Architecting Backend for a Social Product

This is aimed towards taking you through key architectural decisions which will make a social application a true next generation social product. The proposed changes addresses following attributes; a) availability b) reliability c) scalability d) performance and flexibility towards extensions (not modifications)
Goals
a) Ensuring that user’s content is easily discoverable and is available always.
b) Ensuring that the content pushed is relevant not only semantically but also from user’s device perspective.
c) Ensuring that the real time updates are generated, pushed and analyzed.
d) Eye towards saving user’s resources as much as possible.
e) Irrespective of server load, user’s experience should remain intact.
f) Ensuring overall application security
In summary we want to deal with an amazing challenge, where we must deal with a mega sea of ever expanding user generated contents, increasing number of users, and a constant stream of new items, all while ensuring an excellent performance. Considering the above challenge it is imperative that we must study certain key architectural elements which will influence the over system design. Here are the few key decisions & analysis.
Data Storage
Storage of data and data modelling is one of the key decisions to be made. A social product is expected to handle multiple types of data and hence it is critical that we analyze and understand the data thoroughly before choosing a model and storage for each type.
The first step is to identify which are the most frequently queried data and which are the ones which are not so frequently required (archived data for analysis). For data which are expected to be queried at a high frequency needs to be in a place where it is always available, faster to read and write and horizontally scalable. Right now we are using MySQL for all our use cases, even though our use cases do not mandate use of RDBMS based system. As our data grows, our reads and writes will become a bottleneck to our application’s performance. We should be ready for anything in the order of billions of queries per seconds.
Let us classify our data:
a) master data or static form of data like user profile
b) semantic data
c) user generated content
d) session data
It is really difficult to for us to find a data store which is highly performant for all these types of data. So we will be required to choose specific data store for each ones.
Static Data: For static data it is best if we choose a document based storage, where both key and value is queryable. We can opt for well established document based store like MongoDB here. The biggest advantage of choosing MongoDB is the fact that it provides ACID properties at the document level.
It can be scaled within and across multiple distributed data centers easily. It will allow us to maintain redundancy easily using replica sets and hence addresses our availability concern.
Sharding is one other big factor to be considered, which is essential to ensure scale & speed. Fortunately MongoDB support sharding transparently.
Connected or Relational Data (Core Data): Major part of our data will be connected in nature, for example, A is friend of B and C is friend of both A and B. Such data being highly semantic data is best suited to be modeled as graphs. We should store such data in a graph DB like Neo4j. Advantages are obvious; it will allow us to store all the connections of the node along with the node itself, thus saving the additional step in computing the relation between connected data. The graph data model also will also help us here to capture the properties of the relationship. Property rich relationships are absolutely critical when trying to explore connected data. GraphDB supports ACID rules and automatic indexing.
Again our requirements are same in terms of availability and scalability. We can have hundreds or thousands of concurrent transactions all writing to the database at the same time and hundreds and thousands of reads. It should scale to deal with over a billion reads per second across a data set of many petabytes.
We would require a system which allows scaling of writes and reads dynamically. The other factor to consider is sharding, which is critical to scale our systems.
Neo4j already is designed to scale horizontally and has replication features to guarantee availability. But it does not support Sharding as of today. We may require some more analysis while choosing one. Other options are FlockDB, AllegroGraph and InfiniteGraph.
Binary data (UGC): We also will have to deal with huge amount of binary data associated with our users. It is not easy to deal with binary data considering their size. Like discussed above, ours being a system where demand can run quite high in seconds (spikes), scale and availability is the most critical factor to be considered when deciding where to store. We can not rely on filesystem here to store our binary data. We must think about availability and scalability. File system’s caching can be CPU bound and making it redundant will require enormous amount of bookkeeping. Instead we should rely on a system where these are already available. For example Amazon S3, which is very popular object store with guaranteed availability and is elastic in nature.
We could also consider Google Cloud Storage or Rackspace Cloud Files etc. But S3 seem to be clear winner here in terms of what if offers.
S3 already supports data partitioning. It scale S3 horizontally by continuously splitting data into partitions based on high request rates and the number of keys in a partition. But it is important to realize just storing the content is not enough, the metadata associated with these content needs to be searchable and search has to scale and be fast enough. We can also try out few new things here like automatic dimension identification from image, auto tagging based on context etc and then use those to drive keys for the images*. This is a potential IP area. We will study the indexing needs under indexing section. But for now, let us just note that we will store the content with an identifier which can be indexed somewhere else. Amazon’s S3 seems most suited for this case.
Session data
It is important to recognize and understand why we need to think about session data. Session data will help us to maintain state for our users. And this state should persist in server agnostic way to make our deployment scale. This would help us to keep our design flexible enough and hence ensure that session do not stick to a particular node or server.
We got to hold session information in a fashion where we can regenerate the user’s actual session, if user’s session terminates, we can still help user to start from a place where he left.
This is especially important in our market where connections are not that reliable and packet drops are usual. This data needs to be available across our nodes and hence the requirement of availability and scalability. To start with we can very well hold this in our MongoDB itself. Later we can think of shifting it to pure key-value store like REDIS.
Note: All recommendation and offline jobs should only run on a non serving nodes.
Indexing
Indexing is critical to our system. User can search any content and it is one of our prime use case. And to make the search performant we must take indexing very seriously. There are two things to be considered here. First is, creation of index itself and next, the indexing system itself.
To make a meaningful searchable system we must design a real time index, which is inverted and works on a window of contents generated. To start with we can write a very simple system which during the content ingestion can take care of generating inverted index based on the content. Later, as the content ingestion load increases we can simply replace it with a real time data processing engine like Apache Storm, which is a distributed, fault tolerant and highly scalable system. It can take over the generation of indexing logic.
Indexing System: Lucene is an obvious choice here due its popularity and speed; its performance is unmatched. We should go with SolrCloud. It already supports transparent sharding, replication and is read and write side fault tolerant.
Queuing & Push Notifications
Each time an event is triggered in our app, we will be required to fan out the event to his/her followers/friends in form of notifications. It is important that our system do not miss any of these signals and in event of a failure recovery of those events are of utmost importance. To make this happen we must look for a queuing solution. We can use ActiveMQ, which is the most reliable queuing software. It allows clustering for high availability and supports distributed queuing.
Push Notification is another area to focus on to send notifications to our users. Here we need to look for scale. We should be ready for billion of nps kind of scale. There are many options here, but perhaps pyapns, CommandIQ and App Booster are the most popular ones.
We would need to manage few things on our own specially to guarantee delivery of notification even if user’s device is offline. I propose we implement a dual pointer based system which maintains state of a notification and in background write to a disk. So each time a notification fails, its state is maintained and added to retry queue with a state flag. Finally when a notification is delivered, it is dequeued.
Caching strategy
System like ours where we aim to make it scale to a billion rps, intelligent caching is of utmost importance. Our design will require logic to cache at multiple layers and evict them intelligently. Let us look at a top level what and where to be cached.
Application Level Caching (Content Cache): To minimize cache misses and ensure cache is always warm with latest available data, we got to look for a cache which is never stale and is always up to data. This essentially means in all our general use cases we will never have to query our DB, hence saving lot of resources. We should also ensure that data we cache is always in a format which do not require any messaging and should be ready to render. This essentially means we will convert our online load to offline load hence saving on latency. To do this, we will have to ensure that every time a content is ingested into the system we do two things
a) The raw content is denormalized in a way which do not require any messaging at serving stage and then saved into the cache. For safety we will always set an expiry, which can be high enough.
b) The raw content is also written as-is in our data stores.
We very well can rely on REDIS for this cache, which is an in memory cache with good failure recovery. It is highly scalable and the newer versions allows transparent sharding too. And it support master-slave node configuration as well. The best part is it will allow us to persist native data structures in as-is mode, which makes it very easy to write incrementally and it is critical for us to support content feeds (fan out).
Also it is to be noted that we will require a lot of read-modify-write operations and small reads, on large content objects, to support real time fanout and REDIS is known to be best for these operations in terms of speed.
Proxy Cache: Caching at a reverse proxy level is also critical. It help reduce some load to our servers and hence maintaining latency. But to make proxy server really cache effectively it is critical to set HTTP response headers correctly. There are many choices, but popular ones are nginx and ATS.
Second Level Cache (Code Level Caching): This is a local store of entity data to improve performance of application. It helps improve performance by cuttng down on expensive DB calls, keeping the entity data local to the application. EhCache is a popular choice in this area.
Client Cache: This is the actual device or browser cache. All static items should be heavily cached as much as possible. If API responses sets proper HTTP caching headers already lot of resource related items are cached. We should ensure that it is working as expected. Other than that, we should cache as much as possible other contents either using device’s own memory or could use sqlite . All expensive objects should be cached. Example could be NSDateFormatter & NSCalendar which are slow to initialize and should be re-used as much possible. iOS Lot can be tweaked and used here, but it is beyond scope of our study here.
Content Compressions
Considering the fact that our users are primarily expected to deal with lot of images and videos which takes a sizable amount of data to download, it is essential to optimize the download size. It will improve data savings for users and perceived app performance too.
Other dimension to consider is our network, our users are primarily in non LTE networks, using either 2.5g or 3g, where bandwidth is often a concern and connections are unreliable. The data usage cost is high too. Under such circumstances intelligent compression is a critical need.
But compressing images and videos are not that straight forward and often requires deeper analysis. Images and videos we deal with can be both lossless and lossy, depending on the device quality of the user. So I propose using multiple compression techniques to deal with this situation. We can try both Intra-frame compression and inter-frame compression techniques in this situation.
But in general we can employ zpaq and fp8 for all compression needs. We can experiment with WebP too, which can be good for our market. In general we will use GZIP all throughout, all our API responses will be GZIPed always.
Content Transcoding
Considering we will be required to deal with multiple devices, with multiple OSes and screen resolutions, our content storage and processing should be device agnostic. But serving layer should be contextual and should understand and serve correct content based on user’s device capability. This makes transcoding of our images and videos essential.
Our apps should gather device capabilities in terms of memory, encodings and screen resolutions and pass this as context to our APIs. Our APIs should use this context to modify/choose content versions. Based on the device contexts we receive, we can pre-transcode content to few most requested versions.
For transcoding we can use FFMPEG which is the most reliable and highly used framework. We can modify FFMPEG where ever required to suit our needs. This too must be done at the ingestion side.
Transport Protocols
Considering our network scenario (non LTE, unreliable connections etc), it is critical to intelligently save resources wherever possible and make communication as much light as possible. I propose we use OkHttp client for all our http request which in turn uses SPDY, which is quite resilient to connection failures and recover transparently.
For all our messaging needs we should switch to MQTT, which is a lightweight machine to machine connectivity protocol.
Security
Securing our application is really important. Our overall architecture should accommodate this important attribute. Here I will only talk about the architectural changes required to support security, we will not get into implementational changes.
Here are few things we must add to our architecture:
1. All our user data must be encrypted. MongoDB and Neo4j already supports Storage Encryption. On case basis we can decide to encrypt key user information. Transport Encryption must be enabled for all DB related calls.
2. Secure Socket Layer: All calls up to our proxy server should be SSLed. Proxy server can act as SSL termination point.
3. All our api endpoints should be run on non default ports and should implement Oauth without fail.
4. All reads from DB should happen through rest endpoints always.
5. The configuration which holds password must be dealt specially. The password must be hashed and the file should be restricted to have only the application read this on startup. This allows us to control the application identity instance through file system permissions. Only the application user can read, but not write, and no one else can read. All such configuration can be packaged under keydb and restricted by pwd.
Components
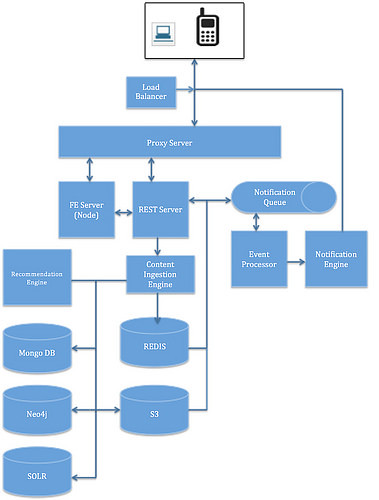
Here are the components of our architecture:
1. Load Balancer: This is the layer which determines which Proxy Server the request should be forwarded to based on a decided strategy. This layer also will help us to guarantee availability by redirecting traffic based on capacity.
2. Proxy Server: All incoming call must land here. It is our SSL termination point too. It caches HTTP request based on policy defined. FE Layer: This layer runs a node server.
3. Ingestion Engine: This component deals with all the incoming contents. It holds the policies related denormalization, transcoding, caching etc. In future all content enrichments if required can be done here.
4. REST Server: This is the layer which talks to all DBs and generates response. Its access is protected by Oauth. It could be a tomcat container with edge cache implemented.
5. Event Processor: This layer deals with all the events and is primarily responsible for the fan out feature. It reads the ActiveMQ and generates notification using notification engine.
6. Recommendation Engine: This component drives recommendation by analyzing all signals gathered from user’s activities. Based on actual signals gathered we could deploy various affinity based algorithms. We could reply on Apache Mahout to start with which already provides various algorithm interfaces
Logical View of the System:
Conclusion
This is more of a high level analysis of critical component. This proposal if needs to be implemented need not be implemented in a go, could be done in a phased manner, but if we need to scale and support real use cases, we must follow the pattern I proposed here. I did not touch any design areas. That is for the design phase and will require much deeper analysis and understanding the current state of the system.



