The Always On Architecture - Moving Beyond Legacy Disaster Recovery


Failover does not cut it anymore. You need an ALWAYS ON architecture with multiple data centers.-- Martin Van Ryswyk, VP of Engineering at DataStax
Failover, switching to a redundant or standby system when a component fails, has a long and checkered history as a way of dealing with failure. The reason is your failover mechanism becomes a single point of failure that often fails just when it's needed most. Having worked on a few telecom systems that used a failover strategy I know exactly how stressful failover events can be and how stupid you feel when your failover fails. If you have a double or triple fault in your system failover is exactly the time when it will happen.
For a long time the only real trick we had for achieving fault tolerance was to have a hot, warm, or cold standby (disk, interface, card, server, router, generator, datacenter, etc.) and failover to it when there's a problem. This old style of Disaster Recovery planning is no longer adequate or necessary.
Now, thanks to cloud infrastructures, at least at a software system level, we have an alternative: an always on architecture. Google calls this a natively multihomed architecture. You can distribute data across multiple datacenters in such away that all your datacenters are always active. Each datacenter can automatically scale capacity up and down depending on what happens to other datacenters. You know, the usual sort of cloud propaganda. Robin Schumacher makes a good case here: Long live Dear CXO – When Will What Happened to Delta Happen to You?
Recent Problems With Disaster !Recovery
Southwest had a service disruption a year ago and again was recently bit by a "once in a thousand-year event" that caused a service outage (doesn't it seem like once in 1000 year events happen a lot more lately?). The first incident was blamed on "legacy systems" that could no longer handle the increased load of a now much larger airline. The most recent problem was caused by a router partially failed so the failover mechanism didn't kick in. 2,300 flights were canceled over four days at cost of perhaps $10 million. When you do your system's engineering review do you consider partial failures? Probably not. Yet they happen and are notoriously hard to detect and deal with.
Sprint has also experienced bad backup problems:
Sprint said a fire in D.C. caused problems at Sprint's data center in Reston, Va. How a fire across the street from Sprint's switch in D.C. caused issues 20 miles away wasn't quite clear, but apparently, emergency Sprint generators in D.C. didn't kick in as they were supposed to and, as so often happens, one thing led to another.
And unless you were on Mars, you will have heard Delta recently experienced their own failover problems:
According to the flight captain of JFK-SLC this morning, a routine scheduled switch to the backup generator this morning at 2:30am caused a fire that destroyed both the backup and the primary. Firefighters took a while to extinguish the fire. Power is now back up and 400 out of the 500 servers rebooted, still waiting for the last 100 to have the whole system fully functional
Delta has come under a lot of criticism. Why was the backup generator so close to the primary that a fire could destroy both? Why is the entire worldwide system running in a single datacenter? Why don't they test more? Why don't they have full failover to a backup datacenter? Why are they more interested in cutting costs the building a reliable system? Why do they still use those old mainframes? Why does a company that earns $42 billion a year have such crappy systems? It's only 500 servers, why not convert it to a cluster already? Why does management only care about their bonuses and cutting IT costs? Isn't that what you get from years out of outsourcing IT?
There's a lot of venom, as you might expect. If you want a little background on Delta's systems then here's a good article: Delta Air Lines to Take Control of Its Data Systems. It appears that as of 2014 Delta spun in all its passenger-service and flight operations systems. They had 180 proprietary Delta technology applications controlling their ticketing, website, flight check-in, crew scheduling and more. And they spent about $250 million a year on IT.
Does the whole system need a refactoring?
Interesting comment on the technology involved in these systems from FormerRTCoverageAA:
My advice is for ALL the major airlines to each put in about 10 million dollars (20-30 airlines would put a fund together about 200-300 million) to modernize and work on the Interfaces between them, and the hotel and car rental systems, tours, and other functions that SABRE/Amadeus/Apollo/etc. interface to. This would fund a research consortium to look at the current technology, and DEFINE THE INTERFACES for the next generation system. Maybe HP and IBM and Microsoft and whoever else wants to play could put in some money too. The key for this consortium is to have the INTERFACES defined. Give the specifications to the vendors (HP, IBM, Microsoft, Google, Priceline, Hilton, Hertz, whoever) that want to build the next generation reservations system. Then let them have 1 year and all have to work to inter-operate on the specification (just like they do on the “old” specs today for things like teletype, and last seat availability).
This has worked well in the healthcare space in getting payers and providers to work together. Each potential vendor needs to plan to spend 10-50 million dollars on their proposed solution. Then, we have the inter-operability technology fair (I would make it 2 weeks to 1 month) and each vendor can pitch to each airline, car rental, hotel, tour company, Uber, etc. Let each vendor do what he wants as long as the requirements for the specifications are met. Let the best tech vendor win.
It’s far past time to update these systems. Otherwise, more heartache pain and probably government bailouts to come. Possibly even larger travel and freight interruptions. A longer term blow up could put an airline out of business. Remember Eastern? I do….
This all sounds like a great idea, but what could Delta do with its own architecture?
The Always on Architecture
Earlier this year I wrote on article on a paper from Google: High-Availability at Massive Scale: Building Google’s Data Infrastructure for Ads that explains their history with Always On. It seems appropriate. Here's the article:
The main idea of the paper is that the typical failover architecture used when moving from a single datacenter to multiple datacenters doesn’t work well in practice. What does work, where work means using fewer resources while providing high availability and consistency, is a natively multihomed architecture:
Our current approach is to build natively multihomed systems. Such systems run hot in multiple datacenters all the time, and adaptively move load between datacenters, with the ability to handle outages of any scale completely transparently. Additionally, planned datacenter outages and maintenance events are completely transparent, causing minimal disruption to the operational systems. In the past, such events required labor-intensive efforts to move operational systems from one datacenter to another
The use of “multihoming” in this context may be confusing because multihoming usually refers to a computer connected to more than one network. At Google scale perhaps it’s just as natural to talk about connecting to multiple datacenters.
Google has built several multi-homed systems to guarantee high availability (4 to 5 nines) and consistency in the presence of datacenter level outages: F1 / Spanner: Relational Database; Photon: Joining Continuous Data Streams; Mesa: Data Warehousing. The approach taken by each of these systems is discussed in the paper, as are the many challenges is building a multi-homed system: Synchronous Global State; What to Checkpoint; Repeatable Input; Exactly Once Output.
The huge constraint here is having availability and consistency. This highlights the refreshing and continued emphasis Google puts on making even these complex systems easy for programmers to use:
The simplicity of a multi-homed system is particularly valuable for users. Without multi-homing, failover, recovery, and dealing with inconsistency are all application problems. With multi-homing, these hard problems are solved by the infrastructure, so the application developer gets high availability and consistency for free and can focus instead on building their application.
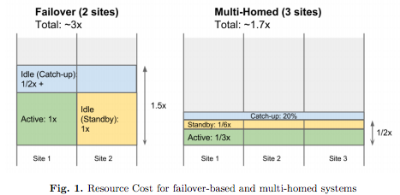
The biggest surprise in the paper was the idea that a multihomed system can actually take far fewer resources than a failover system:
In a multi-homed system deployed in three datacenters with 20% total catchup capacity, the total resource footprint is 170% of steady state. This is dramatically less than the 300% required in the failover design above
What’s Wrong With Failover?
Failover-based approaches, however, do not truly achieve high availability, and can have excessive cost due to the deployment of standby resources.
Our teams have had several bad experiences dealing with failover-based systems in the past. Since unplanned outages are rare, failover procedures were often added as an afterthought, not automated and not well tested. On multiple occasions, teams spent days recovering from an outage, bringing systems back online component by component, recovering state with ad hoc tools like custom MapReduces, and gradually tuning the system as it tried to catch up processing the backlog starting from the initial outage. These situations not only cause extended unavailability, but are also extremely stressful for the teams running complex mission-critical systems.
How do Multihomed Systems Work?
In contrast, multi-homed systems are designed to run in multiple datacenters as a core design property, so there is no on-the-side failover concept. A multi-homed system runs live in multiple datacenters all the time. Each datacenter processes work all the time, and work is dynamically shared between datacenters to balance load. When one datacenter is slow, some fraction of work automatically moves to faster datacenters. When a datacenter is completely unavailable, all its work is automatically distributed to other datacenters.
There is no failover process other than the continuous dynamic load balancing. Multi-homed systems coordinate work across datacenters using shared global state that must be updated synchronously. All critical system state is replicated so that any work can be restarted in an alternate datacenter at any point, while still guaranteeing exactly once semantics. Multi-homed systems are uniquely able to provide high availability and full consistency in the presence of datacenter level failures.
In any of our typical streaming system, the events being processed are based on user interactions, and logged by systems serving user traffic in many datacenters around the world. A log collection service gathers these logs globally and copies them to two or more specific logs datacenters. Each logs datacenter gets a complete copy of the logs, with the guarantee that all events copied to any one datacenter will (eventually) be copied to all logs datacenters. The stream processing systems run in one or more of the logs datacenters and processes all events. Output from the stream processing system is usually stored into some globally replicated system so that the output can be consumed reliably from anywhere.
In a multi-homed system, all datacenters are live and processing all the time. Deploying three datacenters is typical. In steady state, each of the three datacenters process 33% of the traffic. After a failure where one datacenter is lost, the two remaining datacenters each process 50% of the traffic.
Obviously Delta and other companies with extensive legacy systems are in a difficult position for this kind of approach. But if you consider IT something other than a cost center, and you plan to stay around for the long haul, and whole nations rely on the quality of your infrastructure, it's probably something you should consider. We have the technology.
Related Articles
- On HackerNews
- Lessons From a Decade of IT Failures
- A List of Post-mortems!
- CEO apologizes to customers; flight schedule recovery continues
- Airline On-Time Statistics and Delay Causes
- Aviation Accident Database & Synopses
- Delta outage raises backup data center, power questions
- Data Center Design | What We Can Learn From Delta Airlines’ Data Center Outage
- Comair Cancels All 1,100 Flights
- F1 And Spanner Holistically Compared
- Google Spanner's Most Surprising Revelation: NoSQL Is Out And NewSQL Is In
- Spanner - It's About Programmers Building Apps Using SQL Semantics At NoSQL Scale
- The Three Ages Of Google - Batch, Warehouse, Instant



