UGFydCAyIG9mIFRoaW5raW5nIFNlcnZlcmxlc3Mg4oCU4oCKIFBsYXRmb3JtIExldmVsIElzc3Vl c+KAig==

This is a guest repost by Ken Fromm, a 3x tech co-founder — Vivid Studios, Loomia, and Iron.io. Here's Part 1.
Job processing at scale at high concurrency across a distributed infrastructure is a complicated feat. There are many components involvement — servers and controllers to process and monitor jobs, controllers to autoscale and manage servers, controllers to distribute jobs across the set of servers, queues to buffer jobs, and whole host of other components to ensure jobs complete and/or are retried, and other critical tasks that help maintain high service levels. This section peels back the layers a bit to provide insight into important aspects within the workings of a serverless platform.
Throughput
Throughput has always been the coin of the realm in computer processing — how quickly can events, requests, and workloads be processed. In the context of a serverless architecture, I’ll break throughput down further when discussing both latency and concurrency. At the base level, however, a serverless architecture does provide a more beneficial architecture than legacy applications and large web apps when it comes to throughput because it provide for far better resource utilization.
In a post by Travis Reeder on What is Serverless Computing and Why is it Important he addresses this topic.
Cost and optimal use of resources is a huge reason to do serverless. If you are a big company with a bunch of apps/APIs/microservices, you are currently running those things 24/7 and they are using resources 100% of the time, no matter if they are in use or not. With a FaaS infrastructure, instead of running apps 24/7, you can execute functions for any number of apps on demand and share all the same resources. Theoretically, you could reduce waste (idle time) to almost nothing while still providing fast response time. For a FaaS provider, this cost savings is passed up to the end user, the developer. For an enterprise, this can reduce capex and opex big time.
Another way of looking at it is that by moving to more discrete tasks that can run in universal platform with self-contained dependencies, tasks can run anytime anywhere across a serverless architecture. This is in contrast to a set of stand alone monolithic applications whereby operations teams have to spend significant cycles arbitrating which applications to scale, when, and how. (A serverless architecture can also increase throughput of application and feature development but much has been said in this regard as it relates to microservices and functions as a service.)
A Graph of Tasks and Projects
The graph below shows a set of tasks over time for a single account on the a serverless platform. The overarching yellow line indicates all tasks for an account and the other lines represent projects within the account. The project lines should be viewed as a microservice or a specific set of application functions. A few years ago, the total set would have been built as a traditional web application and hosted as a long-running application. As you can see, however, each service or set of functions has a different workload characteristic. Managing the aggregated set at an application level is far more complex than managing at the task level within a serverless platform, not to mention the resource savings by scaling commodity task servers as opposed to much more complex application servers.
All Tasks (Application View) vs Specific Tasks (Serverless View)
Latency
The main issues arbitrating throughput in a serverless world have to do with latency and concurrency. Latency refers to the time it takes to start processing a task. Concurrency means the number of independent tasks that can be running at any one time. (There are other factors involved such as task processing times but the primary concern of developers will often lie in how fast jobs can start and/or how many events can be processed at any given time. In other words, performance optimization of individual tasks is a separate subject and engineering concern.)
The latency requirements in job processing are highly variable. Transactional events may need immediate processing whereas others can be just fine with relaxed latency requirements — on the order of seconds or minutes. While still others can run on a spectrum from minutes or hours. Much like zero-to-sixty time and horsepower in the automobile world, it’s often the case that the highest performance is not only *not* needed but that optimizing for it becomes a waste of resources and is counterproductive. When thinking about tasks and services, it’s important to define the latency needs up front as that will impact how you build the tasks and the pipeline and the requirements you expect out of your serverless platform.
One way of looking at latency is in terms of various types of processing. A rough breakdown might separate processing into three categories — real-time processing, background processing, and batch processing.
Real-time Processing (<1 sec)
Real-time processing can mean a lot of things to a lot of people — expectations can range from instantaneous to human real-time. It combines both latency to start the task and the task duration. Task start latency has generally settled on 20ms as far as a community standard. Task processing time, however, is a more fungible metric although a general guideline should probably human response expectations for a response which is typically is less than 1 second from start to finish (task latency included).
This is fast in terms of distributed cloud processing at scale especially when you factor in network latencies, container overhead, and task workload fluctuations (i.e. how many tasks may be in a queue). This type of processing requires making a key architectural choices within both a serverless platform and a serverless application. Servers need to be optimized for a particular set of tasks, containers pre-loaded, and task memory and processing limits strictly enforced. Applications need to be constructed with these constraints and critical load monitoring to maintain SLA compliance.
Note: One definition holds that only real-time processing fits the definition of serverless (i.e. task start latency <20ms) but others and I take a more expansive view of the definition defining it as an abstraction layer above the infrastructure where the emphasis is on processing of discrete self-contained stateless tasks.

Real-time Processing — Jobs Processed with Low Latency and Fast Response Rates
Background Processing (seconds and minutes)
Background processing is a general term to describe event-driven workloads that are processed outside of the main event or response loop in a time-sensitive and scalable manner. While the processing requirements may not be on the order of millisecond latency, tasks of this nature often need to be completed in seconds and minutes.
Updates to social networks, generation of pdfs, ETL processing, processing of streaming data inputs, processing of images, transcription of audio or video, and other media processing needs — all of these use cases describe where background processing is needed and where a serverless approach fits well. These are the more common use cases that I saw used for serverless computing at the beginning as it modeled the way that job and worker queues worked.
Background Processing — Jobs Processed Outside the Request/Response Loop
Batch Processing (minutes and hours)
Batch processing is not much different than what it’s always been — the processing of a large number of important, relatively singular but not necessary time-critical tasks. The difference now is that batch processing does not need to wait for particular time windows in the day (or night) or rely on a set of big and beefy servers specifically conditioned for the workloads. Batch processing can take place at any time across thousands of cores in multiple regions. The type of patterns seen with batch processing in the cloud vs legacy systems may be the same, but the method of processing and the self-contained nature of the processing units is a dramatic departure from prior renditions.
Batch Processing — Jobs Processed En Masse or on Regular Schedules
A Graph on Task Latency
The graph below represents the task latency or wait time on a serverless platform for a particular snap shot of time. Note that the vertical count axis uses a logarithmic scale. The number indicate that the majority of tasks have very little wait time. (The outliers could be delayed tasks or certain batch jobs that are deprioritized to run with less restrictive SLAs.)
Snapshot of Task Latencies (logarithmic scale)
Concurrency
With respect to concurrency, this refers to the number of similar tasks that can be executing at any one time. The thresholds can either be dictated by the serverless platform as in the case of a plan or service level threshold. Alternatively, it can be an application-based restriction put in place either because latency thresholds are not stringent (i.e. tasks can sit in queue for a bit prior to process) or because of resource restrictions and failures can occur downstream with high concurrency. In the case of a database, having too many tasks running at a point in time could exceed the connection limit.
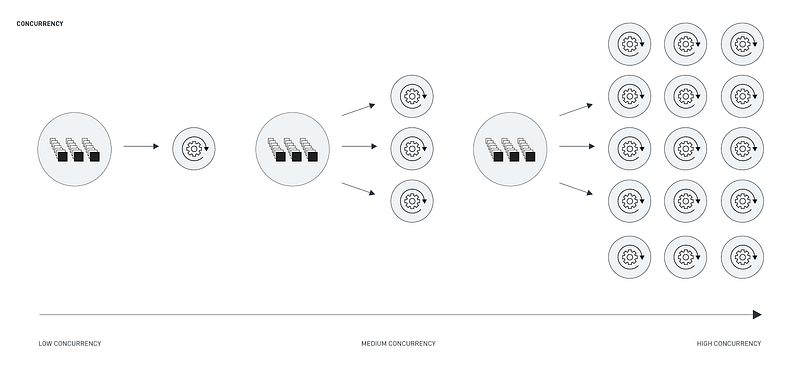
Concurrency
Container technology allows for the processing multiple tasks within a single server. Five, ten, twenty, fifty, or more tasks can run on a single server and so concurrency levels or thresholds can be exceedingly large, providing the underlying infrastructure can support an almost limitless capacity. Many serverless platforms are able to autoscale to meet varying concurrency needs (large in the day, smaller at night) or bursting at specific isolated time periods. This limits over-provisioning while still meeting concurrency SLAs.
explanation
A Graph on Task Flow
The graph below represents the task flow per minute for a specific duration and region for a particular serverless platform. The top line indicates the number of tasks started, the green line indicates tasks finished, and the red lines indicate errors and timeouts. (More on errors below.) The tasks include all tasks but if a particular processing flow allows for high currency, a serverless approach allows for an almost limitless concurrency and throughput capacity.
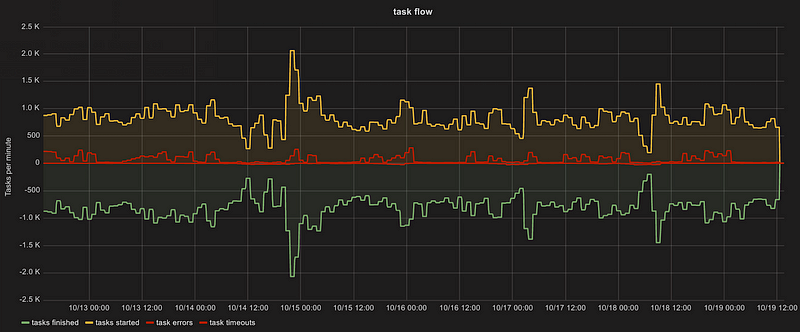
Snapshot of Task Flow Per Minute (seven day period, single region)
Memory Limits
Working at a job or task level does free you up from a number of infrastructure considerations but you never are quite free from resource constraints. Memory and processing time limits still play big factors in a serverless platform. Because tasks are likely running in containers, they are bounded by RAM restrictions (and also I/O, port, and other restrictions as may be enforced at the container or platform level).
At present, the restriction in most platforms is relatively strict and so developers need to be conscious of the memory requirements of their tasks and stay within the limits of the platform. You may have to restrict the amount of data a task can process by reducing the size of the data slices that tasks are assigned (i.e. more tasks/greater concurrency). It also might mean being conscious of how a task uses RAM, making sure to use the right data structures to avoid unnecessary allocations. Just as you would profile portions of an application to ensure optimal performance and memory handling, you’ll want to do the same within a serverless environment, although it this case it is on a task-by-task and service-by-service basis.
Note that most serverless platforms will offer local and temporary read/write data storage for use by tasks (to be erased when the task ends). Effective use of this type of storage can reduce the need to allocate large blocks of RAM. Effective use of key/value data stores is also a big part of serverless programming which we’ll go detail in a separate post.
In the future, serverless systems are likely to be able to profile tasks and make the appropriate routing to address variable memory needs, although we’re not quite there yet. Some serverless platforms, however, do offer different memory configurations so as to accommodate memory intensive tasks. Types of tasks of this nature can include image, audio and video processing, large file processing, and scientific data analysis. In this case, once the workloads are identified either via config or header data or by profiling, it will be a matter of the platform routing the tasks to higher memory processing clusters or alternatively adjusting the container/process limits on the fly.
Processing Time Limits
How long tasks take to process can have a significant impact on the throughput of a system. Even with autoscaling, a consistently high number of long running tasks will eventually consume and block other tasks from running within their desired timeframes. It is for this reason that serverless platforms will often have strict limits on how long a task can process. In the case of AWS Lambda, the maximum processing time is 300 seconds. In the case of IronWorker, the maximum is 3600 seconds although this can be increased for dedicated, private, and hybrid installations.
Some systems may be able to offer less strict processing time limits. One approach is to isolate long running tasks, route them to dedicated clusters, and provide for sufficient resources by autoscaling or provisioning to high maximum thresholds.
Processing time limits can have a significant impact on how you might architect a serverless workflow. Much like memory limits, processing time limits can influence how much data a task might be able to process. Developers may need to reduce the size of input data and possibly increase task concurrency. Tasks may be need to be broken into more more discrete functions. It may also cause developers to have to think about external resources or operations that might block — which in turn would cause tasks to timeout.
If services and functions are architected correctly, memory and processing limits should not be as restrictive as they might appear. The resource limits in most serverless platforms are generally sufficient for most processing needs (with increased limits available certain platforms). Keeping the issues mentioned in this article in mind will help. Once you get to an “aha” moment with serverless processing — typically it’s uploading code and watching it run at high concurrency — your thinking will likely easily adapt to how to structure your functions and workflows to fit this shift in processing.
A Graph on Task Duration
The graph below shows the distribution of task durations within the Iron.io platform for a particular period of time. As with the graph above, that the vertical count axis makes use a logarithmic scale which means that short-running tasks represent the vast majority of the total task volume. Each task is a stateless and ephemeral unit of work running independently from other tasks.
Snapshot of Task Durations (logarithmic scale)
Synchronous vs Asynchronous
I touched on synchronous vs asynchronous processing in part 1 of this series. Synchronous processing is where a connection is maintained with the calling process while the serverless task is executing. Once processing finished, a response is sent back to the calling process. Asynchronous processing is where the calling function sends a processing request but does not block while the processing is running.
Many of the new serverless platforms allow for synchronous processing. The advantage of synchronous processing is that a result may be obtained directly from the processing platform whereas with asynchronous processing, obtaining results has to be done as an independent effort.
Synchronous processing is most appropriate for real-time needs and for lighter weight functions i.e. processing of singular events that you want processed right away. Asynchronous processing is better for longer, more involved processing jobs (audio transcription or processing of a set of events as a small batch processing job) as well as where the application/component/function initiating the process does not need to block and wait for a result.
Note that running in a synchronous processing mode can introduce additional exception or failure issues. Because the calling process blocks, it’s paramount that the serverless platform is able to handle the scale of tasks that are sent to it. If not, then the calling applications can potentially block far beyond the expected wait durations. Additionally, the error recovery mechanisms (i.e. task retries) and metrics collection may not be as high as in an asynchronous mode. The reason being that processing tolerances for asynchronous processing are much stricter and so compromises may be made.
As a result, developers may need to build in exception handling to address blocks as well as put in logging and job processing analysis to make sure that tasks execute as they should.



