How Disqus Went Realtime with 165K Messages Per Second and Less than .2 Seconds Latency

Here's an Update On Disqus: It's Still About Realtime, But Go Demolishes Python.
How do you add realtime functionality to a web scale application? That's what Adam Hitchcock, a Software Engineer at Disqus talks about in an excellent talk: Making DISQUS Realtime (slides).
Disqus had to take their commenting system and add realtime capabilities to it. Not something that's easy to do when at the time of the talk (2013) they had had just hit a billion unique visitors a month.
What Disqus developed is a realtime commenting system called “realertime” that was tested to handle 1.5 million concurrently connected users, 45,000 new connections per second, 165,000 messages/second, with less than .2 seconds latency end-to-end.
The nature of a commenting system is that it is IO bound and has a high fanout, that is a comment comes in and must be sent out to a lot of readers. It's a problem very similar to what Twitter must solve.
Disqus' solution was quite interesting as was the path to their solution. They tried different architectures but settled on a solution built on Python, Django, Nginx Push Stream Module, and Thoonk, all unified by a flexible pipeline architecture. In the process they we are able to substantially reduce their server count and easily handle high traffic loads.
At one point in the talk Adam asks if a pipelined architecture is a good one? For Disqus messages filtering through a series of transforms is a perfect match. And it's a very old idea. Unix System 5 has long had a Streams capability for creating flexible pipelines architectures. It's an incredibly flexible and powerful way of organizing code.
So let's see how Disqus evolved their realtime commenting architecture and created something both old and new in the process...
Stats
-
Current:
-
3 million websites use Disqus as their commenting system
-
Half a billion people engaged in conversations every month
-
20 million comments every month
-
-
As of ~March 2013:
-
A billion unique visitors a month.
-
18 Engineers
-
Platform
Python (Disqus is a service and is written in Python and other languages)
Django
Thoonk Redis Queue - a queue library on top of redis.
Nginx Push Stream Module - A pure stream http push technology for your Nginx setup. Comet made easy and really scalable.
Gevent - coroutine-based Python networking library that uses greenlet to provide a high-level synchronous API on top of the libev event loop.
Long Polling using EventSource (in the browser)
Sentry - a realtime, platform-agnostic error logging and aggregation platform.
Scales - tracks server state and statistics, allowing you to see what your server is doing.
Runs on raw metal, not EC2.
Architecture
-
Motivation for realtime:
-
Engagement. Realtime distribution of comments encourages users to stay on a page longer. More people comment after realtime than they did before.
-
Sell/trade data. Create a fire-hose product out of the global comment stream.
-
-
Old realtime system:
-
The Disqus app, written in Django, would post to memcache on many keys: forum:id, thread:id, user:id, post:id. Maybe someone in the future might find it interesting. Since pub/sub is cheap to do, this allows for later innovation.
-
Front-end client would poll the memcache key every couple of seconds.
-
Client would display any new comments.
-
Problem: did not scale at all. Only 10% of the network could use the product at one time.
-
-
First solution approach:
-
New Posts -> Disqus -> redis pub/sub -> Flask (a web framework) Front End cluster <- HAProxy <- clients.
-
Clients would connect to HAProxy. HAProxy was used to handle millions of connections.
-
Problem: rapidly ran out of CPU on flask machines because they were doing redundant work. If two subscribers were listening to the same thread the message would be formatted twice.
-
-
Second approach:
-
A backend server was created to do the dedupe formatting work.
-
So the new flow: New Posts -> Disqus -> redis queue -> “python glue” Gevent formatting server (2 servers for redundancy) -> redis pub/sub (6 servers) -> Flask FE (front end) Cluster (14 big servers) <- HA Proxy (5 servers) <- clients
-
This worked well. Except as it scaled out it was using more and more servers, especially the Flask cluster. The redis pub/sub cluster was also growing quickly.
-
Third and winning approach:
-
Uses a pipelined architecture where messages pass from queue to queue while being acted upon by filters.
-
Switched to nginx + push stream module. This replaced redis pub/sub, flask servers and the HAProxy cluster.
-
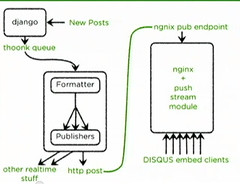
New flow looks like: New Posts -> Disqus -> redis queue -> “python glue” Gevent formatting server (2 servers) -> http post -> nginx pub endpoint -> nginx + push stream module (5 servers) <- clients
-
Only the pub/sub of redis was being used and the nginx push stream module supported the same functionality.
-
5 push stream servers were required because of network memory limitations in the kernel. It’s a socket allocation problem, that is having lots of sockets open. Otherwise could run on 3 servers, including redundancy.
-
The Disqus part of the flow is a Django web app that uses post_save and post_delete hooks to put stuff onto a thoonk queue. These hooks are very useful for generating notifications for realtime data.
-
Thoonk is a queue library on top of redis.
-
They already had thoonk so used it instead of spinning up a HA cluster of RabbitMQ machines. Ended up really liking it.
-
Thoonk is Implemented as a state machine so it’s easy to see what jobs are claimed or not claimed, etc. Makes cleanup after a failure easy.
-
Since the queue is stored in redis using zsets, range queries can be performed on the queue. Useful to implement end-to-end acks because you can ask which messages have been processed yet, for example, and take appropriate action.
-
-
The python glue program.
-
Listens to the thoonk queue.
-
Performs all of the formatting and computation for clients. Includes cleaning and formatting data.
-
Originally did formatting in the flask cluster, but that took too much CPU.
-
Found that gzipping individual messages was not a win because there wasn’t enough redundancy in a message to generate sufficient savings from compression.
-
Gevent runs really fast for an IO bound system like this.
-
A watchdog makes sure a greenlet was always running, which is to say work is always being performed. A greenlet is micro-thread with no implicit scheduling: coroutines.
-
A monitor watches for lots of failures and then raises an alert when observed.
-
-
Pipelined architectures.
-
The python glue program is structured as a data pipeline, there are stages the data must go through: parsing, computation, publish it to another place. These are run in a greenlet.
-
Mixins were used to implement stage functionality: JSONParserMixin, AnnomizeDataMixin, SuperSecureEncryptDataMixin, HTTPPublisher, FilePublisher.
-
The idea is to compose pipelines. A message would come off of thoonk and run through a pipeline: JSONAnnonHTTPPipeline, JSONSecureHTTPPipeline, JSONAnnonFilePipeline.
-
Pipelines can share most of their functionality, yet still be specialized. Great when bringing up a new feature you can make a new pipeline stage, make a new pipeline, and have the old pipeline run side by side with the new pipeline. Old and new features happily coexist.
-
Tests are also composable within a pipeline. To run tests just insert a filter/module/mixin in the pipeline and the tests will get run.
-
Easy to reason about. Each mixin is easy to understand. It does one thing. New engineers on a project have a much easier time groking a system designed this way.
-
-
Nginx Push Stream
-
Handles pub/sub aspect and web serving aspect of a system. And does both well.
-
Recently hit two million concurrent users with 5 servers. Hit peaks of ~950K subscribers per machine and 40 MBytes/second per machine with the CPU usage under 15%.
-
Continually write data to sockets to test of a socket is still open. If not it is cleaned up to make room for the next connection.
-
Configuration is a publish endpoint and a subscribe endpoint and how to map data between them.
-
Good monitoring built-in and accessible over a push stream status endpoint.
-
A memory leak in the module requires rolling restarts throughout the day, especially when there are a couple of hundred thousand concurrent connections per process. The browser will know quickly when it has been disconnected so it will restart and reconnect.
-
-
Long(er) Polling
-
This is on the browser/JavaScript client side of things.
-
Currently using WebSockets because they are fast, but are moving to EventSource because it’s built into the browser and the browser handles everything. Just register for the message type and give it a callback handler.
-
Testing
Darktime testing. Disqus is installed on millions of websites so need test with millions of concurrent connections. Use existing network to load test rather than create a faux setup in EC2.
Instrumented clients to say only 10% of users or exactly this website should flow through the new system, for example.
Darkesttime. Something important in the world is happening and a couple of websites are getting mega traffic. So they took all traffic and sent it through a single pub/sub key in the system. This helped identify a lot of hot spots in the code.
Measure
Measure all the things. In a pipelined system you just measure input and output of every stage so you can reconcile your data with other systems like HAProxy. Without measurement data there’s no way to drill down and find out who is wrong.
Express metrics as +1 and -1 if you can. (I didn’t really understand this one)
Sentry helps find where problems are in code.
Measurements make it easy to create pretty graphs.
When the Pope was selected and the white smoke was seen traffic peaked 245 MB per second, 6 TB of data was transferred that day, and peak CPU was 12%.
Lessons Learned
Do work once. In a large fanout architecture, do work in one place and then send it out to all the consumers. Don’t repeat work for each consumer.
The code most likely to fail is your code. You’re smart, but really smart people wrote redis and other products, so be concerned more about your code than other parts of the system.
End-to-end acks are good, but expensive. Necessary for customers who want 100% delivery. Couldn’t do it for every front-end user.
Greenlets are free. Use them. They make code much easier to read.
Publish is free. Publish to all channels. They were able to make a great realtime map of traffic without any prior planning because messages were published over all channels.
Sometimes there are big wins. Discovering the Nginx Push Stream module simplified huge chunks of their system and reduced server count.
Understand use cases when load testing so you can really test your system.
Test with real traffic. This is a much easier approach as your system gets larger and generating synthetic loads would be a huge project in itself.
Use Python. They really like Python and Django, though some of the backend stuff is now being written in Go.
Increasing server counts in response to scale is a sign your architecture may need some tuning. Take a look at one you can do change your architecture and use resources more efficiently.
Use off the shelf technologies. Don’t feel like you have to build everything from scratch. Leverage code so you can keep your team small.
Related Articles
Scaling DISQUS To 75 Million Comments And 17,000 RPS (2010)
Disqus’ nginx-push-stream-module configuration for >1MM concurrent subscribers.
Making DISQUS Realtime (slides) by Adam Hitchcock, Software Engineer, ~March 2013
Scaling Django to 8 Billion Page Views by Matt Robenolt, Operations Lead, Sep 2013
HTTP for Great Good (slides) by Matt Robenolt, ~Oct 2013
Google On Latency Tolerant Systems: Making A Predictable Whole Out Of Unpredictable Parts
C1MM and NGINX (slides) by John Watson - updates on the Disqus architecture.



