, and still has a strong following of loyal users.
The architecture for AOL.com is in it’s 5th generation. It has essentially been rebuilt from scratch 5 times over two decades. The current architecture was designed 6 years ago. Pieces have been upgraded and new components have been added along the way, but the overall design remains largely intact. The code, tools, development and deployment processes are highly tuned over 6 years of continual improvement, making the AOL.com architecture battle tested and very stable.
The engineering team is made up of developers, testers, and operations and totals around 25 people. The majority are in Dulles, Virginia with a smaller team in Dublin, Ireland.
In general the technology in use are Java, JavaServer Pages, Tomcat, Apache, CentOS, Git, Jenkins, Selenium, and jQuery. There are some other technologies which are used outside that stack, but these are the main components.
Design Principles
There are some important overarching principles which drive the architecture. First, there are redundancies for everything. Even when something goes down or is taken out for maintenance, there is still a redundancy. The requirement is for five 9’s availability which is about 5 minutes of downtime per year.
The second principle is that AOL.com should not depend on any shared infrastructure to deliver its pages. If other AOL properties or systems go down, AOL.com needs to stay up. A bit of history: At the time this architecture was developed, there was a single shared infrastructure for most AOL web properties called Big Bowl, and it was a recurring problem where one property impacted the others. As a result, the current AOL.com was specifically designed to solve this problem by isolating itself. Any dependency to AOL.com is fronted by a protection service that concentrates calls to downstream systems to a smaller set of servers. Instead of receiving requests from thousands of servers, downstream systems get calls from maybe 20 different servers. And the responses are cached to further prevent overwhelming them. In addition, external databases are replicated to give AOL.com it’s own copy, managed by its own operations team. About the only shared components are the networking and authentication services.
Another principle is that caching is used to optimize performance but is not a requirement for the system to operate at scale. The infrastructure is sized to withstand full traffic with no caching, while still ensuring enough redundancy to tolerate outages. Caches are a bonus but not necessary.
Physical Infrastructure
AOL.com is served out of 3 data centers. Two are in Northern Virginia and one in California, all are owned and operated by AOL. All 3 data centers are actively serving traffic, but each of the data centers is sized to be able to handle the entire traffic on its own. This allows taking the one data center offline for maintenance, and still having a redundant data center in case of failure.
When a request comes in, Akamai GSLB handles load balancing across data centers and directs users to the nearest one. Akamai CDN is used for static content. Once inside a data center, any further requests to services or databases will remain within that data center. User session information is kept in cookies and passed in the request, so any server can service any request with no state to keep.
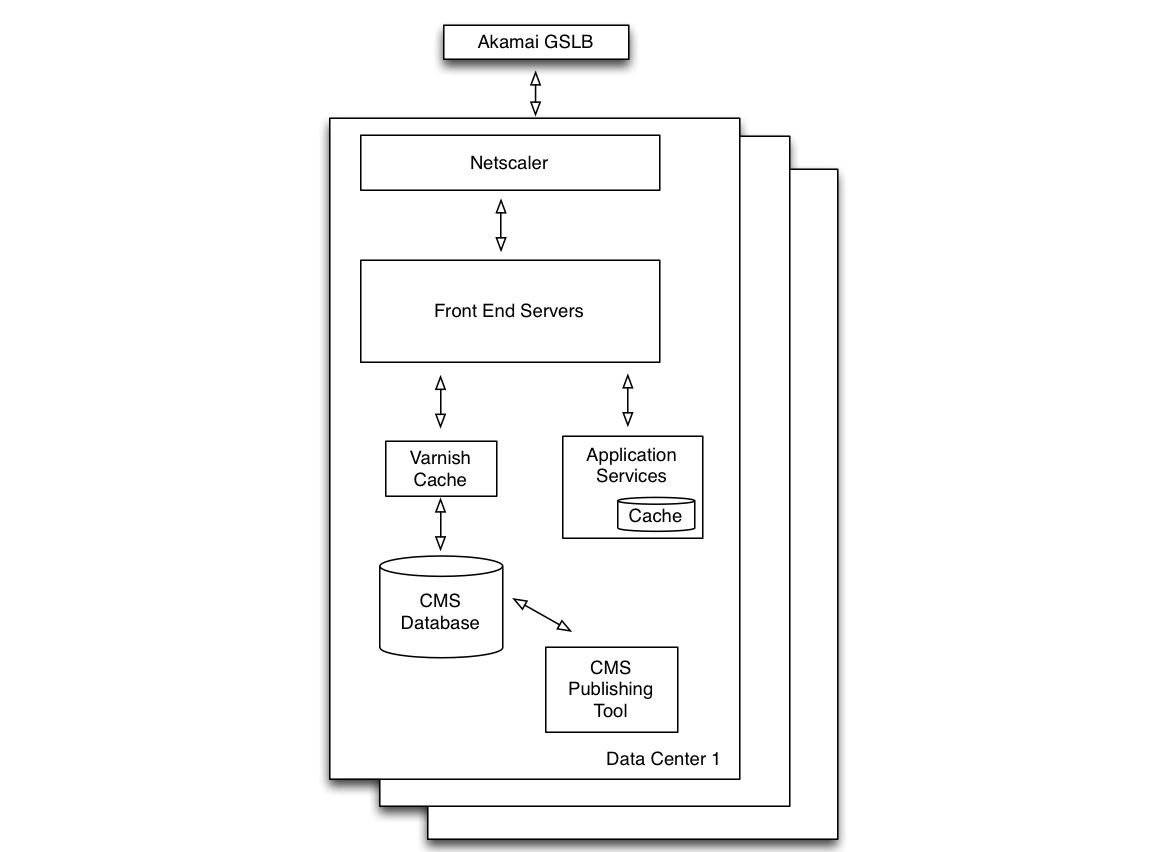
Within each data center, requests are received by a Netscaler appliance and load balanced to one of the many front end application servers. There are about 700 front end servers across all the data centers. The front ends are virtual servers and operators can quickly add capacity by spinning up additional servers as needed. Virtual hosts for the front ends are each configured with 2 virtual CPU, 4GB RAM, and 80GB disk space. Each front end server is running a single instance of Apache and Tomcat. The Apache passes through requests to its Tomcat running on localhost. Tomcat processes the bulk of the request, calling databases and services, and performing all the application logic.
Traffic
The traffic to AOL.com is surprisingly predictable, following a pattern similar to internet usage in general. A major world event will cause a spike, but otherwise the pattern is very consistent.
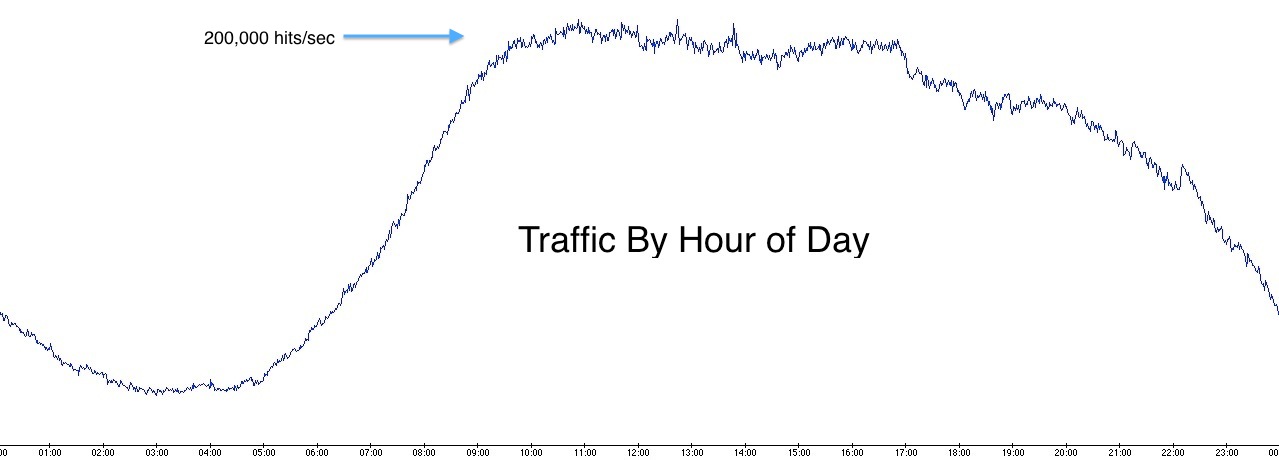
Daily traffic is lowest from 3-6 am, rises sharply until 10 am, hovers around 200,000 hits/second for 7 hours, then starts to fall after 5pm. The same cycle repeats every day.
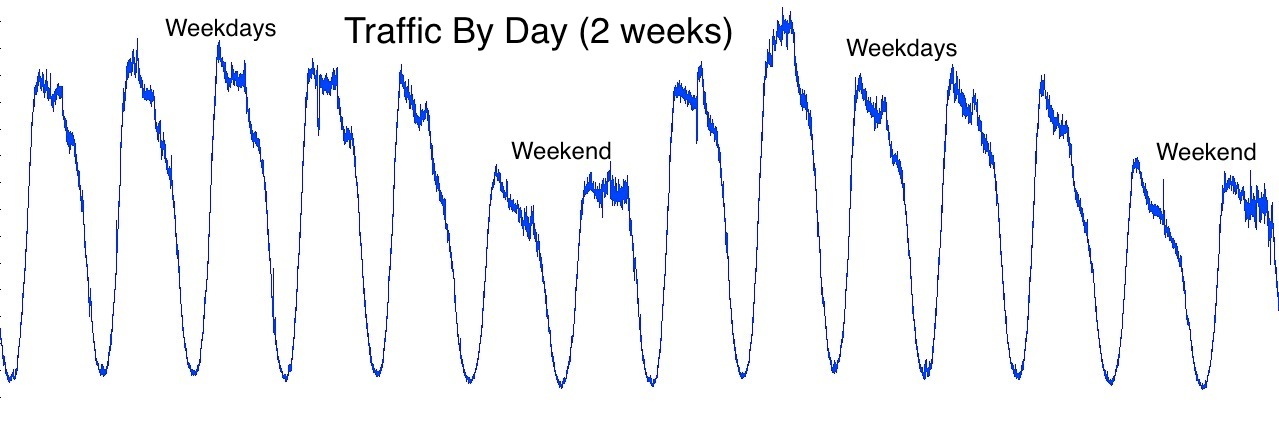
The amount of traffic to AOL.com is higher during weekdays than weekends. No particular weekday is consistently higher than other weekdays from week to week. In other words, Monday is no different than Tuesday or Friday. But weekends are always lower than weekdays.
The traffic is spread across the 2,000 front end servers in 3 data centers. Each of the 2 East Coast data centers receives about 40% of the traffic, and 20% goes to the west coast. The uneven distribution is because Akamai routes users to the nearest data center, and there are more end users in the eastern part of the United States. Also, traffic to the international sites aol.ca, aol.co.uk, aol.fr, aol.de all go the the East Coast data centers in the US.
Monitoring
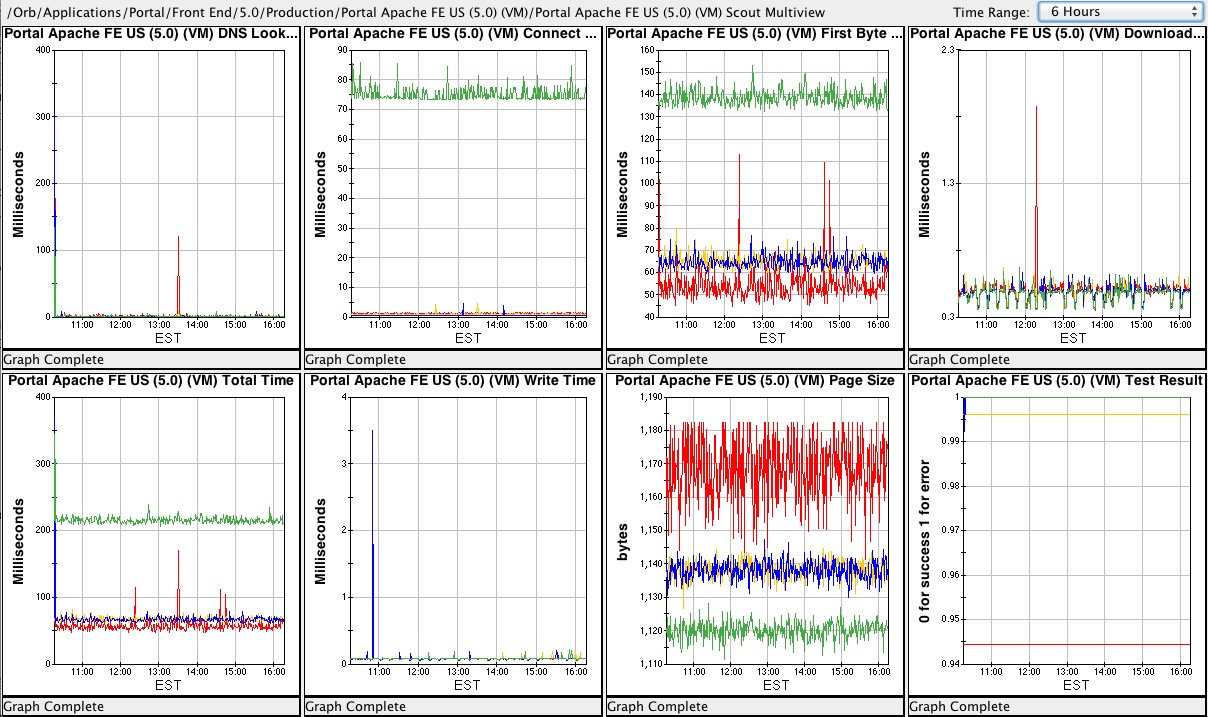
All applications running in AOL datacenters, including AOL.com, are monitored by a homegrown tool that has been developed over many years that is similar in function to Amazon’s CloudWatch. Hardware and software metrics are collected and aggregated in real time. A client application provides reports, graphing, and dashboards. Hosts, CPU’s, interfaces, network devices, file systems, web traffic, response codes, response times, application metrics, and other information is provided. Server endpoints are checked every minute and alarm when certain thresholds for availability and response time are not met.
Content Management System
Most of the content for AOL.com, and a good deal of the business logic, comes from the Content Management System. The CMS is a homegrown application that is built on the same Java/JSP technology stack. It serves many functions beyond a typical CMS. Editors use it to create the content you see on AOL.com. Developers use it to configure the application. It is also a metrics dashboard for editors to give real time data on how every piece of content on the page is performing.
The AOL homepage is more than a single page, at a single domain www.aol.com. It actually consists of dozens of separate versions of the same content, on different domains, which could have many visible or subtle differences. The CMS allows these different versions of the homepage to be programmed in one place, with content for a particular version inherited from a multiple parents in a hierarchy. The differences between versions can be as simple as different branding logos on the page, different tracking id’s, or some or all of the content can be completely different. As an example, the version of AOL.com that serves as the homepage for the US (www.aol.com) may be different from the Canadian version (aol.ca) which may be different than the mobile version (m.aol.com). There are also branded versions operated for partners such as Verizon’s mobile portal.
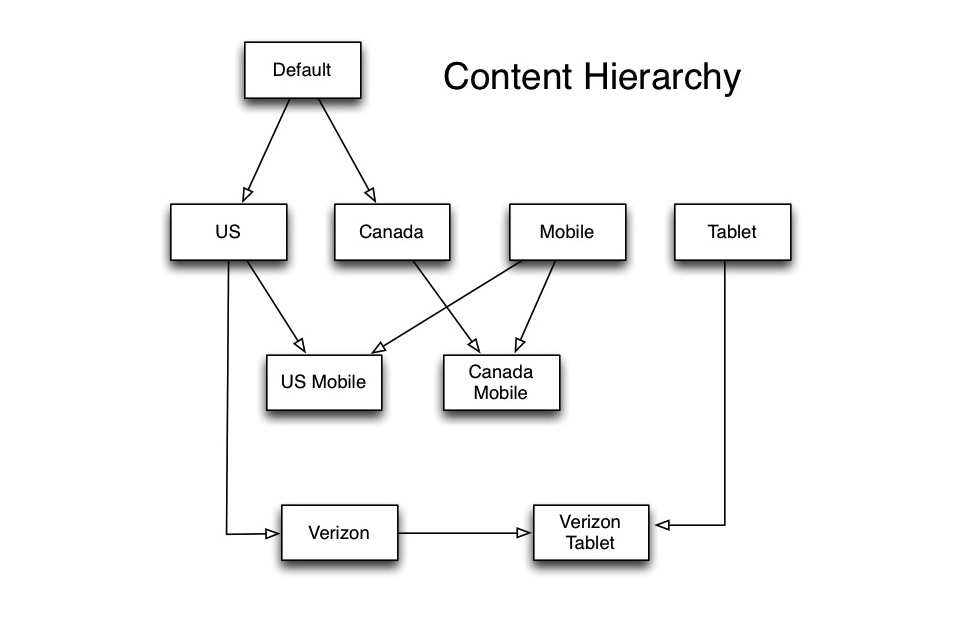
In this way, content trickles down and eliminates the need for lots of manually duplicated content. Take for example a breaking news event that is only relevant for US sites. An editor will program the breaking news in the US section, and it will trickle down to all sites inheriting from US. If for some reason the breaking news was only for the Verizon portals, an editor could program at that level and it would trickle down to the various Verizon sites.
We test every feature to see how it performs before rolling out to a wider audience. To facilitate testing, there is a multi-variant testing tool built into the CMS that allows any number of test cells to be running in parallel. We continually test different content and design elements in order to optimize the experience. A test audience, defined as a percentage of traffic, will receive a different version of the site. Users are put into a test cell at random and tracked with a browser cookie. The test could be a small visual change like a button color, it could be a different layout of content, or it could be an entirely different experience. A test usually runs for several weeks before the results are applied.
Databases
The content on AOL.com is highly dynamic, and requires a trip to the database and application of rules for every page view. In addition to the markup you see on the page, the CMS also contains many rules and conditional content. For example, if you are on an older browser you might see a Browser Upgrade banner at the top of the page. Therefore, the CMS database needs to be fast, capable of handling extreme bursts of traffic, and always available. We are running MySQL 5, and, unlike the front end servers which are virtualized, the database servers are larger, physical hosts with 16 CPU and additional disk space.
There are 30 slave replicas for the CMS database, with 10 in each datacenter. A single master sits in one of the data centers, with a backup master in the same data center on standby in case of failure. In addition to the master and slaves, there is a repeater in each data center that replicates with the master, and the repeater serves as the master for the slaves in its data center. The purpose of the repeaters is to cut down on replication traffic across data centers. There is a backup repeater in each data center in case of failure. In the case where the main master and its backup fail, one of the repeaters will be designated the new master.
Applications access the database through a HTTP interface. AOL has developed an apache module that serves as the interface to MySQL. Each database host has a web server on it with the module installed. The manages a pool of connections to its database, takes sql queries as a GET request, and returns the results in XML format. For Java applications like AOL.com, there is a Java client library that abstracts the HTTP call and XML parsing into typed objects.
There are several reasons for the HTTP database interface. First, it makes database access simpler for clients. Any application using any programming language can make HTTP calls, without MySQL client drivers or connection pooling to worry about. Second, it is also easy for scaling applications. Applications access the database through a single URL, the URL to the virtual IP address of the load balancer. When a new slave is added, client applications don’t need to add it to their configuration. Another benefit of the HTTP interface is for monitoring. Standard web server access logs and monitoring tools can give database transaction volume, query response times, and errors. The entire sql query is included in the URL as a parameter so it’s easily available in the logs. There is also an admin interface built into the apache module, making it possible to get database diagnostics from any web browser.
Caching
There are several areas in the architecture where caching is used. There are two levels of cache in the CMS. First, the CMS Java code which accesses the data makes use of in memory caching. Since every piece of content in the CMS is versioned, and nothing is ever updated rather it is a new version, data can be easily cached to reduce lookups to the database. This type of cache is at the Tomcat instance level, with each of the 700 instances keeping it’s own cache.
But the database still needs to be checked for every page load to see if there is a new revision of content. This translates into a lot of database queries, often with the same results. Since our database queries are all proxied by the HTTP interface via apache mod described earlier, we can easily cache requests using Varnish Cache. Database queries are simple HTTP GET requests with the full SQL query in the URL, so Varnish works very well to significantly reduce traffic to the database servers.
Akamai CDN is used to cache all of the static assets. In addition to static asset caching, Akamai also caches a stripped down static version of AOL.com every few minutes. This is a rarely used fallback for a disaster scenario, when all of the data centers are not reachable. Users will get the cached page directly from Akamai until the real page comes back online.
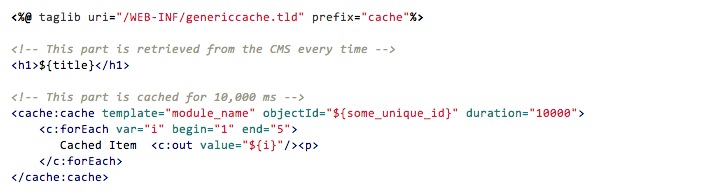
The final area of caching is in the AOL.com front end JSP code. The job of the front end is to gather lots of little pieces of content from the CMS and assemble them into HTML pages. We developed a JSP tag library which makes it possible for developers to cache any block of assembled HTML on a page. For example, to specify part of a page which is to be cached, surround it with <cache:cache> </cache:cache>.
Development Process
For major features that require coding changes, the development team loosely follows a Scrum process. Sprints are usually 3 to 4 weeks depending on business commitments. Sometimes more than one sprint is being worked on at the same time, for instance when a feature takes more than 4 weeks of development.
Many of the site changes can be accomplished just by publishing through the CMS, without a build or code deployment process. These are frequent occurrences and they are handled as an out of cycle process, with requests coming through email lists to the team. These changes are deployed throughout the day and range from a few to a dozen or more changes every day. Turnaround time on these changes are minutes to days.
The development team rotates an iPhone weekly to serve as the application on-call. The application on-call receives alerts when application level monitoring is triggered. For example, data from a downstream system may have stopped flowing. This wouldn’t cause a noticeable issue for the end user, because there are redundancies and graceful fallbacks for such a situation, but it’s a proactive alert to a problem before it can get bigger. In addition to the application on-call, the operations team has an on-call for network, host, and database issues. There are well defined escalation paths and teams for handling any situation.
Developers work in their local environment. Most use a Macbook Pro laptop with Netbeans or Eclipse. There are 6 non-production environments used during the development process. All of the environments match the same configurations as production but at a smaller scale. There are 2 Dev Integration, 4 QA, and 1 Staging environments. Multiple QA environments are necessary to support 2 sprints at the same time, as well as for production fixes if needed. Typically, only 1 or 2 QA environments are in use at any given time. There is also a separate Dev, QA, and Staging for the international versions which run a separate instance of the same codebase to serve aol.co.uk, aol.fr, and aol.de.
The QA process before new code gets installed is fairly rigorous. Many regression tests have been built up over the years, with a good deal of automated tests but also many manual tests. Selenium is used for test automation. There is a custom built screenshot tool to quickly capture what pages look like across a wide range of browser/operating system combinations. AOL has more users with older systems than the typical website, and our regression test suites includes IE7, the AOL Desktop browser, and simulating slow internet connections. We also test a wide matrix of browser/OS/device combinations. Something may look good on IE9 with Windows 7 but it’s broken on IE9 with Windows XP. It adds a lot of extra time to regression test the site across all the permutations of browsers and operating systems, but it has proven necessary over the years. Windows XP and older versions of IE pose the biggest problem. AOL.com tends to have more users with these older systems so we pay more attention to it.
A full install takes about 2 hours from start to finish, with the entire development team listening on a conference call. Installs are typically done at 6 am EST when traffic is the lowest. There is no downtime to the site or the CMS during the install. Even though most of the install steps are scripted, every step is run separately by an operator and verified along the way. The day before a production install, the entire install process and scripts are practiced in the staging environment. After backing up the databases, the various components are deployed and validated.
One challenge with updating a website is that CSS, images, and Javascript, which are delivered by the CDN, get cached in the browser. As such, a user can have a broken experience until the cached elements expire. We follow a process to eliminate this problem. First the new static content is pushed to the CDN under a new version path, making the old and new assets both available. Next, the old code running in production is configured to point to the new assets. In order for this to work, we ensure all static content is backward compatible. Once the new assets are available, the new code is deployed to the front end Tomcat servers. For each server install, the Apache is stopped, which tells the load balancer to take it out of rotation and stop sending traffic. Then the Tomcat is stopped, new code installed, Tomcat restarted, and finally Apache restarted which triggers the load balancer to start sending traffic. It generally takes 20-30 minutes to deploy the new code across all the data centers, over 2000 servers in all, using AOL’s custom developed deployment system based on RPM packages.
Looking Back and Ahead
The technology stack for AOL.com is mature and performing very well. Like any system that has been around over 6 years, we might not make the same choices if we were just starting today. Java/Tomcat/JSP has given way to Python and PHP for web applications. Apache may be outperformed by Nginx, and NoSQL databases have emerged. Many of these technologies are being used throughout other areas of AOL. It’s the classic dilemma for a successful software system. The same robust functionality which helps make the architecture so flexible and reliable today, is what makes it difficult to take advantage of new technologies.
But we have managed to make some impactful changes along the way. Just a few examples include moving from physical to virtual hosts; adding Varnish Cache; and introducing Jenkins to the build process. We are undergoing a complete rewrite of the front end HTML and CSS, in order to clean up a lot of legacy code and to facilitate a responsive design that wasn’t even a consideration just a few years ago. Our path remains to evolve the architecture, rebuild pieces when it makes sense, and adapt to the ever changing demands of our industry.



