The Easy Way of Building a Growing Startup Architecture Using HAProxy, PHP, Redis and MySQL to Handle 1 Billion Requests a Week

This Case Study is a guest post written by Antoni Orfin, Co-Founder and Software Architect at Octivi.
In the post I'll show you the way we developed quite simple architecture based on HAProxy, PHP, Redis and MySQL that seamlessly handles approx 1 billion requests every week. There’ll be also a note of the possible ways of further scaling it out and pointed uncommon patterns, that are specific for this project.
Stats:
-
Servers:
-
3x application nodes
-
2x MySQL + 1x for backup
-
2x Redis
-
-
Application:
-
Application handles 1,000,000,000 requests every week
-
Single Symfony2 instance up to 700 req/s (at average workday - 550 req/s)
-
Average response time - 30 milliseconds
-
Varnish - more than 12,000 req/s (achieved during stress test)
-
-
Data store:
-
Redis - 160,000,000 records, 100 GB of data (our primary data store!),
-
MySQL - 300,000,000 records - 300 GB (third cache layer)
-
Platform:

-
Monitoring:
-
Icinga
-
Collectd
-
-
Application:
-
HAProxy with Keepalived
-
Varnish
-
PHP (PHP-FPM) with Symfony2 Framework
-
-
Data store:
-
MySQL (master-master) with HAProxy load balancing
-
Redis (master-slave)
-
The background
Almost a year ago, our friends came to our office with a demanding problem. They’re running a fast growing e-commerce startup and at the time they wanted to expand to international.
As they were still a startup-type company, proposed solution had to be cost-effective to not run out of money on next servers. Legacy system has been built using a standard LAMP stack and they already have had a strong team of PHP developers. Introduction of the new technologies had to be smart to not over-complex the architecture and to let them to further maintain the platform with their current staff.
System architecture had to be designed in the scalable way to fulfill their plans of expanding to the next markets. So we had came and inspected their infrastructure...


The previous system had been designed in a monolithic way. Under the hood there were some separate PHP-based web applications (the startup has many so-called frontend websites). Most of them were using single database, they shared some common code that handled business logic.
Further maintenance of such applications could be a nightmare. As some of the code had to be duplicated, making changes in one website would lead to making business logic inconsistent - they always had to make the same changes in all of the web applications.
Also it was a problem from the project management point of view - who would be responsible for "that" part of code which is spread across multiple codebases?
Following this observations, our first step was to extract the core business-critical functionalities into a separate Service (which is a scope of this article). It's a pattern of Service Oriented Architecture. Think "separation of concerns" principle but systems-wide. The Service is keeping a logic of one, specific higher-level business functionality. To give you a real-life example - Service can be a search engine, sales system etc.
Frontend websites are communicating with a Service through a REST API. Responses are based on a JSON format. We've chosen it for simplicity as opposite to SOAP which is always a harsh for developers (no one likes parsing XMLs… ;-) )
Extracted service doesn't handle things like authentication and sessions management. It's a must that this things are handled on a higher level. Frontend website are responsible for this, as only they can identify their users. This way we made the Service simpler - in both further scaling issues and code things. Nothing bad as it has different kind of thought tasks to handle.
Benefits:
- Separate subsystem (Service) can be easily developed by a totally separate development team. Developers stay out of each other's way.
- It isn't handling user authentication and sessions, so this common scaling problem goes away.
- Business logic is kept in one place - no more redundancy in functionalities across different frontend websites.
- Easy possibility to make the Service public accessible.
Cons:
- More work for sysadmins - as Service resides on its own infrastructure that requires additional attentiom from administrators.
- Keeping backward-compatibility - under a year of maintenance, there were countless changes in a API methods. The thing is, that they mustn't break backward compatibility as it would lead to making changes in code of every frontend website - and some monkey work of deploying all websites at one time... After the year, all methods are still compatible with the first version of documentation.
Application Layer

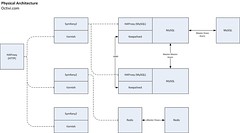
Going with a request flow, the first layer is an application. Here resides HAProxy load balancer, Varnish and Symfony2 web application.
Requests from frontend websites firstly hit HAProxy which then distributes them to the application nodes.
Application node configuration
Xeon E5-1620@3.60GHz, 64GB RAM, SATA
Varnish
Apache2
PHP 5.4.X running as PHP-FPM, with APC bytecode cache
We’ve got three of such application servers. It’s a N+1 redundancy in an active-active mode - “backup” server is actively handling requests.
Keeping separate Varnish on every node makes cache-hits much lower but that way we don’t have here SPOF (Single Point of Failure). We’ve done it that way to keep availability over performance (which is not a problem in our case).
Apache2 has been chosen, as it’s also used by a legacy frontend-website servers. Avoiding mixing many technologies makes the system easier to maintain by administrators.
Symfony2 application
The application itself is built on top of Symfony2. It’s a PHP full stack framework that provides bunch of useful components that speed-up the development process. As the decision of basing typically REST service on a complex framework may sounds weird for someone, let me clarify the reasons behind it:
Access to PHP/Symfony developers - client’s IT team consists of PHP developers. Introduction of new technology (e.g. Node.js) will result in a need of hiring new developers who will be able to further maintain the system.
Clean project structure - Symfony2 doesn’t impose full project structure, but has very sensible default one. Introduction of new developers to the project is simple as the code looks familiar for them.
Ready-made components - following DRY concept... no one wants to reinvent the wheel, so we didn’t. We’re extensively using Symfony2 Console Component which is a nice framework for making CLI commands, tools for profiling the application (debug toolbars), loggers etc.
Before choosing to go into it, we’ve made performance tests to be sure that it’d be able to handle planned traffic volumes. We’ve developed proof of concept and ran JMeter over it. The results were quite impressive - 700 req/s with response times up to 50ms. It gave us a confirmation that it’d be possible to use such complex framework for this kind of project.
Application profiling & monitoring
We’re using Symfony2 tools to monitor the application. There’s a nice profiler component that we use to collect execution times of a particular methods, especially the ones related with communication with 3rd party webservices. That way we can spot potential weak points and the most time-consuming parts of application.
Verbose logging is also a must. For that we’re using PHP Monolog library which allows us to make nicely formatted log-lines, totally understandable by developers and sys-admins. One must always remember to add as much details as possible, we found it that the more verbose, the better. We’re using different log levels:
Debug - something is about to happen - e.g. request information before the call to an external webservice; something has just happened - response from the API call
Error - something went wrong but the request flow hasn’t been stopped (e.g. error response from 3rd party API).
Critical - oops… the application has just crashed :-)
So in production environment, you can see traces like Error and under it - Critical. In the development/test environment there are also Debug information logged.
We’ve also divided our logs into separate files (in Monolog library they’re called “channels”). There’s a main log file, where’re logged all application-wide errors and short logs from the specific channels. We keep verbose logs from the channels in their separate files.
Scalability
Scaling application’s layer of the platform is not a tough job. HAProxy performance won’t be exhausted for a long time, the only thing we’re considering is to make them redundant to avoid SPoF.
So the current pattern is just to add next application nodes.
Data Layer
We’re using Redis and MySQL for storing all of the data. MySQL is mainly used as a third-tier cache layer while Redis is our primary data store.
Redis
When designing the system, we’re thinking about choosing the right database that could handle planned requirements:
Not loosing performance when keeping high volume of data (~250,000,000 records)
Mostly simple GETs based on specific resource ID (no lookups or complex SELECTs)
Possibility to retrieve big number of resource in a single request to minimize latencies
After some investigation, we’ve decided to use Redis.
All operations we perform have O(1) or O(N) complexity, where N is the number of keys to retrieve. Which means, that keyspace size doesn’t affect performance.
We’re mostly using MGET commands to retrieve >100 keys at once. That allowed to omit network latency in comparison to making multiple GETs within a loop.
We currently have two Redis servers running in a master-slave replication mode. Each of them has following configuration: Xeon E5-2650v2@2.60GHz, 128GB, SSD. Memory limit is set to 100 GB...and it’s always fully consumed :-)

As the application isn’t exhausting performance limits of a single Redis server, the slave is mainly used as a backup and for keeping high-availability. If the master goes down, we can easily switch the application to use the slave. Replication is also handy when doing some maintenance tasks or migrating servers - it’s easy to make a server switch.
You maybe wonder how does it happen that our Redis is constantly at the limit of maxmemory. Most of the keys are persistent-type - about 90% of keyspace. But the rest of them is a pure cache for which we set expiration TTL. Now, the keyspace is divided into two parts: the one with TTL set (cache) and the second one without (persistent data). Thanks to possibility of setting “volatile-lru” maxmemory policy, the less recently used cache keys (only them have expire set) are constantly automatically removed.
That way we’re allowed to keep only single Redis instance that acts both as a primary store and typical cache.
Using this pattern one must always remember to monitor the amount of “expire” keys:
db.redis1:6379> info keyspace
# Keyspace
db0:keys=16XXXXXXX,expires=11XXXXXX,avg_ttl=0
When you notice that the number is dangerously close to zero, start sharding or increase memory ;-)
How are we monitoring it? There’s an Icinga check that monitors if the “expires” number reaches a critical point. We’ve also collectd with Redis graphs to visualize the ratio of “losing keys”.

After a year, I can say that we’re totally into Redis. From the beginnings of the project, it haven’t disappointed us - there weren’t any outages nor other issues.
MySQL
In addition to Redis, we’re also using traditional, MySQL database. The uncommon thing is, that we mostly use it as a third cache layer. We store in MySQL objects that weren't recently used and storing them in Redis would use too much memory, so we keep them on a hard drive. It’s no fancy technology here, but we liked to keep the stack as simple as it could be for easy maintenance.
We have 2x MySQL servers with Xeon E5-1620@3.60GHz, 64GB RAM, SSD. There’s a native, asynchronous master-master replication on them. In addition, we keep single slave node just for backups.
High Availability for MySQL
As you can see on the physical architecture diagram, on each MySQL box, also sits HAProxy and keepalived. Connections to the MySQL goes through the HAProxy.
The pattern of installing HAProxy within every DB server, result in keeping High-Availability of the stack and waive the need of adding adding next servers just for load balancers.
HAProxy runs in active-passive mode (only one of them is used at a time). The control over their availability is done by a keepalived mechanism. There’s a floating IP (VIP) under the control of keepalived. It checks for the availability of the primary load balancer node. When it has an outage, the second (passive) HAProxy node takes over the IP.
Scalability
Database is always the hardest bottleneck of an application. Currently, there weren’t needed any scaling-out operations - to this time we’re scaling vertically by moving our Redis and MySQL to bigger boxes. There’s still a space for it as e.g. Redis is running on a server with 128 GB memory - it’s possible to migrate them to nodes with 256 GB. Of course such heavy boxes also come with disadvantages in operations like snapshot or just running up the server - it’ll take much longer to start up Redis server.
After scaling-up (vertically), goes scaling-out (horizontally). Happily, we’ve prepared easy to shard structure of our data:
We’ve got 4 “heavy” types of records in Redis. They can be sharded on 4 servers based on data type. We’d avoid partitioning based on hashing in favor to dividing the data by a records type. That way we’ll be still able to run MGET which is always performed on an one type of keys.
In a MySQL, tables are structured the way, that let easy migration of some of them to the different server - also basing on the records type (tables).
After exceeding possibility of further partitioning by data types, we’ll go into hashing :-)
Lessons Learned
Don’t share your database - once, one of the frontend-websites wanted to switch their sessions handling to Redis. So they’ve connected to our one. That resulted in a exhaustion of the Redis cache-space and denied our application to save next cache keys. All the cache has been started to be stored only on a MySQL server which resulted in a substantial overhead for it.
Make verbose logs - without much information in log-lines you won’t be able to quickly debug where was the problem. In one case, because of lack of single information, we couldn’t find what caused the issue and had to wait for its another occurrence (after adding to logs that missed data).
Using complex framework doesn’t automatically mean “slowing down the website” - some were much surprised that using full-stack framework let to handle such amount of requests per second. It’s all about smart-using of tools you have - you can make it run slow even in Node.js :-) Choose a technology which provides good development environment, no one wants to bother with unfriendly tools (lowering devops morale!).
Who’s behind the application
Platform was designed by Poland based software house Octivi. We specialize in building scalable architectures focused on high performance and availability. We’d also like to thank for great cooperation with an IT department from a client-side!
Related articles
Handling 1 Billion requests a week with Symfony2 - our overview of the whole application
Push it to the limits - Symfony2 for High Performance needs - details of the Software Architecture with Symfony2 features described



